Читать в телеге. Когда-то там были посты не только от меня.
Уровни компиляции JIT
В продолжение темы про работу JVM.
Обычно исходный код компилируется в байткод компилятором языка. Потом проходит его верификация и линковка, после которых он попадает в интерпретатор. И уже интерпретатор переводит его в исполняемый (машинный) код. Хотя можно вообще все скомпилировать заранее, как в C: например, с некоторым ограничениями это позволяет сделать GraalVM.
Есть 4 уровня компиляции:
- Интерпретатор
- C1 без профилирования
- C1 с минимальным профилированием
- C1 с максимальным профилированием
- C2 со всеми оптимизациями
Интерпретатор выполняет байт-код максимально тупо, “построчно”. В процессе исполнения интерпретатор приблизительно считает, как часто вызывался каждый метод, и после достижения порога он переходит на следующий уровень компиляции — третий. Метод компилируется, в него добавляются счетчики, чтобы получить более точную картину нагрузки. Он исполняется быстрее, чем в интерпретаторе, но все равно медленно. Потом метод попадает на уровень C2. Однако компилятор C2 довольно медленный и не всегда успевает все сделать, поэтому перед попаданием на третий уровень, метод иногда тусит на втором, “в очереди” — исполнение побыстрее третьего, но тут меньше информации. Бывает, что компиляция в C2 невозможна — тогда профилирование выкидывается, и метод работает на первом уровне без профилирования. А иногда JVM решает, что метод очень простой, сразу закидывает его на первый уровень и больше не трогает.
Можно отключить C1 (уровни 1-3) совсем, тогда метод будет попадать из интерпретатора сразу на C2 — и так было до JVM 8: у “серверных” приложений был С2 (медленный старт, но быстрая работа), а у клиентских — C1 (быстрый старт, но медленнее работа).
Возможна и деоптимизация, когда уже скопилированный код выкидывается и метод выполняется на интерпретаторе. Происходит это обычно из-за того, что спекулятивные предположения компилятора не оправдались (причин масса), и код не может работать корректно. В этом случае инлайнинг может навредить производительности: вместо маленького кусочка в интерпретатор может быть выкинут большой кусок с кучей заинлайненного кода.
Как настроить память для JVM
Некоторые утверждают, что настройки можно определить автоматически, но звучит это сомнительно, потому что JVM — довольно сложная штука.
Память JVM разбита на несколько областей:
- Куча (heap). В ней хранятся основные данные и работает сборщик мусора (GC), накладные расходы на который бывают до 10%. Кучу можно зарезервировать сразу всю флагом (
-XX:+AlwaysPreTouch), а можно динамически уменьшать и отдавать системе (-XX:UseAdaptiveSizePolicy), поигравшись с настройками зарезервированного запаса, но это работает не с любым GC. Источник проблем в этой области — большие объемы данных. - Метаданные классов. Всякие структуры классов, символы, константы, аннотации и т.п. В поздних версиях разделена на непрерывную область для классов (чтобы можно было сжимать указатели) и область для остальных метаданных. Гадостей в этой области может наделать загрузчик классов, генерирующий кучу классов на каждый чих.
- Область JIT-компилятора. Включает в себя скомпилированные куски кода и “арены” компилятора (где хранятся необходимые данные для компиляции: промежуточные представления, статистика и т.п.). Если включена многоуровневая компиляция (по умолчанию это так), то размер области под скомпилированный код увеличивается. Опасность плохих настроек тут в том, что область забьется, и код будет компилироваться и вытесняться по кругу, сжирая процессор. В стабильной системе JIT прогревается на старте и потом почти не вызывается.
- Потоки со стеками вызовов. По утверждению докладчика, тут обычно волноваться не о чем.
- Таблица символов и таблица строк. Тут тоже редко бывают проблемы.
- Внутренняя память. Содержит память, выделенную вне области с GC: ByteBuffer’ы (есть настройка для ограничения) и замапленные в память файлы (нельзя ограничить по памяти). Причем у буферов могут быть кэши в куче, которые еще локальны для потока и никогда не чистятся (но можно ограничить их размер). При аллокации буферов могут возникнуть проблемы с фрагментацией, поэтому стандартный аллокатор имеет смысл заменить, например на jemalloc.
Найти проблемы с утечками памяти можно с помощью async-profiler, который может перехватывать вызовы malloc и определять стектрейс к ним.
В итоге, чтобы определить проблемные места, нужно мониторить все метрики (в том числе включить логи GC и смотреть на метрики операционной системы) и подключать Native Memory Tracking для исследования тяжелых случаев. Посчитать итоговую формулу для контейнера нельзя. Хотя по опыту коллег примерно половина памяти контейнера уходит на память вне кучи.
