Читать в телеге. Когда-то там были посты не только от меня.
.new домены
На сессии группового программирования коллега создал новый Google Sheet с помощью sheet.new (не спрашивайте, как таблички связаны с программированием).
Это тупо редирект, но все равно прикольно и явно удобнее, чем заходить через Drive.
.new — это один из TLD-доменов Google, и там есть аналогичные “ярлыки” для прочих сервисов гугла. Но и другие компании имеют сайты на этом домене. Полный список ведет сам гугл. Все это появилось в основном в районе 2019 года, но я как-то пропустил. Набор довольно сомнительный, о большей части компаний у нас и не слышали, а достаточно заметное количество доменов уже не работают.
Что потенциально интересно/бросилось в глаза (кроме гугловских ссылок):
Шпаргалка по Gradle
Если надо быстро объяснить основные термины и суть, то вот неплохая страничка, которая весьма практично написана, без воды.
Новый движок для регулярок
Очень интересная статья про новый движок для регулярок.
Авторы изначально хотели поддержать возможность пересечения и дополнения регулярок (и в статье есть хороший пример с проверкой ограничений для пароля), но чтобы на статью обратили внимание, упоролись по производительности и получили еще хороший выигрыш по скорости по бенчмаркам, достигнув при этом линейной асимптотики (как я понял, ReDos не грозит).
Одним из открытий для меня стало, что в PCRE-регулярках (т.е. почти везде) (a|ab)+ и (ab|a)+ — не одно и то же, и варианты рассматриваются жадно слева направо. Из-за этого для aababaabab первая регулярка выдаст aa, а вторая — всю строку.
Пишите в поддержку
У меня как-то сложился стереотип, что писать куда-то с обращениями — это обычно спортлото. Но мне тяжело объяснить почему. При этом у меня есть успешные истории, расскажу о трех из них.
Первая — из 2016 года: попросил Мосгортранс перенести остановку трамвая — перенесли через пару недель! Через год-полтора вернули обратно, а сейчас ее уже вообще нет, но все равно результат был достигнут.
Вторая — прошлогодняя. Полугосушная программа выдавала ошибку, к счастью довольно подробную (0x3b56abcd != 0x3B56ABCD). Я искал варианты решения в интернете, пробовал ставить версии под другие ОС и т.п., в общем, пытался сам решить. Нашел что как-то через жопу можно сделать, что мне надо. Даже думал о том, чтобы отредактировать бинарник, чтобы эту проверку отключить. Чисто по приколу написал на почту. Причем не каким-то разрабам, а в контактный центр — т.е. в максимальную помойку. Во-первых, мне ответили! Отвечали мне с пингом в пару недель, и из серии “переустанови, перезапусти”. Но на третий раз, когда я им выслал логи, скриншоты и какую-то лабуду, они… сделали новую версию! И она РАБОТАЕТ.
Наконец, самая свежая. Пару лет назад выяснилось, что stale бот на GitHub реализован очень тупо: делает полный перебор всех тикетов вместо фильтрации. Ну, открыл им тикет, написал свой action (все равно сценарий отличался) и забыл. В октябре мой action стал регулярно падать с “Something went wrong”. Написал в поддержку, долго с ними бодался, потому что они меня газлайтили, что это мои запросы кривые, а не их инфра, которая, судя по всему, тоже делает полный перебор вместо фильтрации. Выдавил из них обещание “передать разработчикам”. А феврале все внезапно “починилось” и поддержка вскоре отписалась, что теперь все ок.
В общем, иногда в поддержку писать все-таки имеет смысл.
Сложность: что посеешь, то и пожнешь
В каждом утюге уже было это видео про то, как все сложно, пусть будет и в моем. Слишком уж жизненно.
Мем смешной, а ситуация страшная. На той же неделе вышла еще годная статья про то, что никто особо и не поощряет простые решения: за “простоту” не повысят, да и на собесе надо второй гугл/убер/букинг/твиттер спроектировать за час. Кучу историй про проекты и дебильные решения, которые затевались чисто ради повышения в бигтехах, можете найти сами. Все по классике: награждаем тушителей пожаров и “усилия”, а на полировку и упрощение — забиваем.

Проблема, разумеется, далеко не нова: тут, например, можно вспомнить и старую классику про “добавить кнопочку” (чтобы еще на выходе и не было понятно, это PHP или React). Вот еще докладик из прековидной эпохи в тему: все привыкли к багам, технологии деградируют (приведен пример с боингом, пророчески получилось), абстракции погоняют абстракциями, и все это — ценой железа. Жаль, что докладчик не предложил, что делать со всем этим.
{kind=link}
Некоторые надеются, что высокие цены на комплектующие поспособствуют более вдумчивому использованию ресурсов. Удачи им с этим в мире, где текущий тренд — это не читать код, который написал ИИ :)
X86 на чистом CSS
Сабж. К сожалению, работает только в хромиумах, но все равно прикольно.
Тьюринг-полнота HTML+CSS — не сюрприз, да и игры давно делают. Однако забавно, что старая смешнявка не сильно потеряла актуальность.
{kind=link}
ИИ-результаты — скучные
Неплохая заметка, можно даже сказать капитанская, про то, что чатботы не генерируют оригинальных мыслей, поэтому их вывод будет по определению скучным, средненьким и поверхностным. Для областей, где вы не специалист, это сойдет, однако зарождение мыслей требует мыслительного процесса и погружения в проблему.
К сожалению, автор упустил, что для многих бизнесов скучно и предсказуемо — это как раз большой плюс :/ Но с “предсказуемо” у чатботов пока все не очень хорошо.
