Читать в телеге. Когда-то там были посты не только от меня.
Suspend функции в Scala
В продолжение темы об излишних переусложнениях — на форуме Scala обсуждают предложение о добавлении корутин в стиле Kotlin. Со всеми недостатками двухцветных функций. Рекомендую почитать критику от де Гуза (автора ZIO) и сдержанный ответ Одерски (автора языка). Вкратце, suspend не нужОн, если зеленые потоки есть из коробки, и они планируются в рамках проекта Loom. А в Scala Одерски видит перспективы в более мощной типизации и в capabilities.
Context receivers
В рабочем проекте попробовал добавленные недавно context receivers. Вкратце, это очередной сахар, который позволяет требовать, чтобы функция вызывалась в контексте, содержащем какой-то класс как this:
context(Logger, DBConnection, Request)
fun someFunc() {
log(select(request.param))
}
Под капотом компилятор генерирует дополнительные параметры для вызова функции.
В текущей версии (1.6.21) все очень сыро — я споткнулся об пару багов компилятора и пару ошибок во время исполнения в довольно простых случаях. Для прода это точно не готово (я использовал в тестах). Могут получиться уродские лямбды:
suspend fun someFun(
block: suspend context(Logger, DBConnection) Request.(Param) -> Unit
)
Компилятор не всегда понимает, из какого контекста метод (и я натыкался на случаи, когда ему не удавалось это объяснить). Как и с suspend, функции приобретают “цвет”. У this непонятный тип — вроде объединение, но явно это не получить. Наконец, форматирование съезжает:) Больше критики можно почитать тут, похвалу — тут, а больше вариантов применения — тут.
Без сахара подобные задачи можно решать созданием одного класса Context и вызова функций с дополнительным параметром(ами) или через receiver: fun Context.someFunc(). Была бы поддержка типов-объединений, то тогда это было бы гораздо более читаемо (особенно с typealias). Ну а так вообще это все ради того, чтобы неявно передавать аргумент в функцию. И подобную проблему уже давно решили с помощью имплиситов в Scala. В общем, мне кажется, что начинается излишнее переусложнение, которое еще и хреново реализовано.
Разделение рабочего и личного на ноуте
Весьма скоро после перехода на удаленку рабочие задачи и личные почти полностью стали выполнятся на одном компьютере.
Сначала я делил их путем создания второго пользователя. Но это оказалось не очень удобно — надо было переключаться, ради какой-то мелочи это было делать лень. Кроме того, некоторые вещи в личном и рабочем пересекались. Например, я городил какие-то костыли с правами, чтобы Dropbox считал двух пользователей за одного.
Потом я пробовал разделить устройства — держал древний домашний стационарник в спящем режиме и включал при необходимости. Но много работать на компе, которому недавно исполнилось 10 лет — так себе удовольствие.
Сейчас я разделяю два пространства попроще — просто два рабочих стола (виртуальных) для смены контекста, и выделенный браузер для чисто рабочих задач. И еще одно место, где требуется разделение — git. Там настроено два профиля под разные директории:
$ cat ~/.gitconfig
[includeIf "gitdir:/home/ov7a/github/**"]
path = ~/.gitconfig.personal
[includeIf "gitdir:/home/ov7a/work/**"]
path = ~/.gitconfig.work
$ cat ~/.gitconfig.personal
[user]
name = ov7a
email = home@address.ru
$ cat ~/.gitconfig.work
[user]
name = Vlad Chesnokov
email = some.work.email@company.com
Т.е. все репозитории в рабочей папке будут иметь рабочий акк, а в папке под всякую дичь — личный.
И… все, пока потребности разделять что-то еще не появилось.
P.S. В первое время удаленки я даже заморачивался и разделял работу и дом сменой футболки, и это реально помогало. Но летом в жару 30+ я на это быстро забил:)
Локальный запуск билда Gitlab
Как отладить непонятную проблему в CI, если нет доступа к внутренним логам? Запустить локально ее агент, благо сейчас все в контейнерах.
Но что делать, если в локально запущенном агенте билд все равно проходит? Даже если использовать агент с нужной версией?
Один из вариантов ответа — переменные окружения, которые локально, разумеется, отличаются. Однако это легко поправить — можно запустить любую команду, которая выплевывает эти переменные (например, env) и скопировать себе (со всеми секретами и приватными ключами, которые любезно будут выведены).
В моем случае проблема была в том, что кто-то запихал в переменные окружения много всего, а в одной из задач gradle они копировались в SystemProperties. При запуске этой задачи в отдельном процессе она тупо давилась их количеством.
