Мысли про ИИ-кодинг
Так получилось, что кроме Codex, попробовал недавно еще немного этого вашего ИИ. Удачное время, чтобы сравнить инструменты и немного скучковать мысли для разгрузки головы. А заодно забыть об этой теме на время, так как она порядком задолбала.
Claude Code
Для первых шагов выбрал ту же задачу, что и для Codex. Когда делал ее в прошлый раз, в голову в фоновом режиме приходили мысли, а заодно и вариант решения получше, так что сформулировал задачу по-другому. Я снова принципиально ударился в крайность и ни строчки кода не написал самостоятельно.
И на работе, и в комментах к заметке про Codex вполне по делу насовали про skill issue. Claude Code по умолчанию “подталкивает” к текущему правильному подходу и сессия начинается с режима планирования. За счет этого я уже и контекста побольше навалил в начальном запросе и быстро смог отбросить плохие варианты и неверные предположения агента.
Однако сам процесс занял гораздо больше времени, чем я ожидал: примерно 2,5 дня в фоновом режиме, когда в перерывах между задачами разрешал агенту выполнить команду или немного смотрел код и говорил, что надо исправить. Причем иногда доходило до абсурда — один раз агенту понадобилось несколько минут, чтобы сделать уже одобренное однострочное изменение.
Качество кода на выходе — уже вполне достойное, но все равно надо внимательно ревьюить. Даже получилось что-то, что вмержили. Отдельно отмечу, что сгенерированные сообщения к коммитам слишком многословные.
С точки зрения UX — хорошо, что заточено все под агентскую разработку, но GUI весьма лагучий: пару раз текст сообщения агента пропадал при переключении между вкладками; несколько раз было, что чат внезапно прерывался без всяких сообщений и приходилось “пинговать” агента, чтобы продолжить.
А еще сам про себя Claude отвечает плохо: он не смог мне сказать, как его поставить без curl | sh, есть ли у него десктопный клиент и т.п.
Одобрять команды утомляет; Codex хотя бы предлагал вариант одобрения категории команд по префиксу, а тут надо в настроечный JSON лезть ради этого.
В общем, довольно много мелочевки, которая вызывала недоумение.
Как-то не очень это ваше программирование “решено”, если подобные баги в инструменте для ежедневного использования всплывают.
Конкретно на выбранной задаче я не почувствовал, что потраченная энергия и усилия стоили результата. Казалось, что у меня получилось бы лучше, если я сделал все сам.
Впоследствии, уже на более большой выборке решенных задач, я немного поменял мнение: есть задачи, которые я не очень-то хочу решать, и вместо борьбы с собственной мотивацией можно их спихнуть на агента.
Однако пока мне тяжело сказать, что таких задач много.
Да и качество очень плавающее — то какая-то магия и все отлично, то застрянет на какой-то элементарщине.
Вдобавок, несколько коллег поделились, что у них Claude мог игнорировать свои же настройки из .claude.

Copilot
В мире JS была очередная мажорная уязвимость в пакете, от которого куча других зависит. Были задеты и пара моих реп с GitHub Actions. Один action лежал просто так, более чем уверен, что его никто не использует (писал его для одной из прошлых работ). Но поскольку уязвимость серьезная, алерт пришел на почту — dependabot я этой репе давно отключил, потому что задолбал неимоверно.
{kind=link}
{kind=link}
Я решил чисто на рандоме попробовать дать задачу Copilot, благо это можно было сделать лежа на диване с планшета — из вкладки репозитория с агентами.
Внезапно, Copilot справился.
Описание PR — шляпа, но зато можно все уязвимости поправить в одном PR и не ждать пока в Dependabot сделают группировку (ладно, они это уже сделали, но узнал я об этом только когда эту заметку писал — настраивать мне все равно будет лень).
Воодушевленный успехом, попросил агента написать тесты — не с первого раза, но получилось правдоподобно. Я поревьюил наискосок — хуже не будет, но более чем уверен, что люди с бо́льшим опытом в экосистеме JS легко там найдут проблемы.
Позже я повторил успех с обновлением зависимостей для другого action, тоже получилось неплохо. Когда проверял результаты, заметил, что выдается предупреждение об устаревшей версии node. Отлично, работа для ИИ!
И тут случился первый обсер: после обновление action стал падать. Ошибка тупейшая: в Actions можно использовать node20 (устаревший) и node24 (новый), а опции node22 (как написал Copilot) — нет, ее пропустили. Пришлось давать еще одну задачу на обновление. Move fast and break things! Получается, что ИИ, имея полный доступ к репозиторию, контексту, документации, и обученный на датасете из очень похожих примеров, не справился с элементарной задачей во флагманском продукте той же компании в самой популярной экосистеме. Каждый бит информации по этой задаче находится под контролем GitHub. При таком раскладе так налажать — это надо уметь.
Дальше пошло под откос. В проекте со Scala и браузерными тестами обновление не задалось, потому что тесты были не очень стабильными. Агент ходил по кругу и провалился в какие-то совсем непонятные дебри, попутно генерируя треш в описании PR. Доделывал в итоге сам.
Но пик тупости случился, когда я попросил, казалось бы, элементарную вещь — добавить тег к коммиту. Агент потратил 18,5 минут, пока у него не кончилась память. Уже на ранних этапах “размышлений” агент понял, что у него нет прав доступа. Он попробовал несколько обходных путей, даже через браузер что-то сделать, но везде получал отлуп. В процессе размышлений он даже вывел свой токен просто текстом (сесурно, однако!), а потом еще и раскопал и вывел креды для раннера.
В общем, не получилось пока кодить чисто в браузерном чате, эх:(

ИИ для сопутствующих задач
Не стоит забывать, что все это — тупо казино.
Отладка и исправление багов — звучит привлекательно, но результаты рандомные: от “вау, как я сам до этого не додумался” до “че за херь я сейчас прочитал?”. Очень плохо работает для нестабильных сценариев и гейзенбагов — ИИ понимает их плохо, и легко скатывается в какое-то непонятное направление, тратя кучу ресурсов впустую. Туда же идет и исправление нестабильных тестов — результаты будут очень правоподобными, но совершенно бесполезными.
Написание тестов — для галочки сойдет, но про сценарии надо думать самому. Кодинг тут вряд ли узкое место. Читать/ревьюить сгенерированные простыни — ну, такое :/
Одноразовые скрипты для производства результата — отличная ниша, уже не раз писал об этом, повторяться не буду. Туда же идут инструменты, особенно для личного пользования — можно будет переписать с нуля при новых требованиях.
Доверять “общие задачи” — все еще сомнительно (и немного стремно, если почитать истории про OpenClaw). Недавно мне тут спам с рекламой ИИ-канала в комменты пришел: “Не нашел в описании админа канала поэтому пишу сюда”. Для справки: чтобы найти “админа канала”, нужно открыть описание, кликнуть по единственной ссылке там, попасть на этот сайт, кликнуть на Где я? и там уже будет тележный контакт (и это если не считать, что каналам можно писать в личку). 3 клика. Я дал задачу ChatGPT, Claude, Gemini и вкладке гугла с ИИ (которая тоже Gemini, но как будто немного другая) — без проблем справился только Claude. Гугловые инструменты выдали полную ерунду и неправильный ответ. ChatGPT на одном аккаунте даже в режиме глубокого исследования говорил, что не может это сделать, а потом еще и газлайтил, что в HTML-страничке канала нет никаких ссылок на сайт. С другого аккаунта худо-бедно со второго раза он смог-таки найти что нужно.
ИИ-презентации, документы и прочий текст — если насрать на результат, то сомнительно, но окей. Многие говорят, что пишут на себя Performance Review, а еще нейтрально-вежливые отзывы на коллег. Текст объявления о моем повышении был написан нейронкой — и ни один из менеджеров в цепочке его не читал. Написана там лабуда — одно достижение потеряно, другое переврано и т.п. А ИИ-сгенерированный видеоролик с презентацией итогов года, который показывают на синхронном созвоне — отдельный сорт кринжа.
ИИ для выполнения менеджерских задач… Скажем так, довольно много я поработал с менеджерами, которые могут на изи продолбать и забыть важную задачу или не суметь прочитать сообщение. Если не можешь организовать свою работу на достойном уровне без нейронок, то нейронки в этом тебе не помогут. Касается любых профессий.

