Читать в телеге. Когда-то там были посты не только от меня.
Переопределение команд в git
Git — очень гибкий инструмент. Хоть по умолчанию его утилиты, такие как diff и merge, работают со всеми файлами как с текстовыми, это можно изменить. Например, можно переопределить драйвер для merge и мержить xml файлы менее болезненно. Или показывать diff для офисных файлов — один из моих студентов так диплом хранит (не приучен к латеху, увы).
Координационные модели в организации
Статья-указатель на оные. Вкратце, есть три группы моделей:
- Централизованные — для решения глобальных проблем и проблем координации: стратегии, стандарты, ценности, постановка целей, метрики и приоритезация.
- Основанные на конкретной роли — для редких случаев: менеджер глобальных проектов (программ), интегратор, контролер, разработчик стандартов.
- Для координации команд — самая большая категория, 17 штук.
По сути это паттерны для построения организации, которые можно применять для улучшения текущих процессов.
Переназначение клавиш в macOS
На маках отличаются не только горячие клавиши, но еще есть особенности поведения управляющих клавиш (например, Home и End). А еще там немного другая раскладка для русского языка.
Помню, при первом знакомстве с Ubuntu 6.10 в далеком 2007 году я по незнанию выбрал просто “русскую раскладку”, а не “Windows раскладку”, и у меня неплохо так припекло: почему это для набора запятой нужно нажать Shift + 6, а на привычном месте — слэш? Кто эту дичь придумал? Так вот, ее придумали в Apple:)
Нищеброды должны страдать, поэтому внешнее оборудование не от Apple мак поддерживает не очень хорошо. Например, дополнительные кнопки мыши в маке просто игнорируются, а для внешней клавиатуры нельзя без извращений использовать альтернативную маковской раскладку.
Чтобы как-то разобраться с этим безобразием, можно использовать Karabiner-Elements. UX у него удручающий, но зато с помощью заготовленных правил можно переназначить клавиши: сделать Home и End более привычными и включить 4-5 кнопку мышки.
А вот для исправления раскладки правила не было — странно, что его еще никто не сделал. Пришлось сделать самому. Разрабатывать свое правило было немного болезненно, потому что это голый JSON с кучей копипасты, и для установки локального правила надо использовать гиперссылку вида karabiner://karabiner/assets/complex_modifications/import?url=file%3A%2F%2F%2FUsers%2Fov7a%2FDocuments%2Fremap_ru.json с ручным удалением для обновления:( А еще в русской раскладке никак нельзя набрать обратный слэш, пришлось с этим смириться. Но в итоге мой PR приняли, а само правило можно найти тут.