Рейтинг постов канала в Telegram
Накалякал скрипт, который качает посты из указанного чата в телеге и сортирует их по метрикам.
Внезапно, самым сложным оказалось найти версию библиотеки Telethon, которая и реакции поддерживает, и еще не сломана в процессе обновления на v2. Другую я заленился смотреть, но благо узнал, что можно ставить pip-пакеты прямо с GitHub’а:
pip install 'git+https://github.com/LonamiWebs/Telethon.git@539e3cb8081acbd9a5cc7a61c0731ca62842597e'
К сожалению, сам анализ никаких больших открытий не дал — посмотрел топ-посты в паре каналов с мемчиками, да и все.
SQL на csv
Прикольный рецепт как выполнять SQL запросы на CSV-файле: данные загружаются в in-memory sqlite, а там уже можно делать с ними что угодно.
Чтобы не запоминать зубодробительную строку, можно добавить функцию в ~/.bash_aliases:
function sqlcsv() {
filename=$1
shift
sqlite3 :memory: -cmd '.mode csv' -cmd ".import $filename data" "$@"
}
Причем можно использовать как интерактивный режим, если передать только имя файла:
$ sqlcsv rus_cities.csv
SQLite version 3.37.2 2022-01-06 13:25:41
Enter ".help" for usage hints.
sqlite> select * from data where source='омск' limit 3;
"омск","кадников","о"
"омск","казань","о"
"омск","калач","о"
так и неинтерактивный, если передать один или несколько запросов:
$ sqlcsv rus_cities.csv "SELECT DISTINCT(source) from data where source like 'ц%';" \
"SELECT COUNT(DISTINCT(source)) from data WHERE source like '%ц' or source like '%цы';"
"цивильск"
"цимлянск"
"циолковский"
15
Конечно, это все можно сделать и в Excel/аналоге, но я лично потрачу больше времени на гугление нужных формул, чем на написание SQL-запроса.
Камеры на созвонах
Уже в нескольких утюгах обсуждают статью, в которой проводятся результаты нескольких исследований:
- 103 человека медицинской компании, по результатам 4 недель на основе опросов: люди устают больше с камерами, камера незначительно влияет на вовлеченность, женщины и новички от камер устают больше.
- опрос 10 000 человек, которые регулярно используют камеру на созвонах: женщины устают от встреч больше, более взрослые люди — меньше.
- 150 обучающихся: студенты на лекции, где были включены камеры, лучше сдавали тесты.
На мой взгляд, исследования недостаточно глубокие и разносторонние. Второе более-менее логичное (кому важно хорошо выглядеть в глазах других, тому тяжелее дается общение), но там нет контрольных выборок (созвоны без камер, очные встречи и т.п.). Еще стоит отметить эффект зеркала — если много смотреть на себя в “зеркало”, то это приводит к стрессу и тревожности. Третье исследование довольно узкое, а первое — наоборот, недостаточно подробное: у встреч могут быть кардинально разные цели. И ни в одном исследовании нет контрольных выборок.
В исследованиях плохо затронут вопрос повестки и качества встреч. Можно весь день провести на бессмысленных созвонах, куда тебя позвали просто “ну а вдруг надо будет”, где нет четкой повестки — там без камеры можно хоть своими делами позаниматься. А если на встрече все участники четко понимают полезность и необходимость, у встречи есть четкая цель — то там даже без камер будет продуктивно.
При этом многие источники указывают на то, что включенная камера повышает вовлеченность и помогает развивать эмпатию. Я в целом с этим согласен, но сначала стоит решить вопрос с необходимостью встречи. Добавлю, что вести семинар для студентов с выключенными камерами, где тебе отвечают 2-3 человека — очень грустно, не хватает обратной связи (особенно, когда на очном их меньше, но они активнее).
Версионирование библиотек
Интересный доклад про то, какая бывает совместимость между разными версиями библиотеками, как безопасно приносить новое и удалять старое.
Вообще целевая аудитория — разработчики библиотек, но и пользователям тоже полезно, чтобы понять, почему нужно писать всякие @ExperimentalAPI или @OptIn и как Kotlin дошел до жизни такой.
