Что внутри у мягкой ссылки
На примере ext4. Краткая справка: с каждым логическим файлом ассоциирован inode, который хранит его метаданные: права доступа, атрибуты, указатели на блоки с данными и т.п.
Признак того, что файл является символической ссылкой, хранится поле mode в inode: у обычных файлов это 010xxxx (в 8-ричной системе; xxxx — это unix-права вместе со sticky битом), а у символических ссылок — 012xxxx. А путь ссылки хранится в данных. Т.е. ссылка — это просто текстовый файл, у которого выставлен специальный флаг.
Но есть нюанс. Подобные ссылки будут не очень быстрыми, т.к. надо сначала прочитать метаданные, а потом пройти по указателям на блоки и прочитать собственно путь. Поэтому придумали оптимизацию, чтобы хранить путь прямо в метаданных, если он достаточно короткий (меньше 60 символов). Подобное можно применить и к обычным маленьким файлам, если файловая система была создана с флагом inline_data.
Перейдем к практике.

Для безопасного эксперимента можно воспользоваться утилитой debugfs. Создадим файл с ФС:
dd if=/dev/zero of=ext4.img bs=1M count=100
mkfs.ext4 ext4.img -O inline_data
mkdir mnt
sudo mount ext4.img mnt
Заполним данными
sudo echo -n "some text" | sudo tee mnt/original.txt
sudo ln -s original.txt mnt/short_link
sudo ln -s very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_long mnt/long_link
sudo echo -n "original.txt" | sudo tee mnt/manual_link
Получили такое в ls -lF mnt:
lrwxrwxrwx 1 long_link -> very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_long
drwx------ 2 lost+found/
-rw-r--r-- 1 manual_link
-rw-r--r-- 1 original.txt
lrwxrwxrwx 1 short_link -> original.txt
Отмонтируем ФС и откроем debugfs:
sudo umount mnt
debugfs -w ext4.img
Начнем с простого — с длинной ссылки. Ей достаточно поменять mode:
debug_fs: mi long_link
Mode [0120777] 0100777
...
У короткой ссылки надо поменять mode, выставить флаг того, что файл содержит данные в метаданных и добавить расширенный атрибут, что это именно данные:
debugfs: mi short_link
Mode [0120777] 0100777
...
File flags [0x0] 0x10000000
...
debugfs: ea_set short_link system.data 0
Наконец, превратим текстовый файл в ссылку:
debugfs: mi manual_link
Mode [0100644] 0120777
...
File flags [0x10000000] 0x0
...
Сохраняем с помощью Ctrl + D и монтируем sudo mount ext4.img mnt. Вывод ls -lF mnt:
-rwxrwxrwx long_link*
drwx------ lost+found/
lrwxrwxrwx manual_link -> original.txt
-rw-r--r-- original.txt
-rwxrwxrwx short_link*
Содержимое ссылок:
$ cat mnt/long_link; echo
very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_long
$ cat mnt/short_link; echo
original.txt
$ readlink mnt/manual_link
original.txt
$ cat mnt/manual_link; echo
some text
Теперь вы знаете простой способ, как сделать символическую ссылку :)

Боль code quality
У меня сложилось впечатление, что как-то все очень плохо в индустрии с обеспечением качества кода, ну это или мне так везет. Несколько месяцев назад на предыдущей работе настраивал отображение покрытия тестами для PR в GitHub, с использованием Jenkins, JaCoCo и maven. Натрахался очень знатно: интеграции Maven ↔ Jenkins ↔ GitHub работали очень туго, постоянно были какие-то проблемы, которые лечились костылями (преимущественно помоечным кодом в Jenkins).
Недавно захотелось сделать аналогичную штуку в GitLab. Ну тут-то все должно быть нормально, правда же? GitLab ведь боготворит CI/CD… А на сoverage даже есть отдельный столбик в списке всех работ (кто туда правда смотрит — непонятно, потому что обычно пайплайн целиком интересует).
