Читать в телеге. Когда-то там были посты не только от меня.
Камеры на созвонах
Уже в нескольких утюгах обсуждают статью, в которой проводятся результаты нескольких исследований:
- 103 человека медицинской компании, по результатам 4 недель на основе опросов: люди устают больше с камерами, камера незначительно влияет на вовлеченность, женщины и новички от камер устают больше.
- опрос 10 000 человек, которые регулярно используют камеру на созвонах: женщины устают от встреч больше, более взрослые люди — меньше.
- 150 обучающихся: студенты на лекции, где были включены камеры, лучше сдавали тесты.
На мой взгляд, исследования недостаточно глубокие и разносторонние. Второе более-менее логичное (кому важно хорошо выглядеть в глазах других, тому тяжелее дается общение), но там нет контрольных выборок (созвоны без камер, очные встречи и т.п.). Еще стоит отметить эффект зеркала — если много смотреть на себя в “зеркало”, то это приводит к стрессу и тревожности. Третье исследование довольно узкое, а первое — наоборот, недостаточно подробное: у встреч могут быть кардинально разные цели. И ни в одном исследовании нет контрольных выборок.
В исследованиях плохо затронут вопрос повестки и качества встреч. Можно весь день провести на бессмысленных созвонах, куда тебя позвали просто “ну а вдруг надо будет”, где нет четкой повестки — там без камеры можно хоть своими делами позаниматься. А если на встрече все участники четко понимают полезность и необходимость, у встречи есть четкая цель — то там даже без камер будет продуктивно.
При этом многие источники указывают на то, что включенная камера повышает вовлеченность и помогает развивать эмпатию. Я в целом с этим согласен, но сначала стоит решить вопрос с необходимостью встречи. Добавлю, что вести семинар для студентов с выключенными камерами, где тебе отвечают 2-3 человека — очень грустно, не хватает обратной связи (особенно, когда на очном их меньше, но они активнее).
Версионирование библиотек
Интересный доклад про то, какая бывает совместимость между разными версиями библиотеками, как безопасно приносить новое и удалять старое.
Вообще целевая аудитория — разработчики библиотек, но и пользователям тоже полезно, чтобы понять, почему нужно писать всякие @ExperimentalAPI или @OptIn и как Kotlin дошел до жизни такой.
Как выиграть в "города" (России)
Ну, чтобы не запоминать все 1113 штук, разумеется. Обычная тактика — долбить в какую-то редкую букву (т.е. запомнить максимальное количество городов, кончающихся на определенную букву) или наоборот, запомнить кучу слов на “К” и на все редкие. Ну или не играть в такие игры вообще :)
Можно проанализировать граф: скачать с Википедии список (использовав, например, готовый парсер таблиц). А вот для визуализации можно использовать… непонятно что. Есть миллиард библиотек на питоне и js, но это ж код надо писать. Есть онлайн-инструменты типа CosmoGraph, но опций там кот наплакал. Пришлось расчехлять Gephi, чтобы обнаружить, что в нем нельзя отобразить нормально петли или экспортировать в GraphViz. Но лучше я ничего не нашел (если есть что-то прикольное, посоветуйте, пожалуйста).
У меня была идея найти гамильтонов на всем графе слов, чтобы найти непрерывную цепочку городов, но простейшие размышления привели к выводу, что такого пути нет. Да и анализировать граф игры удобнее, когда вершинами являются буквы, а ребрами — слова (как на картинке).