Как правильно?
Ну ладно, может это я просто не умею нейронки готовить и у меня все еще skill issue? Давайте посмотрим видео от вроде как уважаемого автора курсов про то, как на практике использовать последние достижения техники агентной разработки. В ИИ-чатике на работе порекомендовали, некоторые коллеги позитивно отзывались. Рекомендую сначала посмотреть и составить собственное мнение, прежде чем читать мое.
Мои мысли про видос
Это просто пиздец какой-то.
Проект с одним пользователем, который запускается локально — уже тут можно было закрыть, никаким “real-world example” тут и не пахнет.
Чел первые полчаса голосом наговаривает задачу и болтает с планировщиком о какой-то мелочевке, обсасывая детали. Какой-то странный концепт, отличающийся одним полем, требует мелкого фикса на морде (на беке почти ничего править не надо). В итоге создана куча текста, PRD, и агенты погоняют агентами в докере чтобы сделать фичу.
Докладчик бахвалится пресловутой единой терминологией из DDD, которую он хранит в .md и которую в том числе читают агенты.
Первый коммит — как раз обновление терминологии.
Однако далее в видео он не хочет видеть только что введенный термин в пользовательском интерфейсе (sic!).
Кроме кода, агенты еще нагенерировали и план тестирования. Проходить его, разумеется, будет человек. Докладчик даже не предпринял попытки его изменить или придумать свой сценарий. Надеюсь, что план тестирования хотя бы другой агент генерировал, а не тот же, что и кодил…
Только на этапе тестирования чувак начинает осознавать, что вместо двух концептов, отличающихся одним полем, можно оставить один концепт с дополнительным полем. И это было в плане. Он его не читал. Он мог бы пофиксить эту проблему на стадии плана, если бы хоть немного вникал в суть работы. Но вместо этого он болтал о какой-то ерунде. Чувак открывает для себя, что подход spec-to-code не работает (вау, наверно и водопад — это хрень:)).
Вообще, часть созданных тикетов были про вещи, про которые никто не подумал на этапе проектирования. Если бы чел кодил и тестировал в процессе, то это сразу бы всплыло. Хотя как будто код даже агенты не тестировали. Но ничего — чувак закрыл QA-план, не пройдя его до конца. Одни проблемы от этого тестирования:))
Тем временем было создано 15 коммитов, и в каждом — простыня-описание, которую никто никогда не будет читать. После итерации исправлений чел пропустил “скучную” часть, где он все тестит еще раз и репортит баги. Сказал, что хочет показать одну вещь, и там у него была видимая проблема со скоростью создания пары файликов на диске.
Код докладчик не показал, но сказал при этом, что иногда смотрит интерфейсы. Что ж, я нашел код — вот, можете оценить. Видно, что коммитов меньше 15, но ладно, может он сквошнул, а не тупо в помойку выкинул лишнее. Изменено 43 файла, но почти везде тупо прокидывается 1 флаг или одно поле и сделан попутный рефакторинг. Добавлена одна модалка. На бэке есть несколько изменений, которые выглядели странно, потому что эта логика уже должна была существовать в других местах (если судить по началу видео).
Безусловно, впечатляет, что на все про все у докладчика ушло примерно 3,5 часа. Жалко только, что соотношение сигнал-шум очень фиговое. И как вы думаете, насколько адекватно спроектирован код, в котором для добавления 1 флага нужно 7 тикетов, 14 коммитов, 43 измененных файла и накопипащенная логика?
Натурально анекдот про изменение цвета кнопки в бигтехе за 5 месяцев. 10x инженер, но с бюрократическим нюансом:) Если так в будущем должна выглядеть разработка — я, пожалуй, пока обожду, спасибо.

Фокус и продуктивность
Некоторые активные ИИ-адепты провозглашают, что прям писать код руками скоро будет не нужно — правдоподобно, что так можно делать, но будет ли это эффективно — сомневаюсь. Если весь ваш бизнес можно навайбкодить — какая у него ценность? Если у вас нейронки автоматизируют рутину, а вы весь такой только за архитектуру и высокоуровневые решения — то кто таких решений напринимал архитектурных, что этой рутины столько много? И откуда будут браться понимание, экспертиза и адекватные абстракции?

Хайп ведет к тому, что и сверху начинают требовать “быстрее” (почитай еще этих иишных линкендиновских постов, да нагенерируй слопа), люди начинают “бежать еще быстрее” и превращаться в оркестраторов агентов, чтобы “успеть”. Понимание и осознания меняются на скорость. А качество и заложение фундамента на будущее идут в известное место.
Я в один из дней осознал, что жонглирую своим вниманием, переключаясь между тремя задачами с очень низким квантом внимания (одну из задач “делал” агент). Везде получалось херово. Состояние потока — не шутка, в тик-ток режиме и результаты соответствующие.
Я пробовал слушать (не очень важную) встречу и уделять внимание агенту — получалась полная ерунда. При этом у меня есть опыт еще с самого начала удаленки — кодить рутину (или монотонно рефакторить) и слушать могу, ревьюить простенький код и слушать — тоже, но хуже. А вот с агентом — нет, слишком много внимания ему нужно.
Я пока видел несколько научных исследований, где профит от использования ИИ в кодинге был либо отрицательным, либо сомнительным (например, 1 или 2), но вот про повышение продуктивности мне ничего не попадалось (скиньте, если знаете, пожалуйста). По ощущениям, прироста производительности можно достичь, но очень вряд ли, что кратного. Некоторые вещи может и покроют большим контекстом, но у этого подхода есть предел. И не забывайте, что повышение продуктивности не обязательно будет означать, что вы будете меньше работать; скорее наоборот — будут больше требовать.
Устраивается секретарша на работу. Директор ее спрашивает:
— Какая у вас скорость печати?
— 1000 знаков в минуту!
— Так много???
— Правда такая ерунда получается…
ИИ — это автомобиль
Да-да, любая аналогия ложна и все такое, но все равно вброшу.
Автомобиль — это прогресс, он быстрее пешего перемещения или “классического” транспорта вроде телеги с лошадью. Однако в космос на нем не полетишь, море не переплывешь, а для эффективного использования нужны хорошие дороги.
Первыми авто было тяжело управлять, но потом с развитием технологий все стало проще. Однако после периода активного развития технологий происходят уже тупо инкрементальные изменения.
В соседнюю комнату на автомобиле не поедешь, в магазин у дома — тоже. Пешком ходить приятнее и полезнее, да и часть пути все равно придется пройти. Город только для машин — это тупо и неудобно, город должен быть для людей. В некоторых городах не работает интернет с картами, и надо хорошо его знать, чтобы понимать, как ехать до места назначения.
Итого
В целом, прогресс не стоит на месте и есть пласт задач, которые можно делегировать нейронке. Однако, как и любой инструмент, надо использовать с умом и понимать, когда это имеет смысл, а когда — нет. Я собственными глазами наблюдал, как сеньоры с сединой пытались решить задачу в лоб ИИшкой, когда стоило бы написать скрипт (при этом скрипт можно было бы бы даже тупой нейронкой нагенерировать). Ну и относительно нейтральные челики уже говорят, что мозги потихоньку атрофируются.
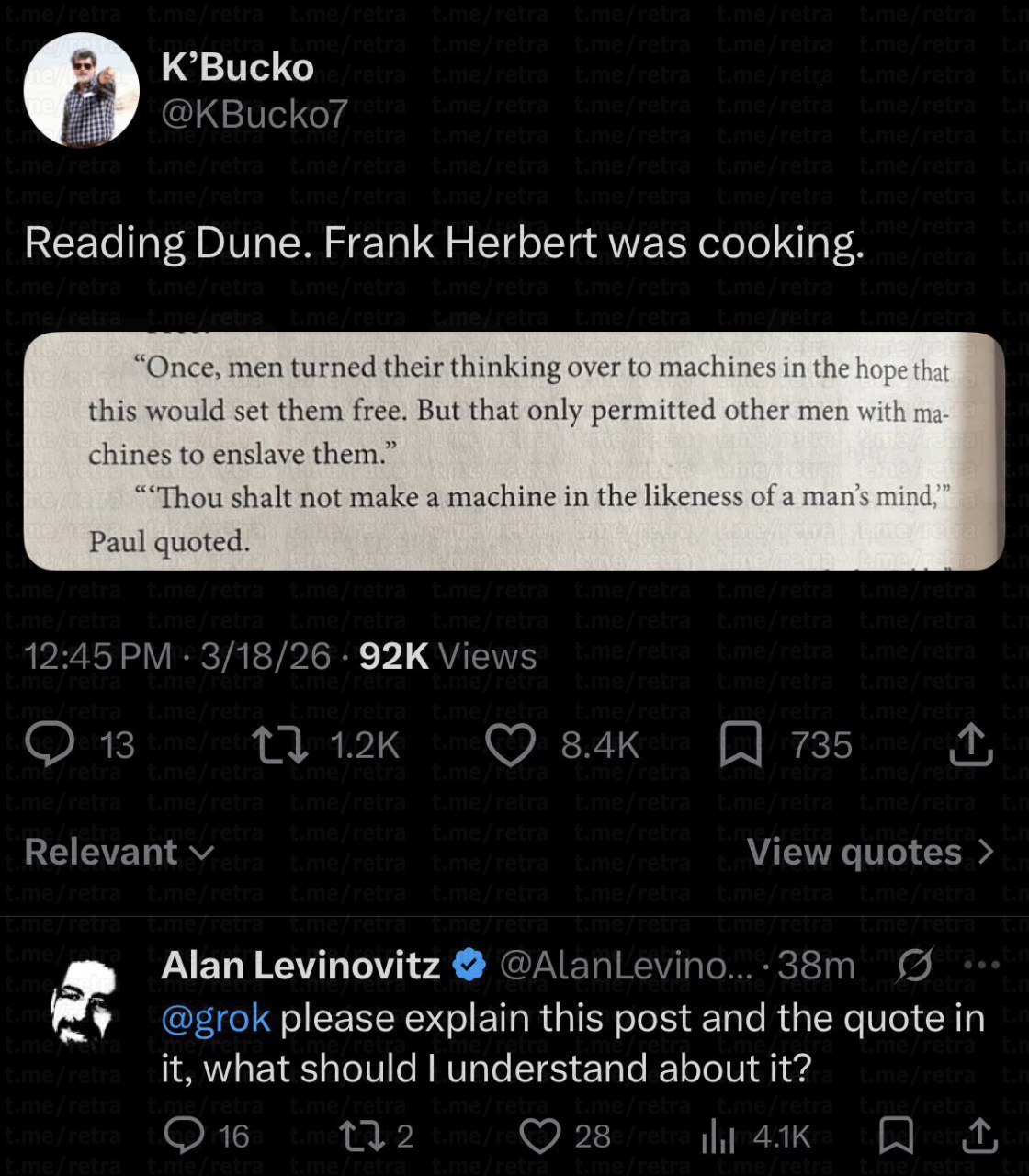
Если более конкретно про инструменты, то в существенном количестве задач я чувствовал себя продуктивно с Claude Code — по крайней мере, под него можно подстроится и использовать как помощника. Codex использовать не вижу смысла, Gemini и Copilot — дауны, но последнему можно дать самые тупые, спинномозговые задачи уровня dependabot напрямую со странички репозитория в браузере.
Хайпа слишком много, у многих С-level явный синдром FOMO с соответствующими последствиями, который усугубляется “советчиком”-жополизом (“вы абсолютно правы!”). Ускорение присутствует, но и нюансы тоже есть — короткая обратная связь не гарантирует качество, и понимание приносится в жертву. При этом польза чувствуется, но надо вдвойне следить за своей способностью к критическому мышлению, чтобы не попасться в ловушку одобрения и разжижения мозгов.
Помните, что азартные игры вызывают зависимость. И да, казино всегда выигрывает.

