Читать в телеге. Когда-то там были посты не только от меня.
Улучшение streams
Классный доклад про будущее API streams (которое нужно для изменения коллекций в функциональном стиле). Рассмотрены фундаментальные штуки, сформулированы требования и обозначены трудности наивных подходов. Ну и представлено новое API из JEP, которое удовлетворяет требованиям и планируется в JVM 24.
Выглядит помощнее того, что есть в Котлине. Бойлерплейт все еще торчит, но выглядит более гибко и продумано. Насчет Scala — не знаю, там из коробки дорого-бохато, и что-то свое относительно нетрудно добавить. Но для Java — это просто космос.
Deepfake game
Пару лет назад: кекаешь над пальцами у нейросгенеренных фото.
Сегодня: не можешь пройти тест, сгенерирована картинка или нет.
UPD: игруля посвежее на ту же тему.
Генерация классов в Java: ASM и Class-File API
Неплохой технический доклад про различные способы генерации классов Java во время исполнения. Рассказано в том числе про то, как работают всякие прокси-классы в Spring и Hibernate, а так же новое API для этого в свежих JVM.
"Поиск" по научным статьям
В продолжении темы про мертвый поиск. Еще даже до написания того поста у меня была идея (вполне очевидная), что было бы прикольно написать поисковик по “достоверным” источникам (научным статьям, википедиям, официальным документациям и т.п.) и, возможно ссылкам первого уровня из них. У идеи куча минусов, но, казалось, что она будет работать лучше в некоторых сценариях, чем “обычный” поиск.
Поскольку эта идея не очень оригинально, кто-то это уже сделал — consensus.app.
Consensus is an AI-driven search engine that specializes in extracting and condensing scientific insights from peer-reviewed sources. The goal is to democratize access to expert knowledge and make science more approachable.
Звучит отлично! Жаль, что не работает:
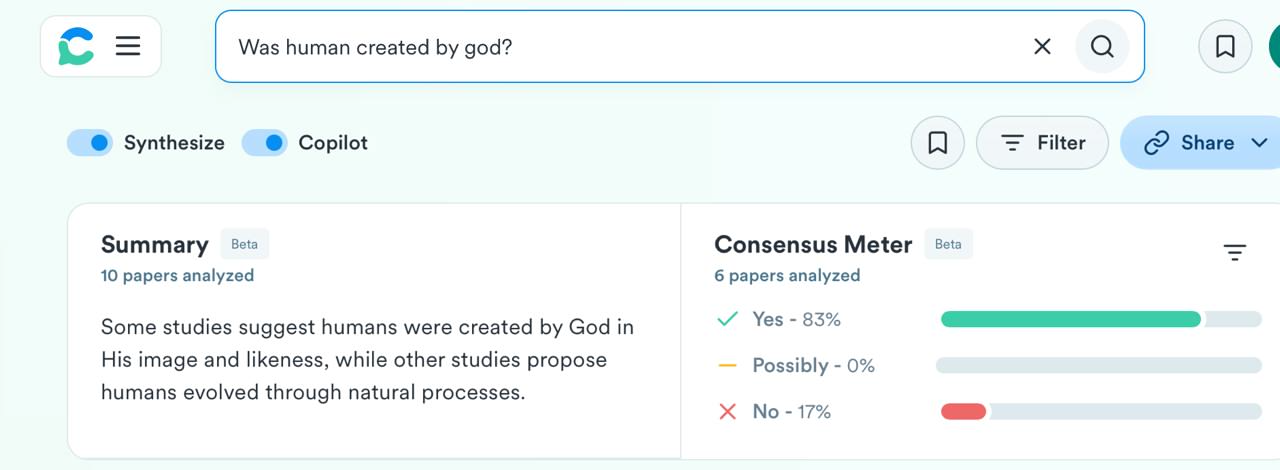
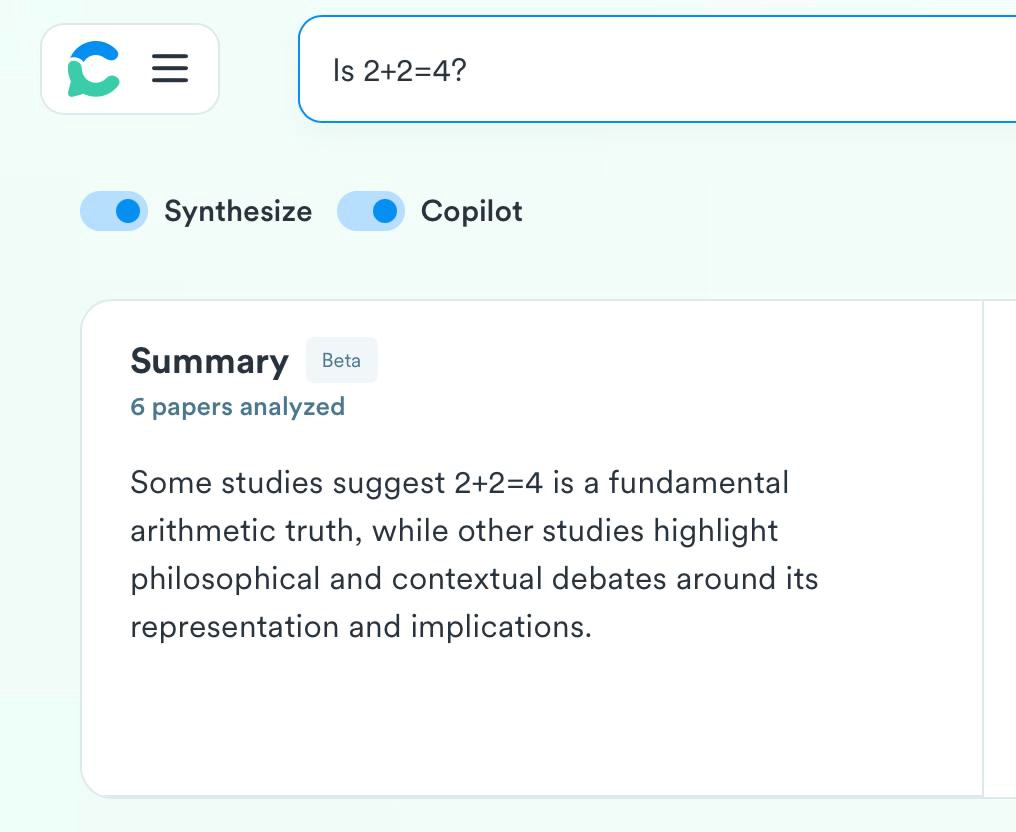
Что самое грустное, даже каких-то приколов и смешнявок не получилось сделать — я попробовал позадавать еще всякие “спорные” вопросы, но на многие из них поисковик говорил, что либо недостаточно данных, либо что “нужен нюанс” и “наши модели обнаружили сложный вопрос недостаточно точны чтобы дать ответ”.
На нормальные вопросы я получал так себе ответы, которые не сильно отличались от “обычных” результатов поисковика.
Сборник бесплатных API
https://www.freepublicapis.com/. В основном всякий мусор и что-то локальное, но есть и полезные вещи. Несколько примеров:
