Читать в телеге. Когда-то там были посты не только от меня.
ИИ-результаты — скучные
Неплохая заметка, можно даже сказать капитанская, про то, что чатботы не генерируют оригинальных мыслей, поэтому их вывод будет по определению скучным, средненьким и поверхностным. Для областей, где вы не специалист, это сойдет, однако зарождение мыслей требует мыслительного процесса и погружения в проблему.
К сожалению, автор упустил, что для многих бизнесов скучно и предсказуемо — это как раз большой плюс :/ Но с “предсказуемо” у чатботов пока все не очень хорошо.
UPD: Рома отлично расписал еще один, более важный, упущенный момент.
Никто не против?
В компаниях с незрелыми процессами и/или так себе инженерной культурой может возникнуть такое явление как необязательное одобрение: вроде как процессы недостаточно жесткие, чтобы кто-то мог заблокировать что вам надо, но и недостаточно гибкие, чтобы вы могли просто сделать что нужно (“а вдруг?”, “надо бы эту команду спросить” и т.п.). При этом может случится так, что это одобрение где-то в помойке по приоритетам у того, кто его должен дать (иногда могут даже не снизойти до банального ответа хотя бы уровня “сорян, ща занят, посмотрю на следующей неделе” :harold:).
В некоторых случаях мне помогает переформулировка вопроса в формате “никто не против, если …?” Таким макаром, бездействие или отсутствие ответа будет одобрением. Эффект выбора по умолчанию в чистом виде. Еще можно вспомнить “проще попросить прощения, чем разрешения”.
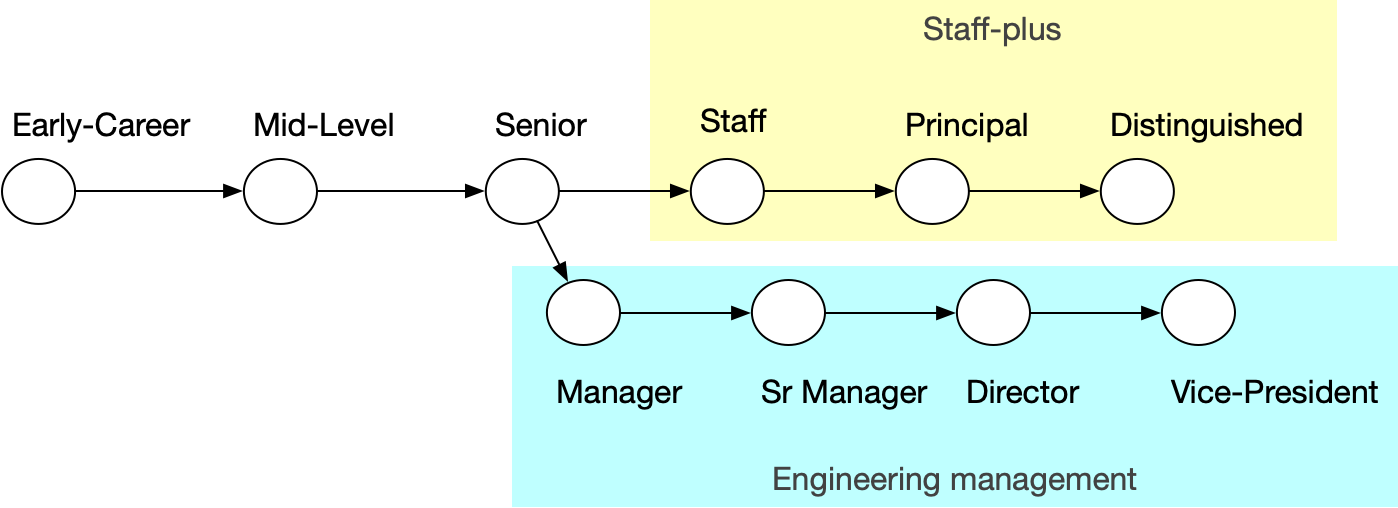
Откуда вообще взялись эти уровни Junior/Mid/Senior и т.п.?
Когда задумался над этим вопросом, первой мыслью было, что подобное разделение пошло от военных (типа старлеи и младшие офицеры): все-таки, изначально инженеры — это операторы разнообразной военной техники. Однако оказалось, что разделение на 3 уровня квалификации (новичок/младший, обычный и опытный/старший) было почти всегда, и можно даже конкретные термины senior/junior отследить сквозь века. Например, вот должности на проекте по расширению нью-йоркского метро в 1910-х и ранги клерков британского МИДа в 1822. При желании, можно дойти и до Римской Империи, где схоларии были “seniorum” и “iuniorum”, или вообще натянуть на 3 уровня ученика, подмастерья и мастера.
А вот всякие Staff и Principal — это скорее уже чисто айтишная тема, хотя подобные термины и были раньше. Например, вот требования к Principal Engineer в Англии от 1683 года, а вот вырезка из газеты 1888 года с упоминанием Staff Engineer. Судя по всему, текущий де-факто стандарт ветвящейся карьерной лестницы — это изобретение бигтеха, когда надо как-то повышать специалистов, но при этом не нагружать их управлением людьми.
{kind=link}
Разумеется, все эти лычки — очень условные. Даже если какая-то формализация требований и есть в компании, то всегда найдется повод не повысить именно вас. Миддл из одной компании может знать больше, чем сеньор из другой, а джун из третьей может получать больше их обоих.