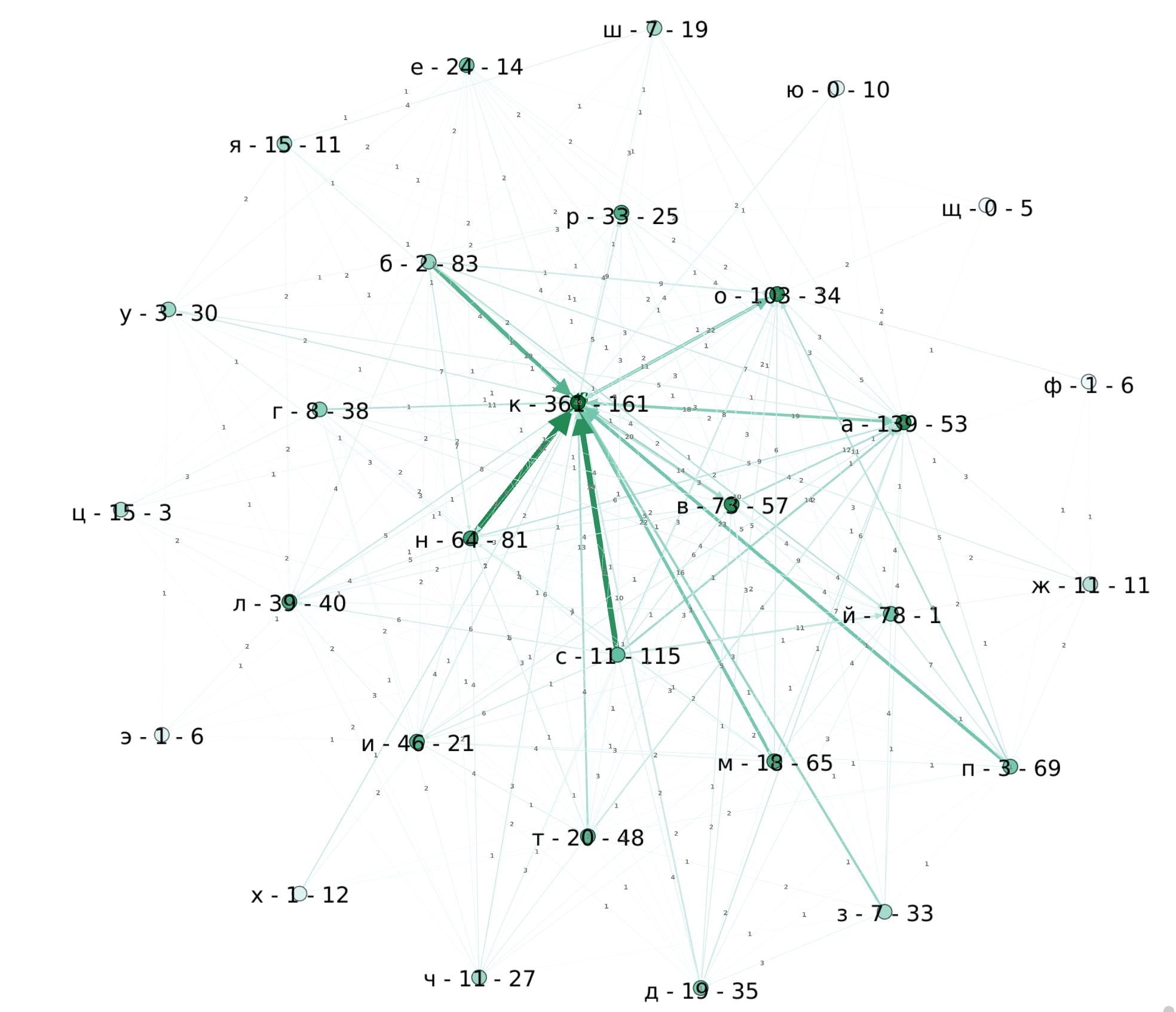
Из интересного:
- на “Й” начинается только Йошкар-Ола, а кончается — масса других. Но если приравнять “Й” к “И”, то будет тяжело.
- лидеры по окончаниям вполне ожидаемо “К” и “А”, а также “О” за счет бывших деревень и “В” в честь людей.
- хороший кандидат на редкую букву — это “Ц”. Вряд ли кто вспомнит 3 города: Цивильск, Цимлянск и Циолковский, а вот запомнить самому Череповец, Люберцы, Елец, Луховицы, Сланцы — легко (и еще 10 будет в запасе).
- еще можно попробовать долбиться в букву “Я”, но там 15 кончающихся против 11 начинающихся — надо будет специально запоминать (впрочем, кроме Якутска и Ярославля без подготовки тяжело что-то назвать).