Форматирование и анализ кода
Ранее я уже поразвлекался с интеграцией проверок от ktlint и detekt в пайплайн GitLab. Тут было не очень прикольно: пришлось допиливать напильником конвертер формата ktlint в GitLab, писать кастомный gradle-таск, чтобы смержить два отчета о покрытии, потому что GitLab это не умел, писать кастомный gradle-таск, чтобы валить пайплайн, потому что GitLab нельзя настроить, чтобы он этот code quality отчет хоть как-то принимал во внимание, а не просто списочком отображал.
И да, про отображение. Чтобы отобразить проблемы красивенько рядом с кодом — ПЛОТИ. Нищеброды могут посмотреть только на список, ищи дальше по файлу и номеру строки сам. Чтобы хоть как-то это облагородить, добавили интеграцию с reviewdog, который оставляет комменты к MR.
Формат отчета
Берем Kover, плагин для gradle от JetBrains, который генерирует отчет с использованием того же движка, что и Intellij — круто же, если все будет одинаково работать? Спойлер — работает не одинаково, проценты разные получаются :(
GitLab поддерживает только формат Cobertura, который довольно древний, и я не нашел ни одного живого плагина для его поддержки в Gradle, что логично, потому что в Java-мире почти все уже используют JaCoCo. Что предлагает GitLab? Запустить отдельный контейнер, чтобы питонячим скриптом сконвертировать один формат в другой. Ответственное потребление энергии, однако. При этом GitLab не поленился сделать инструкции для нескольких языков, как конвертировать результаты, вместо поддержки других форматов. Ок, может Kover умеет делать отчет в нужном формате? Не умеет. Ладно, добавляем плагин gradle, это лучше лишнего контейнера.
Заливаем в GitLab как положено, смотрим на тестовый MR… И там ничего нет. Выясняется, что надо “немного подождать”, чтобы покрытие подсветилось в изменениях. Я конечно понимаю, что там микросервисы небось с микрофронтендами, но непонятно, что мешало сразу показать все.
Процент покрытия
Ладно, а как посмотреть процент покрытия? А его нет. Надо прописать его извлечение в пайплайне. Т.е. я предоставил полный отчет о покрытии тестами всего кода, и GitLab не может посчитать процент из него? Серьезно?
Как же GitLab узнает покрытие? Регуляркой из вывода пайплайна. РЕГУЛЯРКОЙ. Думаете я шучу? Я тоже думал, что на какой-то фейковый сайт зашел, но нет. Еще раз, я предоставляю GitLab полный отчет в нужном ему формате, чтобы он все равно брал процент из другого места. Консистентненько!
Кто же будет выводить это число? Kover, конечно не умеет. Придется писать всратый gradle-таск, который парсит XML-отчет. Парсить XML уже погано, а парсить его gradle-таском на kts через встроенный XML-парсер, заточенный под Groovy, — еще более погано.
Разница
Уф, процент вывели, как нам отследить разницу? Ну, чтобы понять, что общее покрытие стало лучше или хуже? Есть история, но это отдельное меню, в MR она не показывается. Единственный более менее внятный вариант — метрики. Их, разумеется, ничего генерировать не умеет, но благо есть парсинг отчета, можно добавить туда немного вывода в файл. Только потом заметил, что метрики — премиум-фича.
Но все покрытие целиком обычно не интересно смотреть, лучше смотреть на изменения. Тут казалось бы время выйти GitLab на сцену — он же знает все про то, какие строчки поменялись в нашем MR, и какое у них покрытие? Но нет. Накидываем еще кода в gradle-таск, чтобы у git спросить список изменений и посчитать все только для них (не забываем про приколы с точками и слешами в путях Kotlin-пакетов).
Обратная связь
Надо бы еще как-то более вырвиглазно пометить файлы с плохим покрытием. Для GitLab это просто космос, поэтому накидываем пороговые значения, выводим еще в один файлик отчета информацию о файлах с фиговым покрытием и кормим это reviewdog.