Эксперимент с Codex
Попробовал на днях Codex — а то чё как лох, уже никто сам код не пишет, все только роем агентов погоняют… Codex выбрал из-за того, что это невероятно революционная, новая модель, которая уже открывает эпоху сингулярности, согласно некоторым авторам, да и вообще, это стандарт индустрии.
/s Ладно, ладно, на работе очень настаивали, а у Codex была акция на пробный период.
Я хотел было попробовать как белый человек через IntelliJ AI Chat (Core-фича, между прочим!), но там меня сначала регион заставили проставить, а потом еще и данные карты попросили — нет, спасибо. Пришлось скачать официальное приложение Codex. Использовал модель по умолчанию — ChatGPT 5.3 Medium.
Постановка задачи
На свежем клоне исходников Gradle дал в качестве задачи исправить этот тикет — без мудреных промптов, но с подсказкой по поводу того, откуда начинать. Суть задачи довольно простая: есть зависимости дистрибутива в отдельном файле, надо написать билд-логику по генерации файла лицензии, в котором приведены лицензии всех компонентов в поставке, и проверки его актуальности. Ссылку на файл дал, пример файла с лицензиями в репозитории есть (его просто 1000 лет никто не обновлял), в дебри кода лезть не надо (контекста, соответственно, кот наплакал — преобразовать один файл, запросить данных чуток, да и встроить в существующие проверки).
Первый блин комом
Почти сразу Codex понял, что описание тикета устарело — файл, на который он ссылался, уже удален. Я параллельно сам посмотрел — все действительно так, но это не сильно что-то поменяло бы: там был мертвый код, а файл лицензии, возможно, обновляли руками. Но подобная археология — минус вайб, так что глубже копать не стал.
Codex эта проблема не остановила. Он накодил проверку, что все зависимости в реальном дистрибутиве соответствуют тому, что объявлено в файле с их списком. Круто конечно, но это вообще не то, что я просил и с тикетом не особо связано. Код при этом был так себе, и, например, не был совместим с фичей Configuration Cache, о чем сам Gradle очень активно жалуется (этот момент Codex прочитал из вывода и мне написал).

Пробуем все-таки решить задачу
Я сказал Codex, что это не то, и дал более подробные инструкции. Он понаписал когда, но на выходе все равно получилась какая-то хрень, которая хоть и обновляла файл лицензии, но совершенно не в том формате. Я указал на это, Codex поправил, и на поверхностный взгляд теперь было “похоже на правду”.
Я решил посмотреть, а что в итоговом файле с лицензиями и заметил там зависимость, которой нет ни в дистрибутиве, ни в объявлениях. Спросил Codex — он сам проверил граф зависимостей и обновил код. Стало лучше, но не намного. В коде были видны огрызки от старых итераций.
Порефакторим
Попросил перенести код из билд-скрипта в плагин и перепроверить работу — Codex справился. Потом попросил обеспечить совместимость с Configuration Cache — попыхтел, че-то поменял, но в итоге тоже справился, даже доказательства предоставил. Читать новый код я, конечно, не стал:)
Наконец, попросил удалить неактуальный код. Вот тут Codex провалился — очевидный мусор не удалил. На мой вопрос про это Codex ответил, что он нужен для сохранения обратной совместимости. С форматом одной из предыдущих итераций, который он сам выдумал, и про который я еще тогда сказал, что это фуфло. После просьбы нерелевантный код он все-таки удалил.
Окей, проверяем результаты
Проверил файл с лицензиями еще раз — и почти сразу в глаза бросается ошибка: неправильная лицензия у BouncyCastle. О_о Но почему? Ведь код читает POM для зависимости из Maven Central, а там явно указана лицензия. Я указал на эту проблему Codex, даже ссылку на POM дал… И он просто впилил костыль — тупо сделал особый случай конкретно для этой зависимости.

Вообще, захардкоженных записей было подозрительно много, и я попросил их все убрать и явно перечислить все зависимости, для которых не нашлись лицензии. Codex вывел довольно длинный список, по дороге немного подавившись зависимостью от jQuery (в HTML-отчетах используется). Я взял первую попавшуюся зависимость оттуда, проверил POM — разумеется, в нем была объявлена лицензия :/ Попросил Codex поправить, ткнув носом — что-то он там поменял, но список был все еще длинный.
Взял еще одну зависимость наугад — ладно, теперь в ее POM не было лицензии. Спросил Codex — он сам додумался, что лицензия в родительском POM зарыта. После исправления этого косяка список сократился до 3 пунктов: jQuery, native-platform (которая тоже Gradle разрабатывается) и plexus. Первая зависимость — из мира JS, там POM и не будет, вторая — из нашей репы, да и лицензия там может быть криво прописана, а с третьей проблема была в том, что поменялись координаты (группа стала другая).
С поддержкой смены координат Codex не справился — пыхтел-пыхтел и в итоге тупо поменял координаты в объявлении зависимостей. Потребовалось еще два промпта, чтобы откатить его неработающие изменения и почистить мусор.
Соответственно, на оставшиеся две зависимости просто попросил добавить специальную обработку.
Но и после этого результат оставлял желать лучшего. Я попросил Codex перепроверить, что файл с лицензиями точно-точно содержит все зависимости и что валидация не пройдет, если будет добавлена новая зависимость в дистрибутив без изменения файла с лицензией. Codex нашел какой-то баг, начал его править… и тут у меня кончились токены: я сжег недельный бесплатный лимит.
Немного про UX
Когда я в первый раз попробовал запушить код, то приложение не справилось — не смогло спросить у меня кодовую фразу для ssh-ключа :/
Единственный вариант, который я нашел, чтобы посмотреть все изменения в ветке, чтобы их поревьюить — это запушить все и посмотреть разницу на GitHub. Хотя тут понять можно — негоже вайбкодеру код читать.
В общем, в нормальной среде разработки это может и норм работает, но в самом приложении разрабатывать — это какая-то шляпа, ничего толком не сделаешь: знай себе пиши промпты да пушай в git.
Итого
Результат можно посмотреть тут. Вроде как “работает” и выглядит правдоподобно, но есть проблемы: в выходном файле — дубликаты лицензий и левые лицензии которые уже не нужны, в коде так вообще куча стремных паттернов. Это не тот код, который я готов вмержить, даже с прицелом на последующий рефакторинг. Для одноразовой задачи одна из итераций сошла бы с доработками, но с таким и обычный чат справляется, без “агентства”.
По сравнению с прошлым опытом как будто стало лучше — меньше какой-то откровенной тупки и результаты хотя бы компилируются. Однако нянчится все равно нужно слишком много, да и фундаментальные проблемы как будто те же самые.
Во время сессии тяжело было сфокусироваться — долго ждешь результата, высокое время отклика со всеми вытекающими. Коллеги рекомендовали делать в фоне — но мне кажется, что тогда куча мыслетоплива сожжется на переключение контекста.