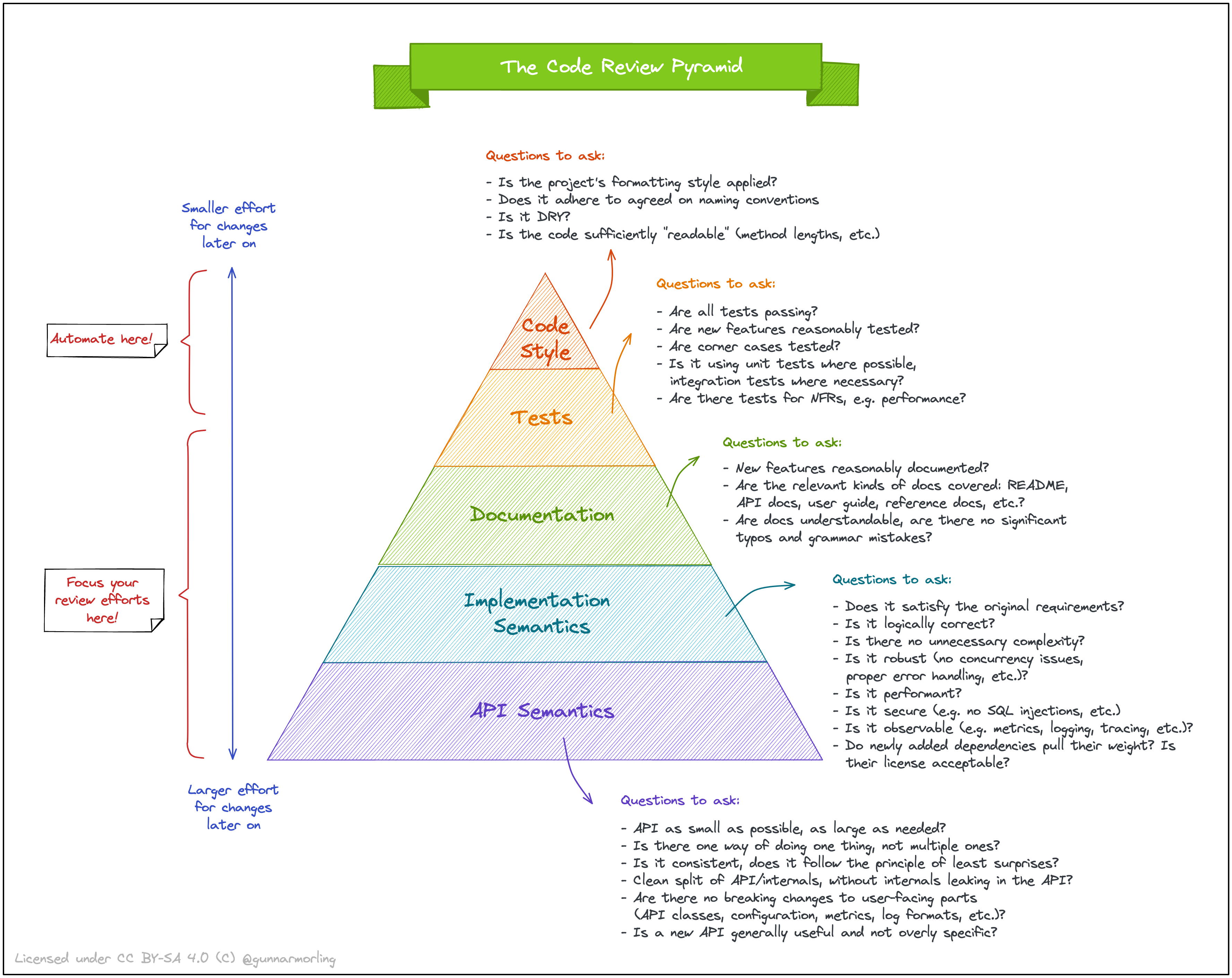
Пирамида код-ревью
В продолжение темы про код-ревью — шпаргалка про то, чему стоит больше уделять внимание.
{kind=link}
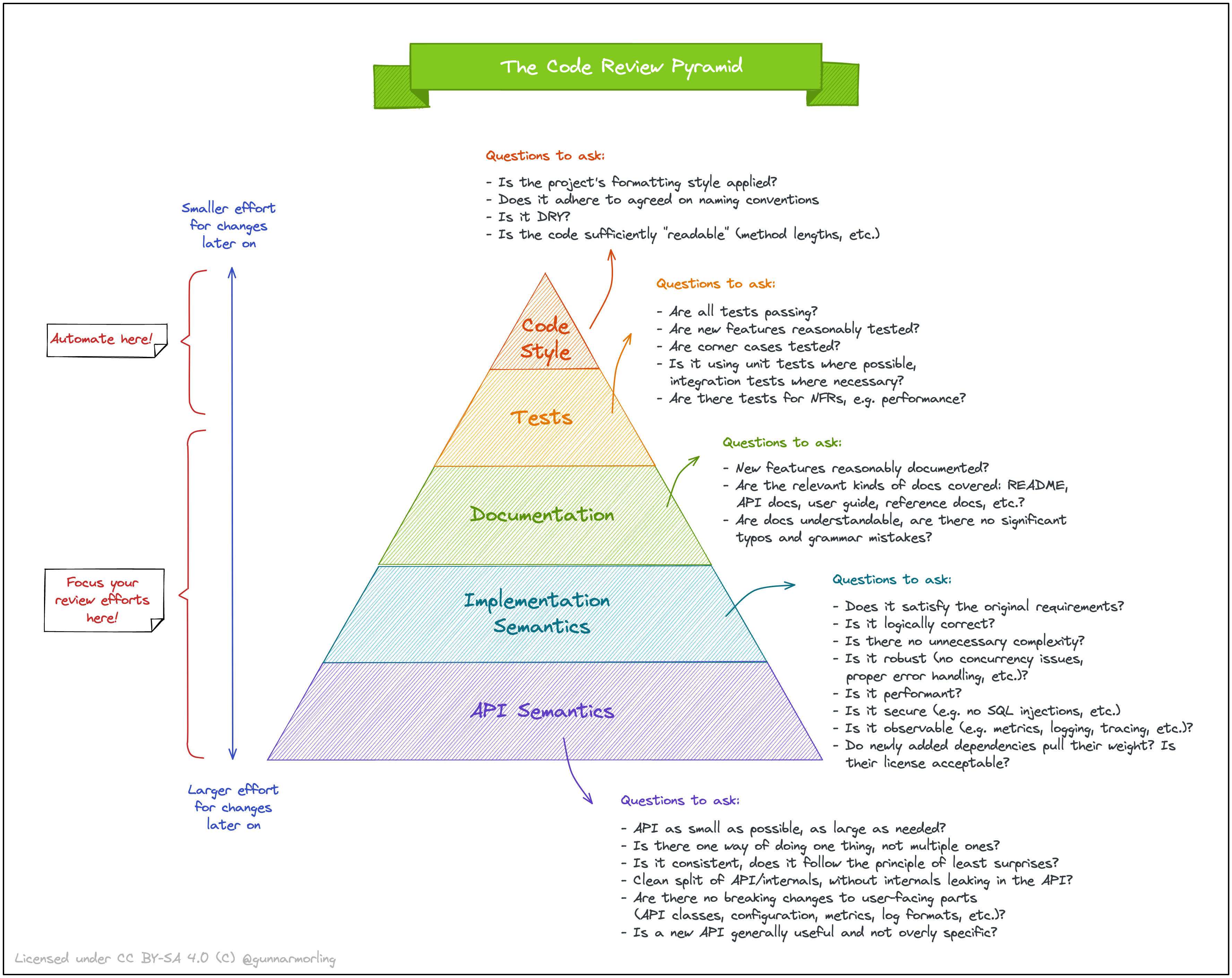
Отмечу, что она ничего не говорит про порядок проверки. И, разумеется, работает только при налаженном процессе: если кто-то хреначит коммиты в основную ветку без CI (потому что “знает, как надо”), а документации нет (даже в формате OpenAPI), то говорить тут о качестве ревью рано. Кроме того, тут еще не покрыт вопрос качества требований и их осмысления/анализа.
Миграция очередей в RabbitMQ
Как известно, в RabbitMQ не все настройки очереди можно изменить после ее создания. Но что делать, если все-таки понадобилось их поменять — например, если были изменены настройки TTL или добавлена dlq?
Одно из решений — делать все на стороне клиента или на уровне сообщений, чтобы самой очереди вообще не нужны были настройки. Но это скорее велосипед, который чреват багами (если этот велосипед пишете вы).
Другое “простое” решение — временно остановить работу с очередью, потом куда-то временно переместить данные и пересоздать ее. Увы, тут страдает доступность приложения и можно потерять данные.