Разновидности event-driven архитектуры
Согласно Фаулеру (видео), существует 3 типа Event-Driven архитектуры:
- event notification — уведомление о событии. У меня что-то поменялось, дерни меня синхронно, чтобы узнать что.
- event-carried state transfer — передача состояния в событиях. У меня поменялось поле, новое значение такое-то. Или мое состояние поменялось, вот текущее.
- event sourcing — нет никаких состояний, есть только набор событий, они являются мастер-данными. Хочешь состояние — либо сам храни, либо вычисляй. Иногда, так и быть, дадим тебе слепок, чтобы попроще было вычислять.
Генерация хэшей паролей
Чтобы вручную сгенерировать популярные хэши без регистрации и смс, помогут команды:
echo -n 'qwerty' | md5sum
echo -n '123456' | sha1sum
htpasswd -bnBC 12 '' 'password' #bcrypt
Облегчение Font Awesome и задержка из-за CSS
Внезапно обнаружил, что Font Awesome, webdings современного интернета, является встроенным шрифтом в Ubuntu. Однако для других систем его все равно надо подключать. Раздаваемый с CDN CSS, кроме директивы @font-face, содержит еще и кучу лишних предопределенных классов, которые просто проставляют содержимое с нужным юникод-символом.
Но есть и другая неприятная особенность включения стороннего CSS в код страницы: пока он не будет загружен, то страница не будет отображаться. Можете попробовать сами сохранить и открыть в браузере такой HTML:
<head>
<link rel="stylesheet" href="https://httpbin.org/delay/11">
</head>
<body>
<h1>Loaded</h1>
</body>
У меня он открывается примерно через 10 секунд. И такое поведение я наблюдал, когда редактировал сайтик в оффлайн режиме. Поэтому я отказался от внешней зависимости и сохранил Font Awesome на сайт.
Генерировать или валидировать?
Как известно, я люблю автоматизировать всякую дичь (например, 1, 2, 3, 4). Один из видов такой дичи — проверка того, что разные части приложения соответствуют друг другу и/или что тестами покрыто все, что нужно. В основном из-за недоверия к кожаным мешкам.
Приведу примеры:
- проверка того, что все модули системы покрыты тестами и включены в основной конфиг. Причем немного извращенная, потому что сверялись три места в коде: список основных классов, список классов тестов и список классов в основном конфиге приложения.
- проверка соответствия REST-клиентов соответствующим микросервисам. Куча рефлексии, чтобы проверить, что если вызвать все методы клиента со всеми параметрами, то будут вызваны все выставленные эндпоинты и покрыты все параметры и тело запроса.
- покрытие тестами схем камунды, о котором уже писал.
- проверка, что json-схема, маппинг Elasticsearch и swagger соответствуют друг другу.
Казалось бы, это странные операции. Ведь для проверки покрытия есть специальные утилиты, а такие вещи, как swagger, клиенты для REST легко генерируются. Но, как говорится, есть нюансы.
Средства покрытия не могут проверить все (например, все, что не является кодом) и их точность завязана на строчки кода. 100% покрытия редко достижимы, обычно это в районе 80-90%. Подразумевается, что в эти 10-20% попадает всякая служебная фигня, но никто не гарантирует, что это не окажется ядро системы. Кроме того, редко когда плохое покрытие блокирует релиз, да и мало кто смотрит эти отчеты. А вот если они валят тесты, то это уже повод что-то сделать (можно сделать таск на билде для завала по покрытию, но это обычно гемор).
Генерация — хорошая штука (в конце концов, код — это DSL для генерации машинного кода), но результат все равно придется как-то проверять. Можно довериться разработчикам генераторов, но никто не отменял garbage in → garbage out. Однако не на всякую дичь есть генератор, а хорошо написать свой — не очень тривиально. Сложно учесть все требования и нюансы, надо адекватно встраивать генерацию в процесс сборки, некоторые вещи все равно придется дописывать руками (какие-нибудь описания). Кроме того, страдает гибкость: в сгенерированном API-клиенте уже не затащишь два http-запроса в один метод, в swagger не детализируешь, что там в кишках json, который отдается as is из базы и т.п. Наконец, генерация — процесс с потерей информации, и если нет единого источника правды, который содержит ее полностью, то появляется дополнительная сущность, из которой генерируются остальные.
А написать проверку, что все соответствует друг-другу — довольно просто. И все сущности доступны напрямую из репозитория, ими легко поделиться (если это какой-нибудь контракт, например). Можно не заморачиваться с прокидыванием метаинформации (всякие описания полей) — ее все равно проверить может только человек. Ему правда писать придется чуть больше, но обычно это имеет позволительную цену. Лучше иметь явный тест, чем строчку в чек-листе код-ревью.