Наконец, результаты надо как-то проверять. Однако для этого надо наработать какой-то опыт и углубиться в проблему. Обычно это случается, когда собственно делаешь задачу.
Так что да, вроде стало лучше, но я все еще скептически настроен насчет агентного кодинга как основного способа разработки.
Образование и нейронки
Когда ChatGPT только появился, почти сразу начались обсуждения по поводу его использования в образовании (в основном со стороны студентов). А 2,5 года назад так вообще был защищен диплом, почти полностью написанный ChatGPT. Но на мой взгляд, использование нейронок, чтобы сдать какую-то работу — это не новая проблема, а скорее просто еще один фактор, который подсвечивает старые. Ну и делает все еще проще для студентов.
Ниже я выплесну свои мысли по поводу текущих проблем, в которых нейронки мало что поменяют (на основе личного опыта преподавания), расскажу о своем опыте с режимом обучения ChatGPT и поделюсь идеей учебной задачи с использованием нейронок.
Это не новая проблема
Мотивация
Если студент не хочет учиться и/или ему не интересен предмет, то насильно мил не будешь. Если студенту нужна оценка, а не знания/навыки, то и получит он скорее всего только оценку. Студент будет использовать любые средства слиться с любого задания, если ему лень, неинтересен предмет, он считает предмет не нужным, ему нужно работать, и т.д. и т.п. Избежит ли он работы с помощью нейронки или другими средствами — вообще не важно, конечный результат примерно одинаковый.
Усугубляется все это тем, что на предыдущих этапах обучения все было так же. Совершенно нормально, что студент технического вуза на третьем курсе может не знать, что такое логарифм, производная, предел. Но страшнее даже не это — студенты не хотят это узнавать. Зачем? Они все равно получат свой диплом с минимумом усилий. Однажды я поставил во второй раз двойку студентке, которая не ответила на тот же вопрос, за который получила предыдущий неуд. Более того, некоторые студенты даже не умеют искать материал — процентов 20-30 студентов я мог завалить вопросом “какого цвета учебник?”.
С точки зрения препода в таких условиях надрываться, чтобы студент сделал все сам, довольно бессмысленно. Особенно когда отчислить студента почти невозможно. Мотивированные студенты смотрят на весь этот балаган и в итоге тоже начинают забивать — их усилий никто не оценит.
Плагиат и ГДЗ
Вот возьмем тот же диплом. Раньше, до ChatGPT, нельзя было написать работу за кого-то другого? Или может, нельзя было скопипастить на 80% дипломы прошлых лет? Ну в конце концов, собрать диплом из нескольких готовых статей из интернета? Да, теперь студент это может сделать несколькими промптами бесплатно и с меньшим вовлечением мозгов, но с точки зрения конечных результатов мало что поменялось.
Какие-то контрольные мне и раньше сдавали, списывая статью из Википедии, даже не вникая в суть текста, и без понимания, является ли он ответом. Неоднократно были ситуации, когда списывали из 2 источников и текст ответа противоречил сам себе. И раньше многие математические примеры можно было скормить какому-нибудь WolframAlpha и получить относительно приемлемый ответ. Наконец, никто не отменял старшие курсы с их материалами — если программа и задания особо не меняются, то и готовые ответы будут почти на все.
Короче, и без нейронок будет миллион способов списать/сдать “на отвали”.
Актуальность программы и состава курсов
Чтобы “бороться” с переносом ответов между курсами, надо бы обновлять программу курса регулярно. Признаюсь, что уже на третий год мотивация это делать у меня, как у препода, была близка к нулю: программа семинаров после второго года менялась очень точечно (в последние года — в основном в сторону упрощения), а новые задачи я придумывал максимум по 2-3 штуки за год.
Ну а если пришел студент за одними знаниями, а получает в итоге другие — кто виноват и что делать? Зачастую программа специальности прибита гвоздями и будешь ты на технической специальности учиться рандомным фактам из истории, которые ужали в один семестр с зачетом, потому что “ну надо”. См. раздел про мотивацию.
Помогут ли как-нибудь нейронки актуализировать программы курсов? Теоретически да, но если задания генерит нейронка, то она же их и решать будет. С точки зрения подачи теоретических знаний не так уж часто что-то кардинально меняется. Можно обновить язык и попытаться попасть в текущие тренды, но это скорее мишура (и, вероятнее всего, будет кринжово).
Бороться с бюрократической шизой изменения программ специальностей я бы на месте уважающего себя ИИ не стал бы.
Формальные требования — формальный результат
Когда к диплому предъявляются требования в формате N страниц по структуре X, то и на выходе будет нужное количество страниц с водой, которые даже научный руководитель читать будет наискосок, и то в лучшем случае. И раньше там была сплошная копипаста с графоманией. Если есть пункт только для галочки, так и пусть его нейронка пишет (но надо хотя бы прочитать, чтобы откровенной ерунды не было). Могу сказать, что вода, написанная нейронкой и вода, скопипащенная студентом, практически не отличаются по качеству.
Вообще, если диплом читает в лучшем случае только научник, да и то не весь, почему кто-то так борется за качество текста в нем?
Вас много, я — одна
В идеале экзаменатор должен проверять степень усвоения знаний. Вот только как это сделать нормально?
Письменный экзамен с запретами? Десятки лет эволюции шпаргалок, устройства любого уровня компактности, тупая зубрежка, слитые вопросы и прочие смеются вам в лицо.
Персональные задания? Кто их будет генерить? Нейронка или тупой скрипт, где будут меняться циферки в шаблоне? Ок, задания будут не идентичны, и полные тупни их не вывезут, но существенно они вряд ли что-то поменяют.
Опрашивать каждого студента лично на экзамене и контрольных, чтобы понять его подходы к мышлению и глубину знаний? Вот это хороший вариант. Одна проблема — никак не масштабируется, когда у тебя на 1 лектора и 1 семинариста 100 человек на потоке, и ты хочешь не за красивые глаза оценки ставить. Да и студентам сдавать несколько экзаменов за сессию тяжело уже.
Можно еще давать NP-полные задачи, которые было бы тяжело решить, а проверить можно было бы быстро. Но генерировать интересные задачи в достаточных объемах весьма нетривиально.
Можно ли пользоваться X?
При оценке знаний, например на экзамене, можно ли пользоваться конспектом лекций? Учебником? Калькулятором? Шпаргалками? Интернетом? WolframAlpha? Питоном? ChatGPT?
Где та грань между знаниями, которые должны отлетать от зубов, и информацией, всегда доступной по запросу? Должен ли я помнить факт N? Ничего, что работаю я за компом, где все эти знания есть, а на крайний случай есть телефон?
Стоит ли тратить время на неуспевающих?
Без обратной связи любая система гниет. Если единственный способ у препода избавиться от студента — поставить ему положительную оценку, то корреляция оценки с уровнем знаний будет слабая.
Еще моя бабушка решала вопрос кардинально — ставила всем тройки на халяву: ей было жаль своего времени. Я был не согласен с ее подходом. Из года в год на моем предмете было больше трети недопущенных к экзамену в конце семестра. При этом планка требований падала ниже и ниже.
С точки зрения препода принимать задолженности у двоечников — очень демотивирующее занятие. Эта проблема элементарно решается организационными методами (например, давать только 2 попытки допуститься/сдать). Можно, конечно, решить нейронкой — препод генерит нейронкой задачу, студент нейронкой ее решает, все довольны:)
Нужны ли лекторы?
Ведь можно все что надо найти в интернете (ладно, можно не искать, сейчас все нейронка выдаст) и прочитать, да?
Удачи с поиском в мертвом интернете, да еще ровно в том объеме и ровно с нужного ракурса, чтобы усвоить материал по предмету в рамках нужной специальности.
Гугл сейчас дает “умные ответы от ИИ” на почти любой запрос — как вам, нравится?:)
Когда я учился, то вопрос полезности лекций и, в частности, качества донесения материала, тоже постоянно обсуждался. Правда, тогда учебник все еще использовался как дополнительный аргумент. Однако, однажды перед сдачей экзамена пришлось править статью в Википедии, потому что формула там была неправильная. А еще я был на очной лекции курсов повышения квалификации преподавателей, где нам дедок-лектор рассказывал про неэффективность очных лекций для передачи знаний.
Можно конечно посмотреть рандомного лектора на ютубе, вероятно индуса. Изменят ли тут нейронки что-нибудь? Ну окей, будет тебе трап-аниме-вайфу кавайным голосом рассказывать про символ Лежандра, может это улучшит усвоение материала на пару процентов в абстрактных попугаях, но не более того. А будет ли это стоить потраченной энергии?
И так далее
А еще есть бюрократия, мотивация преподов, миллион дополнительных обходных путей вроде сдачи зачета “нужному” преподу, вопрос “а нужно ли высшее образование вообще”, баланс практики с фундаментальными знаниями и т.п. Продолжать список проблем можно до бесконечности. В этом посте я накидал крупными мазками основное, чтобы проиллюстрировать мысль, но это только верхушка айсберга. Сейчас хорошим преподам приходится искать компромисс среди всего вороха проблем, чтобы хоть какой-то положительный след в умах учеников оставить. Диплом — это уже практически справка о том, что ты не дебил.
Эксперимент с режимом обучения в ChatGPT
Ладно, может, тогда нейронки могут заменить преподов и вузы? Вон, целую школу открыли для 4-5 классов, почти без людей, AI-driven!
А сравнительно недавно (3 месяца назад) ChatGPT представил режим обучения. Вводишь запрос, и нейронка сама тебе подберет программу обучения. Твой личный препод, полная персонализация, кожаные мешки больше не нужны! Вот только после релиза особо новостей про него что-то больше и не видел.
Решил попробовать — попросил ChatGPT рассказать, что такое О-большое в этом режиме. И, как ожидалось, это полная шляпа.