Более продвинутые варианты вертятся вокруг создания новой версии очереди — в новом vhost, exchange или просто с новым именем. Зависит от потребителей и схемы релиза, но общая идея одинаковая — создать новую очередь, переключить все на нее, переместить все сообщения из старой (с помощью Shovel, например) и удалить ее.
В моем текущем проекте используется версионирование exchange и это отражается еще в имени очереди. Если надо поменять настройки, то перед релизом увеличивается версия настроек, создается новый exchange и очереди. После процедуры релиза запускается утилита, которая создает shovel’ы для переноса данных из очередей “неправильных” версий, ждет их завершения и удаляет старое. Что не удалилось — можно посмотреть ответственному за релиз.
Дополнительный плюс такой схемы — новые инстансы производят и потребляют сообщения только в своем контуре, который не как не связан со старыми инстансами.
Keep alive для ssh
Подключаешься такой по ssh к серваку, отвлекся на пару минут, возвращаешься в консольку с ssh, а она уже на ввод не реагирует. Бесит жутко.
Чтобы такого не было, можно настроить keep alive на сервере (но кто ж вам даст) или у себя в ~/.ssh/config:
Host *
ServerAliveInterval 200
Почему это не включено по умолчанию — загадка :(
Dead letter queue для очередей RabbitMQ
Простейший вариант обработки сообщений из очереди — слать ack после успешной обработки и nack с requeue=true при временной неудаче.