Вообще покрытие ради покрытия — так себе идея, это скорее проверка, что сделано не совсем хреново и подсказка на случай если что-то забыл. Но не переживайте, GitLab не умеет блокировать MR из-за низкого покрытия, поэтому можно мержить что угодно :) Ну или… писать кастомный gradle-таск (но на это я уже забил).
Итого
Хотелось казалось бы простой вещи — проверять форматирование, покрытие тестами и автоматизировать рутину code review. Чтобы смотреть на важное, а неважное подсвечивалось автоматом. Чтобы достичь этого с GitLab, понадобилось два gradle-плагина для конвертаций, 4 кастомных gradle-таска (всего на code quality потрачено 215 строк в build.gradle.kts), 40 строк в .gitlab-ci.yml и пяток промежуточных файлов. И ладно это все было каким-то стандартным бойлерплейтом, но нет. Без особых танцев подключились только результаты прогона тестов.
В итоге все конечно получилось, и жить стало веселее. Однако зрелость инструментов показывает, что либо этот путь многие повторяют, либо просто не парятся такими низменными вещами (“а чо, работает и ладно”). В обоих вариантах звучит грустно.
Leetcode — это скам
Попробовал порешать задачки на LeetCode — посмотреть, что можно студентам дать, и вдохновиться, как сделать ejudge лучше. Не ожидал, что все оказалось настолько уныло.
Оставим даже за скобками вопрос, что алгоритмические секции на собеседовании — сомнительный путь и плохо коррелирует с повседневной работой. Предположим, что человек идет на LeetCode, чтобы прокачать свои знания алгоритмов и структур данных и блеснуть ими на этой части собеседования. Соответственно, в идеале система должна подталкивать человека искать хорошие с точки зрения асимптотики решения, ну или хотя бы быстрые с точки зрения всех нюансов оптимизации. А всякие метрики и прочее должны показывать прогресс и степень усвоения материала.
Однако реальность полна разочарований.
Во-первых, скорость решения никак не измеряется. Да, выводятся какие-то циферки, но это можно считать случайной величиной — можно отправить одно и то же решение несколько раз и получить результат от “вы лучше 10%” до “вы лучше 95%”. Какой-то попытки нормализовать скорость выполнения (например, считать такты процессора) нет. Доходит до смешного, что решение, которое вызывает библиотечную функцию с O(n) внутри, работает “хуже” говнокода за O(n^2) и не побеждает даже 50% решений.
Во-вторых, acceptance rate (доля принятых решений) считается максимально тупо: количество принятых, деленное на количество отосланных. Т.е. можно посылать одно и то же решение миллион раз и додолбить свой процент до 99%.
В-третьих, можно бесплатно пробовать свое решение на парочке тестовых примеров и добавлять свои. Вроде звучит круто, но это дает искушение вместо того, чтобы подумать, просто наговнякать “на глазок” и поправить всякие ошибки ±1 по результатам тестов, как макака.
В-четвертых, никак не проверяются дополнительные ограничения. Например, нельзя использовать метод из стандартной библиотеки, а реализовать что-то самостоятельно. Какое решение самое топовое? Правильно, вызов того самого метода.
В итоге ни одна цель не достигается. Никакой обратной связи по качеству решения нет. Смотришь топовые решения, а там абсолютно случайная дичь. Встречается даже откровенная подгонка под систему, как вам такое:
f = open("user.out", "w")
lines = __Utils__().read_lines()
trash = {91: None, 93: None, 44: None, 10: None}
while True:
try:
param_1 = int(next(lines).translate(trash)[::-1])
param_2 = int(next(lines).translate(trash)[::-1])
f.writelines(("[", ",".join(str(param_1 + param_2))[::-1], "]\n"))
except StopIteration: exit()
Тут парсится ввод и записывается результат в выходной файл, в обход всех структур данных (а по условию нужно просуммировать два числа, записанных в виде связных списков). Тоже топовое решение, и подобные встречаются часто. С учетом того, что я увидел, я бы не удивился, если бы в решении тупо был бы захардкожен ответ. И так и получилось:
def numIslands(self, grid: List[List[str]]) -> int:
if grid == [["1","0","1",....]]:
return 23
m = len(grid)
n = len(grid[0])
if m > 250:
return 6121
...