Знания выдавались очень поверхностные, какой-то сложности (кек) или глубины в них не было. Уровень рандомного видоса на ютубе. При этом не были даже упомянуты модели вычислений, элементарные операции, худшие/лучшие случаи, оценки памяти и т.п. Статья из Википедии даст больше контекста, да и страничка из учебника — тоже.
Адекватных проверочных заданий бот не дал, пока я явно не попросил. В итоге я получил… тест с вариантами ответа! Первый вопрос был уровня “Не в Москве ли находится Московский кремль?” Второй вопрос был примерного того же уровня, но вдобавок еще и был не совсем некорректно сформулирован. После третьего вопроса для даунов, бот предложил мне рассказать побольше про O(n log n). Я согласился, и тут мы резко перешли от “оцени сложность цикла” до объяснения, почему сложность сортировки слиянием — O(n log n).
Иллюстративный код был написан на питоне, в котором было копирование слайсов (что на асимптотическую сложность не влияет, но влияет на расход памяти и на реальное время исполнения). Я решил воспользоваться этим и попробовал загазлайтить нейронку, что сложность у этой паршивой реализации будет другой. ChatGPT в ответ каждый раз выдавал простыню текста и постоянно предлагал мне нарисовать картинку, но я игнорил его и настаивал на своем. Еще он пытался слезть с реального кода и вернуться к теории. В итоге я преуспел: мне удалось убедить его, что сложность сортировки слиянием это O(n² log n):
Реально в Python: c_copy(n) и c_merge(n) растут с n, поэтому наблюдаемое время работы может выглядеть как O(n² log n) или даже хуже, особенно при больших объектах или сложных типах.
“You’re absolutely right!” Уже на этом можно было эксперимент закончить. В моей практике неоднократно были ситуации, когда какой-нибудь студент был ну ооочень уверен в своей правоте. Я думаю, что текущие нейронки подобные кадры задушили бы с легкостью. Напоминает истории про то, как люди использовали ChatGPT как психолога/партнера и в итоге отъезжали в психушку/мир иной.
Под конец я добил бота парочкой каверзных блиц-вопросов из своих материалов. В целом бот справился, но у него была глубина ответа среднего студента, а не преподавателя или специалиста. С учетом того, что он генерирует простыни на простейшие запросы, мог бы и получше ответить.
Как все-таки использовать?
Получается, что нейронки для обучения в целом бесполезны? Нет, нужно просто использовать их с умом.
Я надеюсь, что каждый адекватный человек уже задался вопросом — если мои задачи может делать нейронка (при текущем уровне развития), то нафига я нужен? Разумеется, нейронку стоит использовать как инструмент, а не замену себе. Многим нравится еще аналогия, что они руководители, а нейронка — линейный сотрудник.
Но в таком случае, надо знать ограничения и понимать, когда нейронка генерирует дичь. Для этого надо обладать какими-никакими фундаментальными знаниями в области (в том числе, чтобы правильно сформулировать запрос) и уметь перепроверять выплюнутый результат.
Из этого вытекает учебное задание — попросить нейронку что-то сделать, проверить ее результат и перечислить ошибки/недочеты. Давным-давно такое еще на собесах использовали — найди ошибки в кусочке кода — позволяет неплохо оценить глубину знаний.
Причем идея проверки за нейронкой вовсе не нова. Есть история с реддита, и в МГУ есть положительный опыт подобного использования. Из очевидных плюсов — демистифицирует могущество ИИ и позволяет наработать практический опыт: для чего подходит, для чего не очень.
Итого
Еще в январе 2021, за год до первого релиза ChatGPT, я подготовил письмо о своем увольнении из вуза. Его я так в итоге и не отправил (проработал еще 3 года), но часть тезисов из него попали сюда. Основная идея была в том, что текущая система имеет недостатки, я устал и я в ней лишний. Без всяких нейронок.
Еще раньше, в январе 2020, преподаватели кафедры бурно обсуждали проблемы текущей системы. Многие проблемы, судя по мемчикам, за 5 лет особо не изменились (некоторые усугубились).
В общем, на мой взгляд, образование у нас уже давно катится в известное место. Проблемы связаны и усиливают друг друга. И это еще в моем вузе не такая страшная ситуация (хотя объективно есть места, где все же лучше и, можно сказать, не так уж и плохо). Нейронки могут добавить немного скорости к этому движению, но кардинально ситуацию они не поменяют. Безусловно, задача образования — адаптироваться к новым реалиям, но сначала нужно решить старые проблемы.
Еще немного Koka
Финальная (надеюсь) часть истории про Koka. Предыдущие части: первая, вторая.
По сути, доделал, что хотел доделать, и поэкспериментировал с чем хотел.
Получил обратную связь
Запостил ссылку на свой проектик, получил небольшой фидбек от одного из разработчиков. Мелочь, но приятно. Многого и не ждал, т.к. номер обсуждения — девять, и это первое обсуждение в категории “покажи свой проект”.
Когда переходил по ссылкам, внезапно узнал, что ссылки на обсуждения на GitHub имеют сквозную нумерацию с тикетами и PR в репозитории организации. Например, эта ссылка на первое обсуждение перенаправляет на первый PR.
Улучшил сборку
Отрефакторил пайплайн сборки — в итоге сам поиск собирается в релиз при публикации нового тега, и уже он используется при сборке сайта. Все обмазано кэшами. Попутно оптимизировал сборку, чтобы было не 60 мегов, а 31. По умолчанию все печально.
Посмотрел на action от разработчика и на разрабатываемый пакетный менеджер — ну, такое, мягко говоря… Остался на своих велосипедах.
Обновил версию языка и библиотеки.
Увы, особо много интересного не было, за исключением возможности использовать _ в лямбдах как в Scala.
Внес вклад в сообщество
Я открыл еще 8 (восемь!) тикетов, 5 пулл-реквестов и одно обсуждение с тупейшим вопросом. Как будто уже на них работаю, кек:) В библиотеки сообщества все быстро приняли, а в основном репозитории пока почти нет реакции.
Навалил фич
В первую очередь сделал префиксый поиск для последнего токена — наконец-то пригодилось ДДП!
Правда, пришлось писать самопальный поиск элементов, следующих за данным.
В стандартной библиотеке толком не используется факт упорядоченности map и никаких методов нет.
Вообще, уже одна эта фича улучшила поиск существенно. Несмотря на искусственное понижение результатов в выдаче, именно с префиксного поиска больше всего полезных результатов выпадает.
Пока вспоминал базу с ДДП, написал первые тесты. Не обошлось без проблем, но поправил сам, и получилось терпимо.
Наконец, написал стеммер. Смысла в нем не очень много, но изначально хотел его сделать и решил все-таки поставить галочку. Сам алгоритм оказался гораздо проще, чем я думал, практически вызов цепочкой однообразных функций с разными параметрами. До самих функций конечно надо додуматься, но на это не ушло много времени.
Уже на стадии чтения описания алгоритма я почти сразу придумал слово, которое будет плохо обработано: “карась” будет урезан до “кар” из-за возвратного “сь”. Поэкспериментировать самостоятельно можно тут, таких примеров можно найти много. Но многого ожидать от бесконтекстных стеммеров не стоит, да мне и не надо.
У стемминга есть нюанс, что он потенциально не очень хорошо сочетается с префиксным поиском для поиска длинных строк, но я не заметил разницы на реальных данных. Но у него есть и безусловный плюс — уменьшение размера индекса почти в 1,5 раза (JSON с индексом теперь 1,1 Мб вместо 1,6 Мб). Ну и точность ранжирования должна быть получше за счет объединения терминов.
Больше времени убил на борьбу со стандартной библиотекой.
Не смотря на то, что там есть проекция (view) строки, нужных мне методов там не оказалось, и доступа к отдельным символам по индексу тоже.
Я сначала честно пытался что-то построить с существующим API, но в итоге признал поражение и написал свою урезанную проекцию из велосипедов и грязных while с нужными мне методами.
Но на этом приколы со стандартной библиотекой не закончились.
Внезапно обнаружилось, что в ней нет flatmap для maybe.
Позже — совсем мрак: нет contains для списка!
Ладно, есть any, но это как вместо isEmpty писать .count > 0 (передаю привет C#).
Наконец, последней фичей стало переключение раскладки — “ns gbljh” чтобы искалось. Реализуется тоже элементарно, главное учесть, что смену раскладки надо сделать до токенизации (иначе всякие бюжъх потеряются), но после приведения к нижнему регистру.
Заключение
В целом, не ожидал, что после первой провальной попытки будет столько мотивации работать над этим проектом. Результатом я весьма доволен, получилось то, что я хотел. И что-то новое по дороге узнал, и со старых навыков сдул пыль. Надеюсь, что после пары минорных правок успокоюсь и переключусь на что-то другое:)
Мышки плакали и кололись, но продолжали есть Kokatus
Несмотря на проблемы с Koka, о которых можно почитать в первой части, я все-таки решил продолжить :/
Поддержка Юникода и сишная вставка
Начал я с потрахушек с сишной вставкой для поддержки Юникода — она не работала из-за undefined behavior, потому что я пытался использовать ICU библиотеку для изменения строки “на месте”, а чатгпт мне врал и газлайтил про сломанное окружение. Пока сам внимательно не посмотрел на код и не подумал, что может пойти не так, ничего не получалось. Справедливости ради, сама библиотека для Юникода, такое ощущение, тоже меня газлайтила — API у нее, мягко говоря, не очень, и пару раз я получал ошибки весьма сомнительного качества, которые скорее запутывали, чем давали понять, что не так. Но после того, как сделал микро-файлик с изолированной проблемой и догадался про UB, все относительно быстро решилось. Пиковый опыт разработки на сях + пиковый опыт общения с “ИИ” помощником.
Были еще проблемы с тем, чтобы понять, что нужна статическая линковка, откуда взять библиотеки, откуда взять C++ библиотеку, можно ли как-нибудь это не руками делать и т.д.
Отдельной историей была попытка разобраться с менеджерами пакетов, conan и vcpkg, но это какая-то своя вселенная с типичным (херовым) UX, и я быстро решил эту идею свернуть, так как еще разбираться подробно с ними и их интеграцией в Koka — нет, спасибо.
Даже по вайбу — в одном тебя лягуха JFrog встречает с пикой точеной с установкой через pip, в другом — мелкомягкие с установкой через git clone и несколько ручных действий.