Однако такой подход работает только для временных/разовых ошибок, при серьезной проблеме потребитель будет пытаться обработать сообщение до посинения с маленьким интервалом между попытками.
Чтобы этого избежать, можно создать для таких сообщений специальную очередь — dead letter queue (dlq) и для серьезных ошибок слать nack с requeue=false.
А чтобы сделать несколько попыток, для каждого сообщения в dlq можно назначить TTL, и установить в качестве dlq для dlq оригинальную очередь.
Тогда при истечении TTL сообщение из DLQ попадает обратно в оригинальную очередь с заголовком, содержащим число “смертей”.
Потребитель может проверять это число и, если оно превысило предел, не обрабатывать сообщение совсем, но послать ack.
Таким образом, TTL для dlq служит интервалом между попытками.
Если в сообщениях есть ценная информация и выкидывать их совсем нежелательно, то при превышении числа попыток потребитель может их складывать в третью очередь (parking lot) для последующего ручного исправления.
С точки зрения настроек RabbitMQ нужно добавить к параметрам оригинальной очереди
x-dead-letter-exchange = ""
x-dead-letter-routing-key = "dlq_queue_name"
а к параметрам dlq
x-dead-letter-exchange = ""
x-dead-letter-routing-key = "original_queue_name"
x-message-ttl = 100500 # milliseconds
В обоих случаях используется стандартный обменник, чтобы перенаправлять сообщения напрямую. TTL можно еще устанавливать для каждого сообщения индивидуально (если хочется иметь экспоненциально увеличивающуюся задержку), но это придется делать уже на стороне потребителя.
Разумеется, возможны и другие сценарии (с общей dlq для всего, например), но описанный — один из самых простых.
Выбор коммита для добавления изменений в git
Одна из устоявшихся практик добавления изменений — rebase + fast-forward. Часто со схлопыванием всех коммитов в один жирный. История конечно получается красивая и это просто, но сваливать в одну кучу бизнес-изменения и рефакторинг — так себе затея, атомарные коммиты все-таки не зря придумали.
Но тогда после очередного rebase на основную ветку может возникнуть проблема, когда ваши красивые коммиты перестают компилироваться (например, кто-то тоже порефакторил от души).
И после этого делать коммит fix after rebase или лепить все исправления в последний коммит через --amend как-то уныло.
В этом случае поможет --fixup:
git add someChangedFiles
git commit --fixup=OLD_COMMIT_HASH
git rebase --interactive --autosquash OLD_COMMIT_HASH^
который позволяет добавлять изменения в существующий коммит, даже если он не последний.
Порядок просмотра файлов при код-ревью
Довольно интересное исследование показало:
- Большинство разработчиков ревьюят изменения тупо по порядку следования файлов (и обычно это алфавитный).
- Тесты комментируют реже, их качество обычно меньше волнует разрабов.
- Если тесты ревьюить после основного кода (как это обычно происходит, потому что
t— в конце алфавита), то в них реже находят баги (для основного кода существенной разницы нет). - Больше всего комментариев оставляют к первым файлам в списке, и баги в них обнаруживают с большей вероятностью.
В общем, сначала ревьюер смотрит внимательно, потом расслабляется, а тесты смотрит уже наискосок. Вроде довольно очевидно, но теперь на это есть пруфы. И это на фоне того, что лишь сравнительно недавно GitHub сделал функцию просмотра дерева измененных файлов (я еще в январе на это жаловался).
Добавлю, что еще в далекие года ведущие эксперты™ писали в своем супер-мануале про порядок просмотра при ревью: тикет, тесты, код, тесты. Потому что на ревью важнее выявлять фундаментальные проблемы: неправильные требования, сделано не то, работает не как надо и т.п. И уже во вторую очередь идут ошибки в реализации. А для всякого форматирования и прочей мелочевки должен быть линтер, а не человек.
Ковариантность и контравариантность
У меня всегда были трудности с запоминанием умных терминов, хотя суть вариантности довольно проста. Если иерархия типов сохраняется в том же порядке для производных типов (которые используют искомый тип как параметр), то это (ко)вариатность. Если идет в обратном порядке — (контра)вариантность. Если нет иерархии — (ин)вариантность.
Если термины из теории категорий — “сложна”, то можно мыслить в терминах потребитель/производитель, в Kotlin и C# параметры так пишут — in и out вместо всяких плюс-минусов, и это гораздо читаемее.