При этом интересные решения встречаются редко. Например, для расчета чисел Фибоначчи среди топовых решений нет логарифмического (при этом в обсуждениях есть решение с матрицами, но без быстрого умножения). Для сдвига массива нет решения, учитывающего НОД сдвига и размера массива, которое работает ровно за n обменов. В предлагаемых сообществом решениях примерно 90% — полнейший треш, да еще и с кликбейтами вроде “Easiest to understand”, “Fastest solution” (разумеется, оба действительности не соответствуют). Даже в официальных решениях встречаются перлы вроде “вот решение за O(1)” (когда там словарь строится).
Наконец, какие-то правила оформления кода летят в одно место — даже функция-заготовка содержит однобуквенные переменные, чего уж говорить о предлагаемых решениях (а о прочем оформлении даже говорить ничего не буду). Фронтенд иногда доставляет:

Хотелось бы мне сравнить LeetCode с тестами на IQ, которые ничего не показывают, кроме умения их решать, но даже функцию подготовки к собесам он выполняет из рук вон плохо. Да, задачек много, и это однозначный плюс, но уровень их проверки и обратной связи примерно такой же, который я сделал из говна, палок и ejudge для студентов. А эти парни еще бабло зарабатывают.
Альтернативный рейтинг профунктора, или как я опять вляпался во фронтенд
Когда я попал в топ-10 (а потом и в топ-9) рейтинга профунктора за эту смешнявку мы с моим “любимым студентом”™ обсуждали ПуТЬ К уСпЕхУ и ВеРшИнЕ тОпА, соотношения лайков и дизлайков и прочую чушь.
{kind=link}
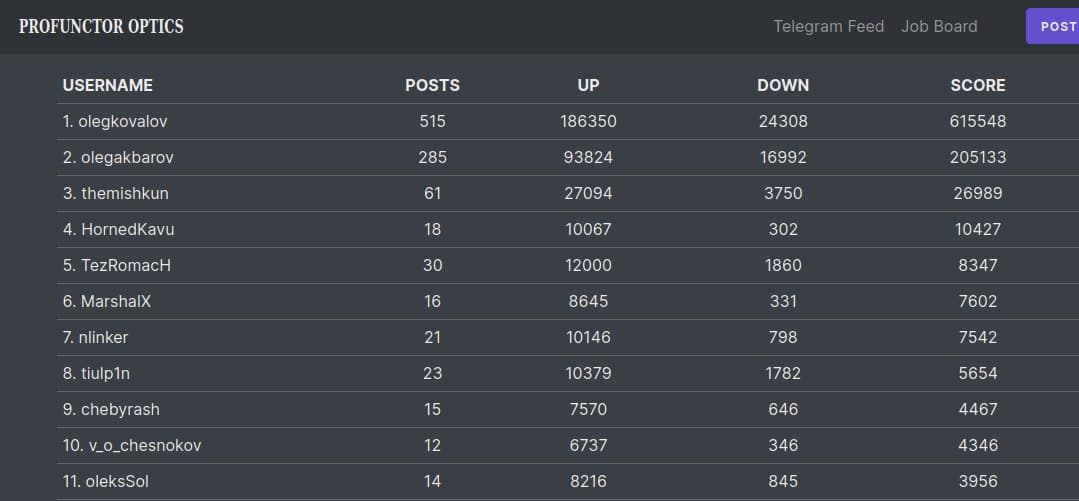 Сорри, других пруфов кроме этого вшивого скрина не сохранилось.
Сорри, других пруфов кроме этого вшивого скрина не сохранилось.
Мне тогда в голову закралась идея, что неплохо бы изучить, как этот рейтинг считается. И вот спустя почти 2 года, когда профунктор уже не торт и стал попсой, а я болтаюсь в топ-30, настало время заняться этим вопросом.