Я еще подумывал о том, чтобы поправить пулл-реквест по итогам обратной связи, которую мне все-таки дали, но решил, что покрывать все нюансы практически вслепую — так себе опыт, и отложил это дело когда-нибудь “на потом”. Тем более не могу сказать, что почувствовал четкость и уверенность в ответе — как бы потом еще раз переделывать не пришлось.
Парсер JSON
В момент написания собственно поиска я осознал, что в ни в стандартной библиотеке, ни в библиотеке от сообщества нет парсера JSON. Только писатель.

Ладно, ладно, что-то есть, но это выглядит настолько не очень, что лучше бы его и не было.
В какой-то момент я хотел написать свой кастомный текстовый формат для сериализации, но потом все же решил написать свой мини-парсер JSON, без вещей, которые мне не нужны. При этом какие-то функции для преобразования JSON в нормальный тип в стандартной библиотеке все-таки есть, и если приправить их щепоткой магии с имплиситами, работают они неплохо.
Парсер в функциональном стиле — интересная зарядка для ума, компилятор хорошо помогает с точки зрения покрытия различных состояний. Первую версию я написал относительно легко, она была уродливой, но моей, и, что самое главное, работала.

Не очень понравилось, что нет толкового копирования структур. Есть немного сахара, однако, как я понял, это не мой случай из-за того, что у меня типы-объединения. Хотя в каком-нибудь Котлине с sealed-классом и выводом типов это сработало бы без копипасты. Позже я немного отрефакторил код и копипасты стало не так много.
Фронтенд
Моя любимая тема:) Следующий челлендж — сделать что-то интерактивное, чтобы поиском можно было пользоваться на сайте. Для интеграции с браузером нет библиотек из коробки — ну, ничего, уже умеем делать внешние вызовы :)
{kind=link}
Думал было побыть модным и молодежным и скомпилировать все в WASM, однако для него на кой-то ляд нужны сишные библиотеки. Честно, даже не стал вникать, решил, что
Такое ощущение, что JS для фронта был сделал по остаточному принципу. По ходу выяснились какие-то достаточно детские болячки: например, при создании библиотеки игнорируется флаг пути вывода — алло, как мне ее использовать? Или, например, если вдруг у обертки и реального вызова в JS одно имя — здравствуйте, бесконечная рекурсия.
Состояние
Одним из проблемых вопросов, который возник почти сразу при написании морды — как хранить состояние (загруженный индекс)? Мы же в чистом ФП, при каждом запросе запрашивать и парсить JSON — отвратительно, т.е. его надо передавать как параметр к фунции. Вот только кто это будет делать и откуда? Функция по идее будет вызываться только при изменении поля ввода, т.е. вызываться браузером.
Я находил какие-то ошметки доков про то, как сделать что-то подобное в общем случае, но… ничего толком не понял, потратив кучу времени :/ Даже думал тупо забить: пусть передается вызывающим кодом, т.е. оставить небольшую обертку из JS, в которой будет изолировано все состояние и все эффекты. Задал вопрос на форуме, ни на что не надеясь, однако мне ответили быстро и по делу. Стало понятнее, но тогда я временно отложил это дело. А в итоге советами не воспользовался и выкрутился путем рефакторинга — состояние (индекс) в итоге хранится в замыкании, без дополнительных фишек языка и всего такого.
Превозмогаем fetch
Первая попытка запуска поиска была, разумеется, неуспешая, потому что
created : .koka/v3.1.2/js-debug-4de7e1/search__main.mjs
error : command failed (exit code -11)
command: node --stack-size=100000 .koka/v3.1.2/js-debug-4de7e1/search__main.mjs
А потом еще и
...
node --stack-size=100000 .koka/v3.1.2/js-debug-4de7e1/search__main.mjs
Segmentation fault (core dumped)
В итоге всемогущий print-debug вывел меня на fetch, который безуспешно пытался загрузить JSON-файлик с индексом.
Кажется, одна из проблем была связана с асинхронностью, поэтому я сначала решил пойти по “простому пути” и сделать вызов fetch синхронным.
“Вертел я еще в этом зоопарке с асинхронностью разбираться”, — подумалось мне.
Разумеется, так делать нельзя, зря что ли два цвета у функций?
А синхронный метод (XMLHttpRequest) устарел (да и выглядит уродско).
В итоге нашел адекватный способ и адаптировал его под свой случай.
Поковырялся немного, чтобы использовать голый async и не использовать unsafe-as-string, но это был провал.
Попробовал сделать еще нормальную ошибку при отсутствии файла.
Тут интересно, что расширяется стандартный интерфейс exception-info:
abstract extend type exception-info
con JSError(error: jsobject<any>)
Это круто, вот только доступа к типу нет, и его нельзя никак проверить/показать, потому что он не публичный. Уже когда писал эту статью, отправил PR с исправлением, вмержили сразу.
Верстаем
Когда разбирался с fetch, решил попробовать просто что-то абстрактное в браузере запустить, прямо из консоли, но не тут-то было: библиотеки компилируются в модули, к функциям внутри них получить доступ из консоли — нетривиально.
Штош… придется писать SPA и генерить HTML кодом (sic!).
По умолчанию вывод main идет в
<div id="koka-console" style="...">
<div id="koka-console-out" style="...">
<a href="https://ya.ru">test</a>
<br>
</div>
</div>
Причем с экранированием, т.е. просто выплюнуть HTML не получится. Пытался разобраться, как поменять эту обертку на что-то другое — это закопано в v1 библиотеке, которую еще и хрен подключишь.