UPD: Рома отлично расписал еще один, более важный, упущенный момент.
Никто не против?
В компаниях с незрелыми процессами и/или так себе инженерной культурой может возникнуть такое явление как необязательное одобрение: вроде как процессы недостаточно жесткие, чтобы кто-то мог заблокировать что вам надо, но и недостаточно гибкие, чтобы вы могли просто сделать что нужно (“а вдруг?”, “надо бы эту команду спросить” и т.п.). При этом может случится так, что это одобрение где-то в помойке по приоритетам у того, кто его должен дать (иногда могут даже не снизойти до банального ответа хотя бы уровня “сорян, ща занят, посмотрю на следующей неделе” :harold:).
В некоторых случаях мне помогает переформулировка вопроса в формате “никто не против, если …?” Таким макаром, бездействие или отсутствие ответа будет одобрением. Эффект выбора по умолчанию в чистом виде. Еще можно вспомнить “проще попросить прощения, чем разрешения”.
Откуда вообще взялись эти уровни Junior/Mid/Senior и т.п.?
Когда задумался над этим вопросом, первой мыслью было, что подобное разделение пошло от военных (типа старлеи и младшие офицеры): все-таки, изначально инженеры — это операторы разнообразной военной техники. Однако оказалось, что разделение на 3 уровня квалификации (новичок/младший, обычный и опытный/старший) было почти всегда, и можно даже конкретные термины senior/junior отследить сквозь века. Например, вот должности на проекте по расширению нью-йоркского метро в 1910-х и ранги клерков британского МИДа в 1822. При желании, можно дойти и до Римской Империи, где схоларии были “seniorum” и “iuniorum”, или вообще натянуть на 3 уровня ученика, подмастерья и мастера.
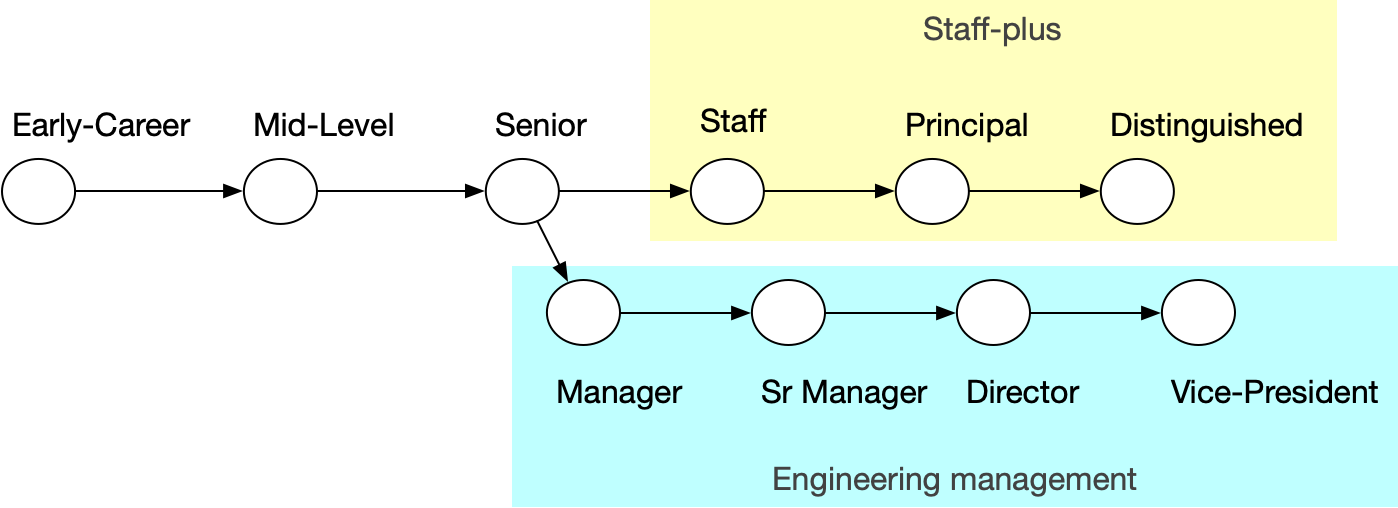
А вот всякие Staff и Principal — это скорее уже чисто айтишная тема, хотя подобные термины и были раньше. Например, вот требования к Principal Engineer в Англии от 1683 года, а вот вырезка из газеты 1888 года с упоминанием Staff Engineer. Судя по всему, текущий де-факто стандарт ветвящейся карьерной лестницы — это изобретение бигтеха, когда надо как-то повышать специалистов, но при этом не нагружать их управлением людьми.
{kind=link}
Разумеется, все эти лычки — очень условные. Даже если какая-то формализация требований и есть в компании, то всегда найдется повод не повысить именно вас. Миддл из одной компании может знать больше, чем сеньор из другой, а джун из третьей может получать больше их обоих.
Все это словоблудие было лишь для того, чтобы понтануться, что я теперь Staff Engineer:)
CRIU
CRIU — Checkpoint/Restore In Userspace — утилита для сохранения и восстановления состояния запущенного приложения/контейнера, разработанная “by various mad Russians”. Что-то вроде управляемой гибернации, но только в пользовательском пространстве.
Киллер-сценарий — сохранение состояния приложения и восстановление его на другой под в кластере, со всем контекстом — при благоприятных условиях, это значительно снижает потребление ресурсов (не надо контекст с нуля восстанавливать) и время простоя (не надо долго ждать, пока поднимется новый под).
Попробовать самостоятельно можно по этому туториалу.