Устройство компилятора Kotlin
В версии 1.4 JetBrains немного поменяли архитектуру компилятора и про это есть довольно интересный доклад (слайды). В старом компиляторе были немного срезаны углы для быстрой разработки, а в новом все по классике: фронтенд-часть с выходом промежуточного представления (по факту — AST с дополнительной информацией) и бэкенд (который отвечает за генерацию исполняемого кода).
Из интересного:
- У языка все еще нет спецификации, покрывающей все нюансы языка. Источник правды про его работу — исходный код. Сейчас есть только черновик спецификации. Например, на момент доклада узнать, какие есть варианты смарт-кастов, можно было только из кода (хотя сейчас в спецификации довольно подробно описана куча вариантов, в том числе пример-загадка из доклада).
- Внутри компилятора есть типы-пересечения (например, общий родитель у
IntиFloat—Comparable<*> & Number), но они невыразимы (надеюсь, что это “пока”). - Все
ifконвертируются вwhen, но писать лучше все равно по-человечески, ручные микрооптимизации будут только мешать компилятору. - В бэкенд-части компилятора есть оптимизации, но они в основном используются для того, чтобы упростить конструкции, чтобы потом JIT’у было их проще понять и оптимизировать. Однако для Native и JS есть еще свои оптимизации, их больше.
Про устройство компиляторов есть еще доклад от небезызвестного Брагилевского (но там про Haskell уже). Я слушал его вживую на конференции, и он был неплох.
Лимиты Docker Hub
У Docker Hub есть лимиты на выкачивание образов. Значение по умолчанию — 100 загрузок за 6 часов. Маловероятно, конечно, что будет столько будет закачек, но если нет авторизации и выделенного IP, то исчерпать лимит возможно.
Решения два: либо заплатить бабок, либо качать через кэширующий прокси. Во втором случае нужно будет поменять конфиги и проверять helm-чарты, потому что в них могут быть указаны свои репозитории образов. Например, в bitnami/postgresql нужно заменить docker.io на свою прокси аж 3 раза.
Таймеры на сервисных тасках в Camunda
В Camunda таймеры не работают на сервисных тасках. Т.е. такой таймер
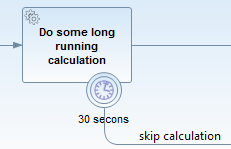
никогда не сработает. Связано это с реализованным механизмом транзакций. Таймер создается при заходе токена на таску, поэтому он просто не существует вне транзакции. Получается, таймеры не могут сработать, пока транзакция не закроется, а транзакция не закрывается, пока не завершится сервисный таск.
Что делать?
Если таск внешний, то таймер будет работать, потому что внешние таски находятся в состоянии ожидания (транзакция закрывается). Однако это будет означать разделение камунды и бизнес-логики на два сервиса и переход на Rest API вместо внутреннего.
Еще один вариант — реализовать паттерн асинхронного выполнения задач, в котором само задание кладется во внутреннюю очередь, потом транзакция закрывается и таск ждет сигнала-коллбека от обработчика задач. Но цена этому — отсутствие отката при ошибке.
Третий вариант — таймауты можно обрабатывать внутри логики делегата и кидать ошибку/эскалацию самостоятельно.
Наконец, можно отрефакторить схему так, чтобы таймер не был на сервисной таске. Однако банально выделить его в параллельную ветку с каким-нибудь условием не получится: параллельные ветки на схеме в движке выполняются на самом деле последовательно.
OffsetDateTime и Hibernate
При работе с датами Hibernate стоит быть аккуратным: он все типы конвертирует в java.sql.Timestamp, который по смыслу идентичен java.time.Instant. Поэтому информация о временной зоне будет потеряна: при чтении из базы в какой-нибудь OffsetDateTime будет подставлена системная зона. Так что проще сразу маппить на Instant во избежание недоразумений. Матерые Java-чемпионы так и говорят, что OffsetDateTime и ZonedDateTime для JPA не очень полезны. И вообще, можно стрельнуть себе в ногу с ними.
Можно еще выбрать в самой базе тип “timestamp with time zone”, если он поддерживается (потому что в SQL стандарте его нет), но, во-первых, Hibernate пофигу на это отличие, а во-вторых, в этом типе на самом деле не хранится информация о самой зоне, см., например, документацию Postgresql:
All timezone-aware dates and times are stored internally in UTC. They are converted to local time in the zone specified by the TimeZone configuration parameter before being displayed to the client.