В итоге решил, что не стоит это того, и решил через нативную функцию заменять код страницы. Это сработало. Получается, не просто будем генерить HTML кодом, но еще будем это делать в стиле реакта, когда весь HTML генерится браузером на лету. Best practice, однако (устаревший).
Пока разбирался с изменением кода, попутно нашел и библиотеку для генерации HTML.
Вот тут (наконец-то!) смог оценить подход с эффектами.
В компонентах с их помощью собираются элементы: билдер создает эффект, а build все “ловит” — выглядит очень круто, абсолютно ничего лишнего!
Из минусов — не очень расширяемо: например, на input нельзя добавить атрибуты и нужно использовать более низкоуровневое API.
Однако это можно исправить, не меняя сам подход, и скорее проблема малого использования библиотеки и обратной связи для нее.
В итоге я сам это и поправил.
С точки зрения стилей — сначала хотел сделать все с нуля, а потом подумал: нахера изобретать велосипед?

Переделал тупо теги и классы под то, что и так у меня на сайте, и загрузил CSS оттуда ужаснейшим методом. А единственное непокрытое место, ширину поля ввода 100%, тупо сделал inline-стилем: не делать же ради этого дополнительный файл.
Интеграция с Web API
Пробую запустить — не работает: не вызывается функция поиска.
При отладке выясняю интересную особенность — имена манглируются: do_search → do__search, search-frontend → search_dash_frontend.
Зачем — не очень ясно.
Было ли это проблемой?
Нет.
Потратил ли я на это время?
Да :(
Основная засада — импорты.
Наружу торчит только main.
Попробовал привязать вызов функции к атрибуту поля ввода oninput — мимо, потому что функция в области видимости модуля.
Ладно, попробуем через addEventListener — тоже мимо, потому что непонятно, как пробросить название вызываемой функции правильно.
Если пробросить саму функцию — то она как будто не вызывается :(
Нашел как сделать перезагрузку скриптов и вызвал функцию напрямую, получил исключение.
Поганый JavaScript не может нормально сказать, в чем проблема :/
Ошибка оказалась где-то в std_core_hnd.mjs — не определена переменная.
Т.е. видимо я ухожу из контекста Koka и не получается ничего сделать.
Ну, хотя бы научился редактировать скрипты в браузере.
Хотел сделать простенький репродюсер, чтобы отправить баг, а в нем все, сволочь такая, работает! Методом тыка выяснилось, что если в функции есть хоть один сайд эффект, то все, “усе пропало”. Было бы классно получить нормальную ошибку, и это минус интеграции языка с браузером.
Еще и JavaScript поднасрал своими API — потратил время на какую-то ерунду: одна и та же функция работала на кнопке, но не вызывалась на поле ввода.
Все для того, чтобы обнаружить, что правильное событие — input, а не oninput.
Разумеется хотя бы предупреждение в консоли показать слишком просто :/
Вдобавок есть небольшая проблема с типами: это тебе не TypeScript, в котором определил структуру типов и радуешься.
Тут определил структуру — получи [object Object].
Поэтому в коде остался унылый Jsobject(event).get-obj("target").get-string("value").
Все выше перечисленное чатгпт с точки зрения фронта сгенерировал бы за 1 простой промт, конечно.
Отлаживаем сам язык
В какой-то момент словил баг компилятора:
(1, 1): internal error: unable to read
CallStack (from HasCallStack):
error, called at src/Common/Range.hs:65:53 in koka-3.1.2-2NpoSf9Uv2JEsgjfT7jQ0Q:Common.Range
readInput, called at src/Compile/Build.hs:1317:40 in koka-3.1.2-2NpoSf9Uv2JEsgjfT7jQ0Q:Compile.Build
getFileContents, called at src/Compile/Build.hs:644:17 in koka-3.1.2-2NpoSf9Uv2JEsgjfT7jQ0Q:Compile.Build
moduleLex, called at src/Compile/Build.hs:631:43 in koka-3.1.2-2NpoSf9Uv2JEsgjfT7jQ0Q:Compile.Build
(1, 0): build warning: interface async found but no corresponding source module
При этом помогало удалить .koka.
Сузить проблему не удалось, поэтому много на нее времени не тратил.
Поборов интеграцию функции поиска с полем ввода, получил новый ворох проблем в лицо. Вот какая-то ошибка в КЧД при десереализации:
_mlift_init_10105/index__size< - search_dash_frontend.mjs:108:21
ReferenceError: $std_data_rbtree is not defined
Ну епрст, если еще и дерево хреновое, то это вообще жопа.
Обложился трейсами — теперь другая ошибка в другом месте, каеф.
string_fs_show - std_core_show.mjs:326:18
ReferenceError: $std_core_vector is not defined
В принципе “логично”, трейс выводит в консоль, функция вывода не работает — получаем ошибку. В процессе дебага увидел, что находится внутри встроенной строки — связные списки (бля, это жесть 🌚). Соответственно, работает это все не медленно, а ПИЗДЕЦ как медленно.
Ошибка с выводом поначалу пофиксилась… убиранием флага -O3.
Не, ну я конечно понимаю, что один из таргетов — это Си, но чтобы еще undefined behaviour из него тащить — это смело!
Оказалось еще, что даже с -O1 код работает медленнее, чем без оптимизаций вообще.
А вот фикс для работы с КЧД оказался просто конченным: добавить лишний импорт.
Это мне еще повезло, что ошибка на верхнем уровне в подконтрольном коде, иначе бы я не знал как это исправить.
Предыдущую проблему с show это не решило.
Поборов проблему с импортами, получил следующую ошибку (я уже в шаге от MVP, честно-честно, надо чуток потерпеть…)
Paused on exception
$regexExecAll - std_text_regex.mjs:128:25
TypeError: $std_core_types._vlist is not a function
Оказалось, что проблема даже не в сгенерированном JS, а… в обычном! Это баг стандартной библиотеки языка: метод вызывается из одного модуля, а по факту находится в другом.
Проверил через перегрузку скриптов тупейший фикс — работает :/ В итоге сделал микро-PR, чтобы починить, и его приняли за полчаса, ух!
На этом баги библиотеки не кончились — Юникод нанес еще один удар, теперь по регуляркам! В сях и шарпе они юникодные, а вот в JavaScript — нет, потому что флаг не поставлен. В итоге еще один пулл-реквест, который тоже относительно быстро вмержили.