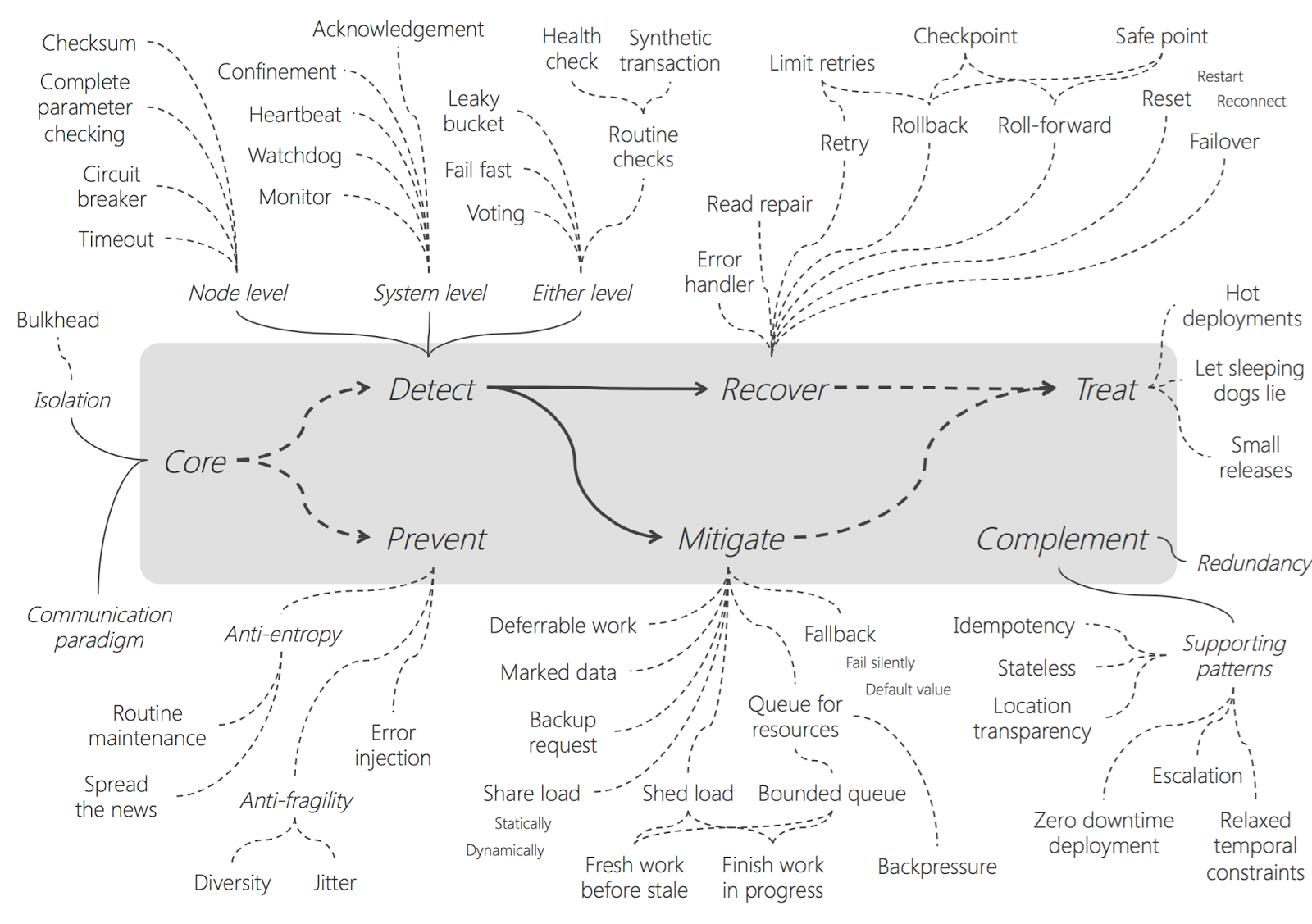
Паттерны обработки ошибок в микросервисной архитектуре
Узнал пару недель назад, что почти все стандартные операции обозваны паттернами:
- Timeout: не надо ждать ответа бесконечно.
- Deadline: вместо относительного таймаута делать абсолютный, чтобы цепочка вызовов работала адекватно. См. также про токены отмены.
- Retry: можно тупо попробовать еще раз.
- Circuit Breaker: вставляем прокси перед целевым сервисом, считаем ошибочные запросы. Если их много, то даем ошибку сразу, не спрашивая целевой, в течение какого-то периода.
- Fallback: если не получили ответ, придумываем его сами.
А если копнуть глубже, то паттернов устойчивости гораздо больше.
Самые сложные проблемы в разработке
…это организационные и процессные, а не технические. Технические задачи решать проще всего, там всего-то подумать надо нормально и время вложить. А вот организационные — это жесть, особенно если они на верхних уровнях: тут с людьми говорить надо.
Разработчики не могут исправить все проблемы управления. Типичные примеры: спускание идей или требований сверху; ответственность без соответствующей возможности; контроль без помощи; фиксация на сроках, а не пользе; отсутствие четких целей и т.п. Когда руководство умеет воспринимать обратную связь, это можно исправить, но с “я начальник, ты дурак” бороться, имхо, бесполезно.
Чисто функциональный QuickSort
Интересный доклад про оптимизации в функциональном языке программирования Roc от его автора. Он написал QuickSort в чисто функциональном стиле, который обошел по скорости мутабельный вариант на haskell. Перед перед этим автор дал очень хороший вводный обзор про варианты исполнения кода, боксинг, управление памятью и управление эффектами.
Доклад легкий, никаких эндофункторов, все сугубо практично. Конечно, пример немного синтетический, и релиза еще нет, но классно, что “обещания” ФП писать в функциональном стиле, “а компилятор разберется” становятся все более реальными.
Service mesh
Типичная микросервисная архитектура тащит за собой много обвязки для обнаружения сервисов, распределенной отладки (трейсинг, метрики), решения проблем надежной и безопасной отправки запросов, балансировки нагрузки и т.п. И для поддержки всего этого надо пихать библиотеки в микросервис, да еще и настраивать их. Даже если это единая экосистема (Spring Boot, Finagle, Akka, …), то она не решит всех проблем, особенно для гетерогенного стека.