{kind=link}

Предыстория, или как я опять свернул не туда
Изначально был план отойти от фронтендерской стези и попрогать какую-нибудь математику на каком-нибудь Haskell, а то не помню уже ни математику, ни программирование. План был прост и красив: сделать запрос к рейтингу, распарсить страничку, вытащить оттуда сырые данные, какой-нибудь регрессией найти приближение для формулы и написать интересную статью (а не эту).
Я успел установить ghc, узнать, что уже нельзя просто так взять и установить компилятор, а нужна экосистема платформа, и начать писать душные заметки про то, что все не так (например, что после установки не выполняется автоматически cabal update). Посмотрел несколько HTTP-клиентов и наконец решил изучить, какой нужно сделать запрос, чтобы получить данные.
Вскоре выяснилось, что сам рейтинг не приходит с сервера, а считается в браузере. Выковырять формулу — дело нехитрое, и после этого вся затея стала скучной: зачем находить то, что уже найдено? Но хотелось что-то из этого выдавить, и придумался вариант альтернативного рейтинга, чтобы можно было подобрать свою “честную и справедливую” формулу. И для интерактива какую-нибудь морду накидать…

…и вот мы здесь. Я сначала хотел совсем упороться и все равно писать на Haskell, благо в 2019 году на конференции видел воочию подобных извращенцев, но elm оказался более разумной альтернативой — синтаксис почти такой же, чистый функциональный, да и заточен под браузер вдобавок.
Немного драмы, или почему не стоит использовать elm
По мере изучения языка начал натыкаться на разные статьи, в которых описывались проблемы сообщества вокруг языка и проблемы с большими изменениями в версии 0.19.
Ломающие изменения в последней версии
В предыдущей версии языка можно было вставить немного кода на JS в elm-код, если очень нужно было. Особенно это было полезно для построения мостов к JS API, но в новой версии это запретили из лучших побуждений, и разрешили только “избранным” библиотекам. Как следствие, если есть проблемы с производительностью или нашелся баг, то надо ждать исправлений от core-команды языка. К сожалению, это задело многие полезные библиотеки и у многих разработчиков бомбануло.
Еще раньше можно было определять свои операторы. В новой версии это запретили… везде, кроме библиотек от авторов языка, например в elm/parser. Т.е. в компиляторе тупо захардкожено, что если GitHub-организация — elm, то можно, если нет — иди нафиг.
Кто не с нами, тот против нас
Судя по постам, разработчик(и) языка довольно плохо воспринимают критику. Более того, вместо открытых обсуждений дальнейшего развития языка с открытым исходным почти все решения принимаются кулуарно, а на форуме в основном пишут, что ты дурачок и все делаешь не так (с автоматическим закрытием топика через 10 дней). Ну и у создателей есть единственно верная точка зрения™, если ты попытаешься что-то возразить, то ты плохой человек and should feel bad (для драмы можно почитать весь тред). Вдобавок, зачастую заранее отключаются комментарии к постам, тикет на гитхабе может быть закрыт с комментарием из серии “может исправлю” или “не, мне это не надо” (сам видел кучу таких), а людей могут тупо банить за неправильное мнение (см. пост, тут человек использует твинк, т.к. боится, что его забанят). Все хорошо выражается картинкой (стырено отсюда):

И да, ни что не мешает ребятам при всем этом иметь взаимоисключающие параграфы: например, утверждать, что все пакеты в официальном репозитории написаны без JS, когда это легко опровергается.
Туманное будущее
Ну и наконец, последний релиз был в 2018 году с патчем в 2019ом. Основного разработчика языка уволили из главной компании-двигателя NoRedInk, а один из главный популяризаторов, автор книги про elm, переключился на разработку своего языка, Roc, о нем я уже писал. RoadMap на середину 2020 у языка практически буквально был “я хочу поэкспериментировать с чем-нибудь, может получится, может нет, держитесь на связи”. В 2022 ничего нового, последние телодвижения в исходниках компилятора и основных библиотек — в августе 2021.