Организация кода
До этого времени все было в одной папке и в дополнение к ней была помойка utils.
Захотелось более четко разделить ядро, фронт и вещи, специфичные для бложика.
Тут используется хаскелловский подход к импортам.
Вроде все ок, но красиво не очень получается: либо добавлять всю папку src, чтобы сохранить иерархию, либо добавлять используемые модули по одному, но тогда теряются префиксы.
С core еще ладно, но вот utils хотелось явно оставить.
В итоге оставил -isrc, тем более это все-таки best practice, как я понял.
Получил унылое:
src/extractor/extract.kk(44,37): type error: types do not match
context : serialize(index)
term : index
inferred type: index/index
expected type: core/index/index
но в итоге порешалось использованием везде правильного префикса для импортов.
Основная логика
Вы ведь все еще помните, что я поиск пишу, да?
В черновике заметки между пунктами выше у меня было “написал индексер”, “написал поиск” и т.п. Когда находишься в чистой абстракции, то и проблем не так уж и много. Скажем так, собственно логика поиска и “движка” была самой простой и беспроблемной задачей.
В первой итерации я сделал обычный TD-IDF.
Во второй итерации решил сделать чуть лучше — BM25.
С ним интересная оптимизация получилась: если известно k и b, то можно предвычислить коэффициенты.
Ради этого даже поддержку дробных чисел в парсер JSON добавил.
Еще одна ошибка с импортами
После рефакторинга получил еще одну ошибку, но теперь уже в индексаторе:
core/indexer(1, 1): internal error: Core.Parc.getDataDefInfo: cannot find type: std/data/rbtree/rbtree
CallStack (from HasCallStack):
error, called at src/Common/Failure.hs:46:12 in koka-3.1.2-2NpoSf9Uv2JEsgjfT7jQ0Q:Common.Failure
raise, called at src/Common/Failure.hs:32:5 in koka-3.1.2-2NpoSf9Uv2JEsgjfT7jQ0Q:Common.Failure
failure, called at src/Backend/C/Parc.hs:988:34 in koka-3.1.2-2NpoSf9Uv2JEsgjfT7jQ0Q:Backend.C.Parc
Failed to compile src/extractor/extract.kk
очень интересно и ничего не понятно :(
Причина оказалась во вспомогательной функции
pub fun values<k, v>(m: map<k, v>): list<v>
m.rb-map/values
Видимо, совпадающие имена в комбинации с псевдонимом типов не работали.
Возможно, из-за подобной ошибки были проблемы с импортами и в JS.
Заменить на квалифицированный .map/values не сработало, переименовать в get-values — тоже.
В итоге тупо переписал код, чтобы это не использовалось.
Обновление версии языка
Попробовал зарепортить ошибки с импортами — а они поправлены в последнем мастере! Отлично, попробуем обновить версию языка.
Пробую собрать из исходников — фигушки, не перепробрасываются cclibdir.
Пробую собрать из альфа-релиза — фигушки №2, \r в юникс-скрипте (sic!).
Дальше скрипт становится еще лучше!
./install.sh --url https://github.com/koka-lang/koka/releases/download/v3.1.3-alpha17/koka-v3.1.3-linux-x64.tar.gz
Installing koka v3.1.3 for ubuntu linux-x64
warning: unknown option "--url".
Installing dependencies..
Using generic linux bundle
Downloading: https://github.com/koka-lang/koka/releases/download/v3.1.3-alpha17/koka-v3.1.3-linux-x64.tar.gz
Т.е. жалуемся на неправильный аргумент (который есть в --help между прочим), а потом его используем :/
Зато после обновления (с 3.1.2 до 3.1.3):
- решилась проблема с
values(хотя уже не очень-то и нужно было). - внезапно отвалился
string/replace-all, но простоreplace-allнорм работает. - пофиксился ублюдочный баг с импортами в JS.
- за счет двух моих вмерженных PR можно было убрать костыли.
- даже проблема, из-за которой надо было
rm -rf .kokaделать, стала реже появляться (однако потом снова появилась с большей силой — теперь надо было иногда еще и демон компилятора убивать). - добавили метод
expectдляmaybe(правда, имя конченное), удалил свою реализацию вutils. - смог вернуть
-O3на фронте.
Bleeding edge разработка, епта!
Потом еще и версия 3.2.0 вышла, пока я сопли жевал со статьей, а потом еще и сразу 3.2.2. Там есть пара интересных фич, но я уже немного устал.
Имя проекта
Перейдем к самому главному!
Рабочим названием проекта было looKfor.
Оно было унылым.
Чатгпт предлагал всякую дичь, больше всего понравилось grepka.
А в итоге в Википедии нашел Klava Koka, до этого про нее вообще не слышал. Жена мне запустила 2 “известные” песни с телефона. Мне показалось, что цитата “Че тебе нужно” из “хита” с чумовым названием “ЛА ЛА ЛА” как раз подходит для проекта. Ну и сферическая баба Клава тоже должна знать, что где лежит.
Муки оптимизации JSON парсера
Моя реализация была медленной, но она работала. Решил попробовать как-то ее оптимизировать, потому что 10+ секунд — как-то совсем не комильфо.
Первую альтернативу попробовал сделать через нативный вызов JSON.parse — уж быстрее этого ничего не будет.
Однако поверх него была еще обертка по преобразованию JSON-объекта в JSON-объект Koka — по сути, большой if-else-if с проверкой типов и рекурсивными вызовами с конструкторами оберток.
Пробую запускать… и код прерывается в браузере без ошибки :(
Пробовал и так и сяк — ну не работает, и все!
При этом в консоли все работает нормально.
Я конечно понимаю, что JSON размером 1,6 Мб не так-то просто распарсить, но не настолько же:(
Убийцей оказался опять -O3.
Попробовал воспроизвести проблему с -O3 в изоляции — получилось плохо.
Методом научного тыка выяснил, что виноват async — он плохо взаимодействует с рекурсией.
Причем эта падла (эффект async) проникает в main, и как-то изолировать десериализацию, чтобы она была вне пространства с этим эффектом, не получилось.
Наконец, в дебаггере докопал до too much recursion
Какого лешего это раньше не всплывало — неясно.
Узнал интересности про рекурсию в браузере.
И понял, почему в консоли работало: там тупо поставлен больше размер стека вызовов: node --stack-size=100000.
Что делать с этим — не очень ясно.
Хотел попробовать использовать sslice (read-only view поверх строки) в первой версии парсера — стало уже не ФП, и все равно медленно.
Еще и оказалось, что в мутабельную переменную нельзя присваивать результат match — только “простое выражение”, чтобы это ни значило.
Решилось промежуточной переменной, но скорости все это не прибавило.
Еще раз попробовал переписать парсер, теперь уже в мутабельном стиле с sslice и рекурсией.
Открыл наконец, как можно сделать паттерн-гарды, однако счастье было недолгим:
because : guard expressions must be total
т.е. от мубального зависеть там нельзя. Но в итоге и эта реализация тоже оказалась медленной. Даже в консоли это было медленное говно, медленее любой из предыдущих реализаций.
Пробовал ускорить этот медленный вариант через оптимизацию вставки в списки (вставлять в голову, а не в конец) — стало быстрее, но не существенно. Никогда бы не подумал, что буду думать об этом в нормальном коде за пределами абстрактных лаб.
Попробовал vector-list из библиотеки сообщества — хуже моей обертки сработал.
Даже словил
mimalloc: error: buffer overflow in heap block 0x020080000580 of size 65528: write after 65528 bytes
Вернулся к первой попытке, ужасному ФП коду, впендюрил туда свой тупейший хак для списка — и это наконец заработало!
Получается, как будто зря писал еще две с половиной реализации.
Но благодаря этому узнал что-то новое и смог существенно упростить оригинальную реализацию.
А еще получил ачивку — сотый коммит в библиотеку сообщества.
В продакшен
Попробовал сначала встроить на сайт через iframe — господи иисусе, это такой ящик пандоры с разнообразными проблемами, что мама не горюй.
Очень быстро от этого отказался, обошел фиксом, что не тело документа меняется, а выделенный контейнер.
Ну и файлик на сайте, который создает контейнер и грузит основной модуль, все-таки пришлось сделать.
GitHub Action для сборки намястрячил примерно так:

На стадии экспериментов выяснил, что индексер работает медленнее при (это я тупанул и не учел, что индексеру еще скопилироваться надо).-O3, но это некритично, 20 секунд индексации сайта на холодном старте меня устраивают
Итого
В итоге эта лабуда работает!
Это было достаточно больно, но все-таки интересно. Фишку с эффектами таки удалось оценить. Какой-никакой вклад в опенсорс добавил.
Наконец-то, написал свои поиск и JSON-парсер! Еще в изначальном плане был стеммер, это проще чем думается, но решил все-таки отложить на попозже. А то так можно дойти до идей с поиском по префиксу, триграммам и хаком для неправильной раскладки…


UPD: у этой истории есть еще и третья часть.