Основная идея service mesh — вынести всю “служебную” мишуру из библиотек за пределы микросервиса, а в нем оставить только бизнес-логику. Это позволит многое стандартизировать, а разработчикам — сфокусироваться на основной функциональности. Основной вариант реализации — поставить перед каждым сервисом прокси и все служебные операции выполнять на нем, возможно с помощью управляющего сервера.
Разумеется, за все нужно платить: дополнительные абстракции жрут ресурсы, появляются дополнительные точки отказа, все это все равно нужно настраивать и отлаживать. Да и технология пока не очень зрелая, со всеми вытекающими. Подобно тому, что кубер-кластер не надо разворачивать ради полутора микросервисов, service mesh вряд ли оправдан в рамках одной команды: он скорее для больших организаций, которые в том числе могут себе позволить платформенную команду для его поддержки.
Чуть подробнее можно посмотреть в презенташке.
Как энтерпрайз убивает программирование
Жизненная заметка про то, как проекты по разработке ПО для больших организаций болезненно отражаются на разработчиках. TLDR:
- Проектная работа для нужд организации с фиксированным временем и бюджетом уныла. Иногда делают подпорку в виде команды эксплуатации, которая продолжает развивать ПО после завершения проекта, но это не решит проблему.
- Повальная стандартизация и спускаемая сверху архитектура препятствуют развитию разработчиков и приводят к неоптимальным решениям и вялому коду.
- Продуктовый подход лучше проектного, потому что ориентирован на долгосрочное развитие, и там можно позволить “риск” сделать что-то не квадратно-гнездовым методом.
От себя замечу, что тут отличие скорее не между “проектом” и “продуктом”, а в отношении к процессу разработки всех его участников: можно и в “продукте” пилить проекты, а “проект” продлевать каждый год. Это скорее спектр между “каждый выполняет только свою работу и строго по инструкции, никакого творчества” в бюрократическом и зарегулированном корпоративном монстре и “ты один, но зато швец, жнец и на дуде игрец, пофиг как и что будет завтра, лишь бы работало сейчас” в молодом, динамично развивающемся стартапе. Истина, как всегда, где-то посередине. А еще, разумеется, всегда актуален вопрос обратной связи: ПО нужно продавать. В энтерпрайзе его априори “купят”, потому что других вариантов нет, а сторонний покупатель может пройти мимо.
Слои API
В плохой микросервисной архитектуре сервисы обращаются друг к другу довольно беспорядочно. Чтобы как-то обуздать это безобразие, можно разделить все API на уровни.
Например, можно разделить все API на три слоя:
- системный (System), который инкапсулирует доступ к (каноническим) данным;
- процессный (Process), который инкапсулирует бизнес-процессы и бизнес-логику;
- слой представления (Experience), который представляет данные в удобном виде для потребителя.
Очень похоже на классический паттерн трехслойной архитектуры сервиса (база, сервис, контроллер), да и идеи в основе лежат те же. Стоит оговориться, что как и любой паттерн, стоит рассматривать этот подход как идею и термин, но не как постулат.
Безопасность SELECT
Что может страшного случиться, если вызвать SELECT? С лимитом, разумеется. Он же только читает данные, ничего не случится?
Через SELECT можно:
- вызвать хранимую процедуру/функцию, в которой может быть что угодно;
- обратиться к вычисляемому полю, которое в свою очередь может дергать функцию;
- выбрать запись для обновления и не отпустить лок;
- просто захватить лок (например, advisory-lock);
- вызвать агрегирующую функцию, которая затрагивает все данные, но возвращает один результат (поэтому лимит не поможет снизить нагрузку, но она может быть не критичной);
- вызвать перезапись данных: при записи большого числа блоков часть из них может быть вытеснена из кэша с необновленным битом статуса транзакции, любое последующее обращение к таким блокам (например, select) вызовет обновление этого бита (чтобы он соответствовал действительности) и, как следствие, вызовет перезапись всего блока;
- тупо “вымыть” данные из кэша;
- стриггерить триггеры (например, аудит).
Вдохновлено кусочком этого доклада, во многом помог Игорян, за что ему большое спасибо!