Все это словоблудие было лишь для того, чтобы понтануться, что я теперь Staff Engineer:)
CRIU
CRIU — Checkpoint/Restore In Userspace — утилита для сохранения и восстановления состояния запущенного приложения/контейнера, разработанная “by various mad Russians”. Что-то вроде управляемой гибернации, но только в пользовательском пространстве.
Киллер-сценарий — сохранение состояния приложения и восстановление его на другой под в кластере, со всем контекстом — при благоприятных условиях, это значительно снижает потребление ресурсов (не надо контекст с нуля восстанавливать) и время простоя (не надо долго ждать, пока поднимется новый под).
Попробовать самостоятельно можно по этому туториалу.
Пустые коммиты в git
Гит многое позволяет делать, и одна из таких вещей — пустые коммиты без изменений. На первый взгляд довольно бесполезная штука: исторически это был флаг для интеграции с SCM.
С этой возможностью я познакомился на одной из старых работ. На пулл-реквесте не стриггерилась CI, и тимлид мне тогда посоветовал просто запушить пустой коммит — мол, это проще, чем найти интеграцию в дженкинсе и перезапустить ее (еще и не факт что у меня к ней доступ был). И подобный совет я слышал как минимум от трех лидов с разных работ, что многое говорит о зрелости подобных интеграций:) Впрочем, когда у GitHub инцидент почти каждые пару дней, да и он полным ходом превращается в MicroSlop™, не так уж это и дико звучит.
А недавно пустой коммит мне пригодился, чтобы обойти CI-проверку, которую я же и написал — мне было лень писать код для обработки особого случая :)
Не сроки зависят от оценок, а оценки от сроков
Хорошая статья “на подумать” про то, что оценки часто тащат за собой политику и лучше сразу ее учитывать. Не могу сказать, что на 100% со всем согласен, но уж слишком часто сам оказывался в ситуациях, когда использовались очень рандомные эвристики для оценок (“заложим риски”), а то и вовсе дедлайн известен и оценка состоит в том, чтобы понять, что можно за это время сделать. Так-то озвучены хорошие мысли: надо фокусироваться на решении проблемы, а не на оценке конкретного решения, надо больше проговаривать/фокусироваться на неопределенностях/рисках, и что важность/критичность задачи тоже влияет на оценку. И вообще, надо совместно с бизнесом продуктовые задачи решать.
Сравнение всяких технологий
Ламповый сайтик со набором всяких сравнений: операционные системы, окружения рабочего стола, браузеры, мессенджеры (причем более объективно, чем, например тут), клоны экселя и т.п.
Для важных переговоров™, как говорится.
Но особенно мне душу погрела статья про исчезновение маленьких телефонов.
Влияние ИИ на выработку навыков
А вот и статья от Anthropic подъехала на тему выработки навыков во время выполнения заданий.
Выделю две цитаты:
We found that using AI assistance led to a statistically significant decrease in mastery. On a quiz that covered concepts they’d used just a few minutes before, participants in the AI group scored 17% lower than those who coded by hand, or the equivalent of nearly two letter grades. Using AI sped up the task slightly, but this didn’t reach the threshold of statistical significance.
Managers should think intentionally about how to deploy AI tools at scale, and consider systems or intentional design choices that ensure engineers continue to learn as they work—and are thus able to exercise meaningful oversight over the systems they build.
В целом рекомендую к прочтению.
Примечательно, что в твиттере мнения полярные: от «duh, я же говорил» до «вы просто не умеете их правильно готовить». Еще некоторые пытаются высказать, что у сеньоров все по-другому (как будто им учиться не надо).
Впечатления о Ruby
С этим языком я мимолетно сталкивался и раньше — например, Puppet и его модули были написаны на Ruby; язык шаблонов Liquid, который используется в Jekyll, имеет схожий с ним синтакс; недавно локально запускал Discourse, который на рельсах написан.
У меня было о нем впечатление, что это просто такой “японский питон”, который выстрелил после Ruby On Rails, а сейчас уже движется тупо по инерции, ведь для чего-то нового рельсы вряд ли будет наверху списка.
Но вот для сайтика захотел написать проверку, что правильно id телеграммовских сообщений проставил для комментов, и решил, что раз есть готовое окружение под Jekyll с Ruby, то можно и этот скрипт на Ruby написать.
ChatGPT выдал какую-то полную дичь с кучей бойлерплейта. Потаскал оттуда полезные вызовы, но в целом написал сам.
Язык… своеобразный. Самые отталкивающие моменты:
- необходимость закрывающих
end(да и в целом лишние церемонии); - очень непонятные ошибки (уровня “ты где-то end забыл” на последней строке, с нулем гипотез где);
- много лишнего/вещей о которых надо помнить:
unless, когда естьifиnot, странности синтаксиса (вроде того, что в хэш-таблицах по умолчанию будут символы, а не строки; странные правила дляreturnили разрешение вещей типаsum sum(3, 4), 5). Добило меня, что если написать переменную с заглавной буквы, то это будет константа с глобальной видимостью (а по умолчанию в контексте функции ничего извне не видно).
Есть и хорошие идеи (например, ? на конце у методов, возвращающих bool и ! у методов, меняющих содержимое коллекции на месте), но в целом я не ощутил, что у языка есть какие-то киллер-фичи.
Однопальцевый зум
В большинстве приложений карт (я проверил Google Maps, Яндекс и Organic Maps) есть еще один вариант для масштабирования, кроме привычного двухпальцевого метода и двойного нажатия — двойное нажатие + оттягивание вверх/вниз. Есть даже исследование на сумасшедшей выборке из 12 человек, что этот метод на 47% эффективнее, когда вы держите телефон одной рукой.
{kind=link}