Как выиграть в "города" (России)
Ну, чтобы не запоминать все 1113 штук, разумеется. Обычная тактика — долбить в какую-то редкую букву (т.е. запомнить максимальное количество городов, кончающихся на определенную букву) или наоборот, запомнить кучу слов на “К” и на все редкие. Ну или не играть в такие игры вообще :)
Можно проанализировать граф: скачать с Википедии список (использовав, например, готовый парсер таблиц). А вот для визуализации можно использовать… непонятно что. Есть миллиард библиотек на питоне и js, но это ж код надо писать. Есть онлайн-инструменты типа CosmoGraph, но опций там кот наплакал. Пришлось расчехлять Gephi, чтобы обнаружить, что в нем нельзя отобразить нормально петли или экспортировать в GraphViz. Но лучше я ничего не нашел (если есть что-то прикольное, посоветуйте, пожалуйста).
У меня была идея найти гамильтонов на всем графе слов, чтобы найти непрерывную цепочку городов, но простейшие размышления привели к выводу, что такого пути нет. Да и анализировать граф игры удобнее, когда вершинами являются буквы, а ребрами — слова (как на картинке).
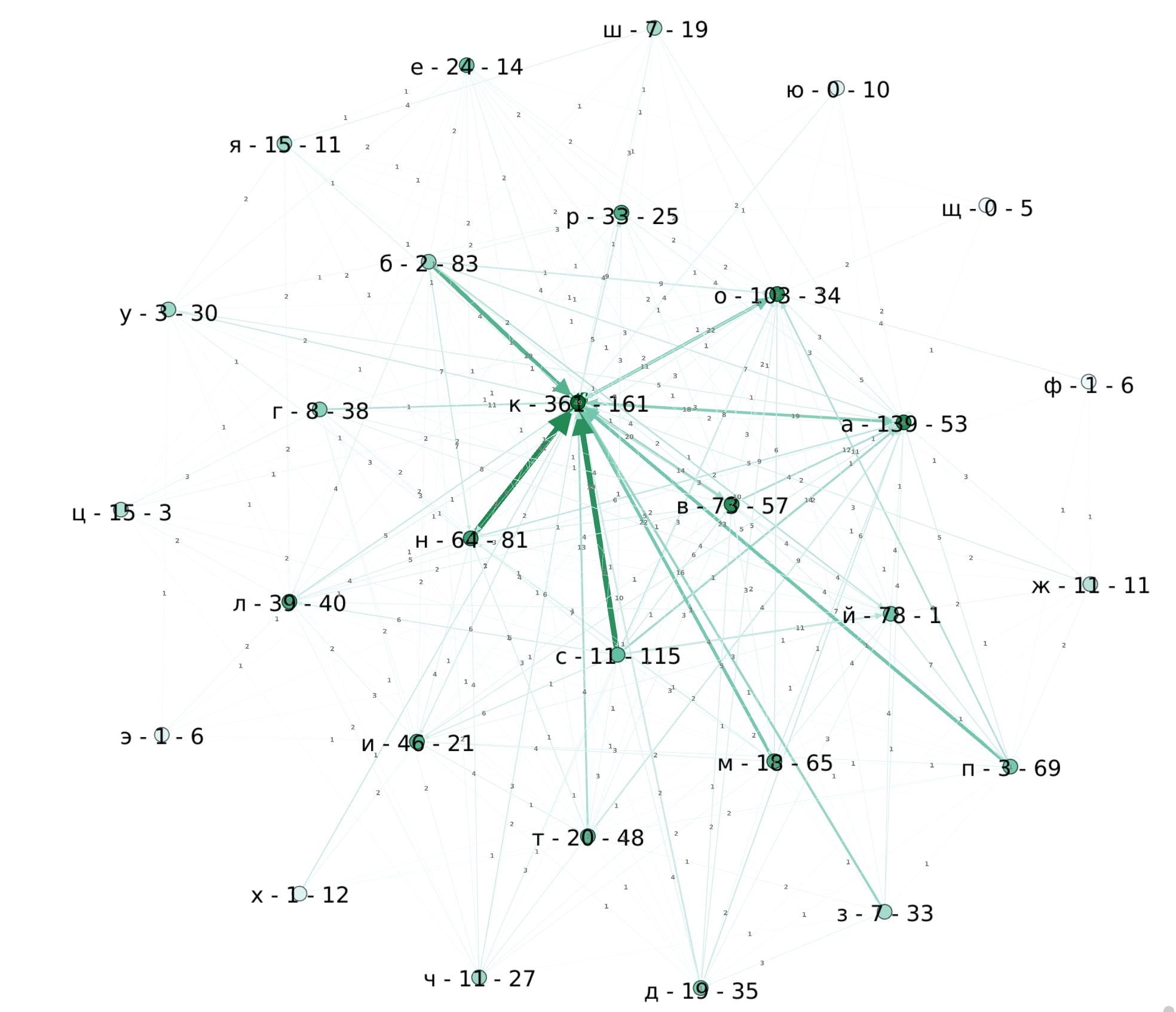
Из интересного:
- на “Й” начинается только Йошкар-Ола, а кончается — масса других. Но если приравнять “Й” к “И”, то будет тяжело.