Однако поиграться с самим языком все равно было интересно, благо если отбросить драму, то о самом языке многие пишут писали довольно восторженно, обещая медовые реки и кисельные берега, поэтому я решил продолжать несмотря на красные флаги.
Впечатления о языке
Язык чистый функциональный, все есть выражение, очень похож на Haskell (и его компилятор, кстати, написан на нем) и F#. Википедия считает его DSL’ем для веб-приложений и я с ней соглашусь. В отличие от Haskell язык не ленивый, но это обычно не очень заметно.
Обучение
Почему-то официальное руководство у меня не открывалось с планшета в январе (сейчас уже починили), поэтому я использовал другое. Оно мне не понравилось — часто забегают вперед, да и структура нелогичная: в секции про строки рассказывают анонимные функции, списки и импорты, в регулярках — про Maybe (аналог Option), а в списках — про кортежи, функции преобразования типов в строку и еще немного про предикаты, лямбды и ассоциативность возведения в степень. Написано как для даунов, но постоянные отвлечения расстраивают, и выбор примеров довольно странный: например, композиция функций объяснена через пример с четырехразрядным сумматором.
Хотя в официальном руководстве тоже встречались проблемы со структурой и логикой, да и рассказывается там больше про фреймворк, чем про язык.
Установка, компиляция, среда разработки
Язык живет в экосистеме Node.js со всеми вытекающими. Однако есть свои команды для сборки и добавления пакетов. Понравилась фича, что можно скомпилировать приложение как в JS-модуль, так и в полностью готовую HTML-страничку для SPA. Компилятор описывает ошибки очень подробно, как для даунов, но иногда я так тупил, что даже с таким объяснением было непонятно — например, когда во вложенных структурах я ошибся с именем поля, компилятор честно сказал, что он ждет другой тип, но я не понял, в чем их отличие.

Очень приятно, что нет ебли с запуском сервера, как было с Rust и Svelte — просто открой HTML в браузере! После выяснилась проблема, что модуль ссылок не поддерживает ничего, кроме http, и все ломается, но я добавлял навигацию в самом конце, а до этого жил спокойно.
Не обошлось без хрени с VSCode, но после идиотизма с F# — терпимо. Еще VSCode мог отказаться переименовывать функцию (без объяснения причин), и постоянно подсовывал левые импорты (что иногда подбешивало).
Оформление и организация кода
Отступы значимые, при этом есть официально одобренный стиль. В нем есть интересные идеи, но в целом он мне не очень нравится. Есть и фашистский форматтер, который нельзя настроить, и иногда он делает какие-то совсем тупые вещи (например, вставит перенос строки для fontSize = 16, потому что это функция верхнего уровня или заменит \r на юникодный \u{000D}, хотя \t или \n ему норм). Можно еще почитать забавный срачик про количество пробелов и табы и узнать про то, что у простыни кода есть “форма”.
Все локальные переменные надо определить в блоке let, привет Pascal! Это обычно приводит к тому, что код либо дробится на много мелких функций и хэлперов, либо к огромным простыням в let.
Иногда возникает конфликт имен, и это уныло. Жил — не тужил, добавил вспомогательный метод error в Reader — и пришлось переименовывать аргументы у других функций, потому что они тоже назывались error — shadowing в языке отсутствует, ибо “так лучше”.
Судя по всему, распространенная практика организации кода — складывать все в один гигантский файл. Файл на 500+ строк — вполне норма, даже для основной библиотеки. Код довольно сложно разбить на пакеты, особенно с учетом того, что надо явно импортировать даже то, что лежит в соседнем файле.
Функции
Каррирование с одной стороны прикольно, но с другой — поддержка какая-то слабенькая. Надо хорошо думать, какой аргумент делать последним. Иногда возникает ситуация, что в одной и той же функции хочется каррировать по разному — так родился with. В Scala для этого достаточно просто подчерка в нужном месте. Логичное следствие каррирования — отсутствует перегрузка функций и аргументы по умолчанию.