- API для
сборавалидации e-mail - API по вселенной Гарри Поттера
- Проверка, четное ли число
- Английский словарь — сам использовал в пет-проекте пару лет назад
- Картинки-заглушки
- Временные почтовые ящики
Впрочем, с учетом того, что сайтик попал в топ HN, есть небольшая надежда, что со временем там появится больше полезных ссылок (сейчас там 246).
Сборник советов по разработке своей CLI-утилиты
Сабж. В основном все советы годные и по делу.
Соответствие версии Java и версии class-файлов
Кто писал для JVM, встречался с Unsupported class file major version XX. Обычно это означает, что текущая версия java слишком низкая. Но какая версия нужна, например, для 55? Можно использовать табличные значения, но запомнить табличку или ссылку на нее — нетривиально. Проще воспользоваться формулой:
java_version + 44 = class_file_version
Обновление старой ветки
Если надо обновить свою фичу-ветку под новую базу, то это проще всего сделать с помощью
git fetch
git rebase <main-branch> --update-refs
Особенно это полезно, когда есть ветки от веток: update-refs рекурсивно обновляет все зависимые. На второстепенных ветках это приходится еще делать из-за того, что GitHub так себе отображает пулл-реквесты не от мастера.
Карта культурных различий
The Culture Map — довольно известная книга про то, как отличается рабочая культура разных стран. Пересказов в интернете полно, например 1 или 2, все можно свести к 8 шкалам.
В целом, как и любая книжка про паттерны — это скорее про общий язык, чем руководство к действию. Шаблоны помогают обсуждать вещи, но если все делать тупо по шаблонам, то вряд ли это приведет к хорошему результату.
Примеры, основанные на нациях, скорее вредны. Да, может и есть особенности культуры, которые более часто встречаются в той или иной стране, но многие могут ошибочно воспринять, что именно так и будут вести себя ВСЕ люди оттуда. Даже с учетом того, что у меня не такой уж большой круг коллег со всех работ, и большинство, разумеется, из России, я видел много примеров характеров со совершенно разными оценками по этим 8 шкалам. И иногда со своими старшими родственниками мы общаемся в принципиально разных “культурах”.
Вообще эти шкалы — это как с “типами” людей, со всеми их недостатками. Однако про книжку знать скорее стоит, ее (пересказ) можно использовать как один из источников вдохновения для осмысления инженерной культуры в команде.
Как Postgres хранит данные на диске
Довольно подробная статья, в которой про это рассказано.