- лидеры по окончаниям вполне ожидаемо “К” и “А”, а также “О” за счет бывших деревень и “В” в честь людей.
- хороший кандидат на редкую букву — это “Ц”. Вряд ли кто вспомнит 3 города: Цивильск, Цимлянск и Циолковский, а вот запомнить самому Череповец, Люберцы, Елец, Луховицы, Сланцы — легко (и еще 10 будет в запасе).
- еще можно попробовать долбиться в букву “Я”, но там 15 кончающихся против 11 начинающихся — надо будет специально запоминать (впрочем, кроме Якутска и Ярославля без подготовки тяжело что-то назвать).
Пирамида код-ревью
В продолжение темы про код-ревью — шпаргалка про то, чему стоит больше уделять внимание.
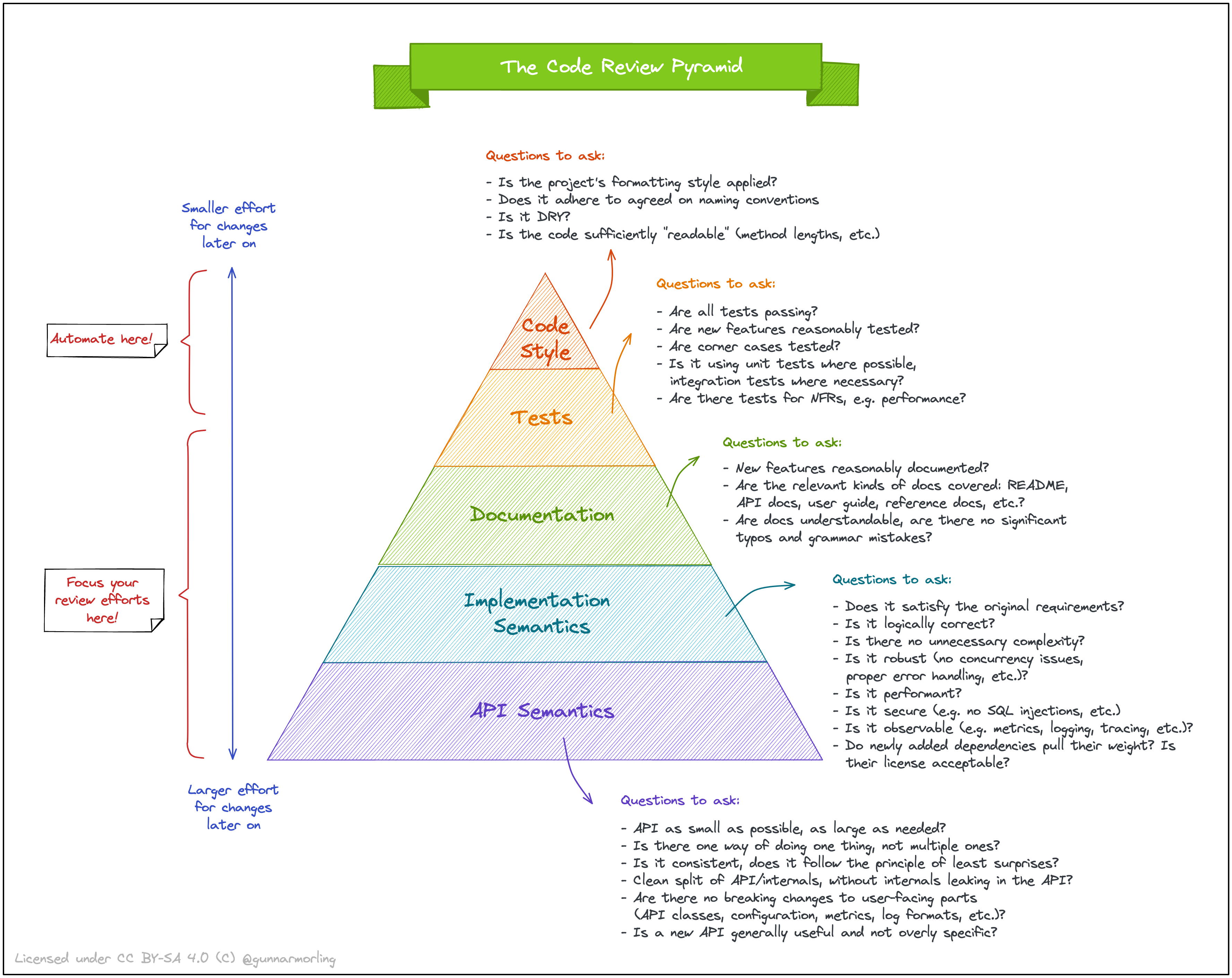{kind=link}
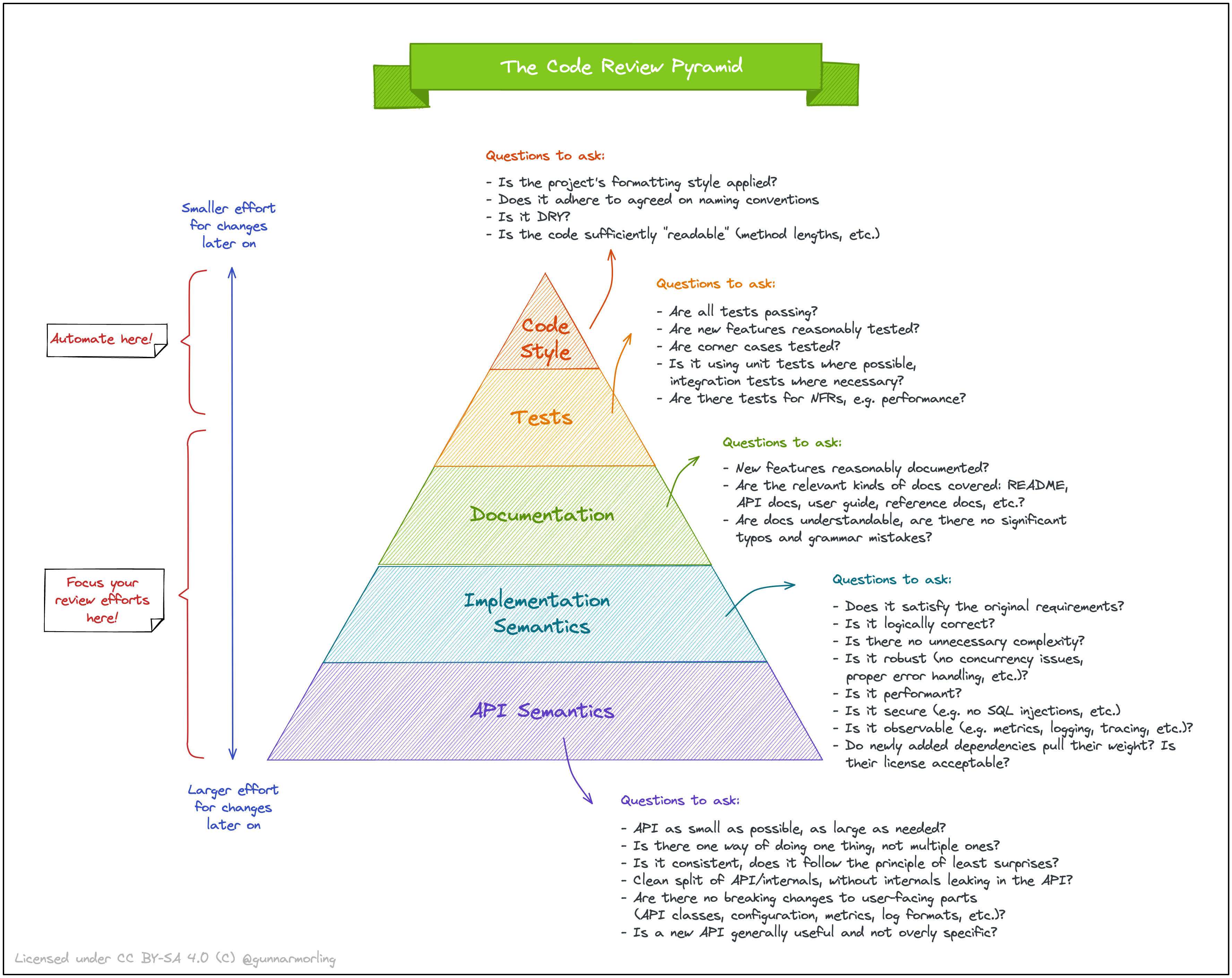
Отмечу, что она ничего не говорит про порядок проверки. И, разумеется, работает только при налаженном процессе: если кто-то хреначит коммиты в основную ветку без CI (потому что “знает, как надо”), а документации нет (даже в формате OpenAPI), то говорить тут о качестве ревью рано. Кроме того, тут еще не покрыт вопрос качества требований и их осмысления/анализа.