Читать в телеге. Когда-то там были посты не только от меня.
Задержка между нажатием клавиши и появлением символа на экране
В статье довольно неплохо описано, почему у старых компьютеров она меньше, чем у современных. Рекомендую почитать.
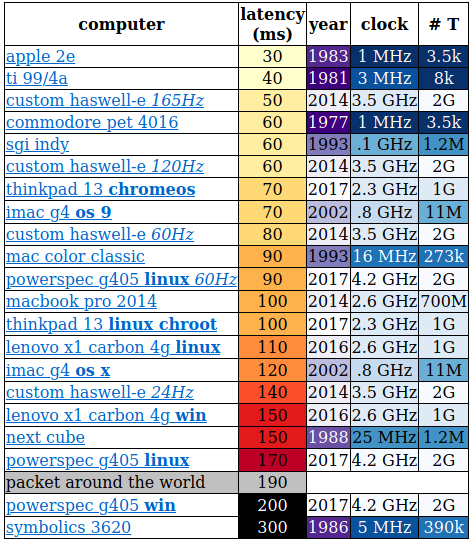
С одной стороны понятно, что куча абстракций и унификация стоят того. С другой — жаль, что почти везде выгода и скорость разработки сейчас важнее эффективности.
Перенаправление портов
Способов сделать это - тьма тьмущая:
- Настроить firewall - iptables, ufw, firewalld,… тысячи их! Обычно инструкция не всегда простая, надо курнуть манов.
- Если дело происходит на маршрутизаторе - то обычно есть встроенные средства (и GUI тоже).
- Haproxy и прочие решения для балансировки нагрузки. Сейчас такое даже в Spring есть встроенное.
- nginx, apache и прочие продвинутые веб-сервера.
- ssh. Например, так:
ssh -L 80:target_server:80 gateway_server. Чего он только не умеет… Кстати, в одном из проектов этот способ был весьма удобен для отладки взаимодействия с базой, к которой не было прямого доступа. - Консольные утилиты. Например, так:
socat TCP-LISTEN:80,fork TCP:target_server:80. - В каком-нибудь docker’е это задается на уровне конфига. В kubernetes команда
port-forwardделает проброс порта к поду. - Ngrok. Вы ставите себе утилиту на комп и она вытаскивает наружу веб-сервер с localhost. Типа чтобы демки сайтов заказчику показывать. Звучит как эксплоит, да и исходников нет… -_-
И наверняка этим список не исчерпывается.
Навигация по коду в Github
Github в ноябре добавил навигацию по коду: переход к функции в файле, переход к определению, поиск использований. Прикольная штука, жаль только поддерживаются далеко не все языки, только всякие попсовые типа Javacript, Go и Python. Примечательно, что библиотека для поддержки этого, semantic, написана командой Github на… Haskell.
Значение по умолчанию minimum_should_match
Какой будет minimum_should_match в bool_query, если его не указать?
Вроде как 1, но на самом деле - фигушки, если рядом есть must, то это 0:
В документации к версии 6.8 пишут:
If the bool query is a filter context or has neither
mustorfilterthen at least one of theshouldqueries must match a document for it to match the bool query. This behavior may be explicitly controlled by settings theminimum_should_matchparameter.
В версиях 7.0 - 7.4 про это не было сказано. Вообще. Хорошо хоть в 7.5 сделали отдельный раздел про этот параметр, где написано короче, но яснее:
If the bool query includes at least one
shouldclause and nomustorfilterclauses, the default value is 1. Otherwise, the default value is 0.
Благо elasticsearch - опенсорс и можно посмотреть, почему такое безобразие произошло с документацией: вот ее удалили, и только через год вернули.
Работа со временем
Если у вас есть возможность - никогда не работайте с человеческим временем, когда программируете. Потому что сделать все правильно нереально тяжело. Начиная с високосных годов:
И продолжая временными зонами:
Причем даже крупные компании не всегда все могут сделать правильно. Из недавнего - Apple фигово показывает календарь:
И наконец, большой список заблуждений про время: https://infiniteundo.com/post/25509354022/more-falsehoods-programmers-believe-about-time
Push-уведомления в браузере
В новом стандарте веба теперь тоже есть push-уведомления. Как на телефонах - сайт даже не загружен, а браузер уведомление кидает. https://www.w3.org/TR/push-api/ https://support.mozilla.org/en-US/kb/push-notifications-firefox
Что дальше? Магазин сайтов?:)
Кто пожрал все потоки в linux?
ps axo nlwp,pid,cmd | sort -n
GitHub Pages
Многие знают, что на гитхабе можно хостить статические сайты. Однако вряд ли всем известно, что там из коробки идет генератор статического сайта — Jekyll. Идея довольно прикольная: выбрал тему и/или задал несколько шаблонов, а потом клепаешь посты в markdown, не парясь о разметке и всем таком. Запушил посты в GitHub — и они уже опубликованы.
Однако есть нюансы. Как только надо что-то сделать что-то нетривиальное, приходится “преодолевать”. Например, я столкнулся со следующими проблемами:
- На GitHub Pages белый список плагинов, а некоторые встроенные - не очень (например, пагинация работает только для одного раздела). Это можно решить, генерируя сайт на своем компе, но тогда теряется все удобство использования связки jekyll и GitHub.
- В шаблонизаторе Liquid нет логического отрицания. Там есть конечно конструкция
unless, дополняющаяif, но какое-нибудь(a && !b) || (!a && b)там фиг выразишь. При этомandиorесть. - Иногда парсер markdown ломается, особенно если его перемешать с html-тегами. И где-то для этого используются регулярки, судя по исключениям, которые я ловил.
И еще была пара мелочей. Несмотря на это, копаться в этом было занимательно, у меня даже что-то получилось. Идея мне нравится, это правильный web в моем понимании, когда для статической инфы у тебя статический сайт, а не 10 Гб node-js модулей и не какое-нибудь адище. И клево, что контент почти полностью отделен от представления (этим мне еще Latex нравился). Но с точки зрения кода из-за ограничений GitHub Pages и jekyll получилось конечно классическое.

Space от JetBrains
JetBrains в декабре анонсировала новый продукт - Space, который объединяет в себе очень многое: ведение задач, хостинг репозиториев, календари, встречи, отпуска и т.д. Я смотрел демо на ютубе и общался с тимлидом разработки. Идея сама по себе интересная, но реализация на мой взгляд странная. Это огромный монолит, который пишется с нуля. Т.е. это не интеграция продуктов JetBrains (youtrack, teamcity, upsource и т.п.), и не развитие их продукта Hub, а новый продукт. Соответственно, все есть, но в очень куцом варианте. Заменить какую-то часть на свою - фигушки. С API и интеграцией с другими вещами тоже мутно. Миграций с жиры/ютрека/гитлаба не написано. Ориентация на облачное решение, чтобы локально развертывать - не в приоритете. Лид говорил, что им много людей писали восхищенно. А на то, что на каком-нибудь хабре народ довольно резко критиковал, толком ничего не ответил. В общем, продукт довольно спорный.
Список открытых файлов в системе
Как узнать, какой процесс занял порт на локалхосте, чтобы его убить?
Сколько файлов открыл и использует пользователь?
Для ответа на эти вопросы можно использовать утилиту lsof, которая выводит список открытых файлов:
lsof -w -n -i tcp:8080
lsof -u user | wc -l