Для композиции функции есть метод конвеера |> и собственно композиция >> (уже знакомые по F#), и симметричные к ним <| и <<. С >> и << я вначале часто путался и ошибался, но потом вроде привык.
Лямбды немного страшно выглядят, особенно когда это длинная колбаса в скобках в середине выражения, но все равно лучше чем в F#. Как следствие, лямбд хочется избегать и совать вспомогательные функции в let.
Работа со строками
Ожидал богатой библиотеки для работы со строками — все ж таки, взаимодействие с пользователем, всякие сериализации/десереализации, но, увы, стандартная библиотека скудна. Нет и скорее всего не будет интерполяции строк, потому что “это не нужно”. Нет проверки, является ли символ пробельным. Есть аж 5 функций для составления подстроки, даже слайс с отрицательными индексами, но после питоновских слайсов одним единообразным способом выглядит довольно грустно.
Регулярки выглядят уныло, нет способа избежать экранирования слешей и т.п. Предполагается, что все будут использовать официальную библиотеку парсеров.
Коллекции
Списки могут иметь в себе строго один тип (и это реально связный список). Т.е. нельзя сделать список из структур-объединений, а потом его разбить по типам в общем виде. Никаких манипуляций с индексами, для этого нужно использовать массивы. А массивы не импортированы по умолчанию и их фиг создашь — нужно создавать из списка. Причем если для слайса работает отрицательный индекс, то для получения по индексу — нет. И если в строке можно получить последние N элементов, то в массиве это уже нетривиально, там даже последний по индексу элемент надо доставать через длину массива. А еще для массивов не работает конкатенация через оператор ++.

Лучшее, что есть для ассоциативного словаря — Dict, внутри которого красно-черное дерево. Создавать его тоже надо через список. Словарь довольно уныл, нет даже associate — пришлось писать свой. Хэш-таблицы нет, да и даже в словарь не все запихнешь, потому что система типов весьма вялая.
Преобразование коллекций — как в F#, через статические методы, с теми же претензиями. Еще их особо не получится импортировать: будет конфликт имен. Сделано, такое ощущение, это нарочно, потому что операторы вполне себе работают для разных типов. Т.е. так работает:
module Main exposing (..)
import Html exposing (text)
import Debug
main =
let
s = "rere"
t = "lala"
l1 = [1,2]
l2 = [3,4]
r1 = (++) s t
r2 = Debug.toString <| (++) l1 l2
in
text (r1 ++ r2)
а если заменить ++ на append — то уже нет, потому что компилятор не понимает, какой append правильный, несмотря на то, что это элементарно выводится из типа:
import Html exposing (text)
import String exposing (append)
import List exposing (append)
import Debug
main =
let
s = "rere"
t = "lala"
l1 = [1,2]
l2 = [3,4]
r1 = append s t
r2 = Debug.toString <| append l1 l2
in
text (r1 ++ r2)
Система типов
Можно создавать свои ADT: типы-объединения (перечисления) и типы-произведения (записи). Однако ни для одного из них нет преобразования в строку, и это очень печально. Записи выглядят почти как JSON и имеют интересный интересный синтаксис для обновления:
> type alias User = { name: String, age: Int }
> old = User "Vasyan" 15
{ age = 15, name = "Vasyan" }
> new = {old | name = "Petyan"}
{ age = 15, name = "Petyan" }
Однако он ломается при использовании импортированных значений. В типах-перечислениях напоролся, что нельзя использовать одно имя в разных типах — поэтому приходится добавлять суффиксы. Видимо, это опять “забота” о разработчике, чтобы он не запутался.
Система типов гораздо слабее, чем в Haskell, и явно более ограничена по сравнению с F#. Нет ни классов, ни классов типов, даже подобия трейтов нет, только встроенные костыли с number и comparable. Даже простые интерфейсы сильно помогли бы, хотя бы чтобы при добавлении обобщенных функций не добавлять параметр типа везде где только можно, даже если там этот параметр не нужен.

Сигнатуры функций, на удивление, оказались очень полезны. Иногда становится понятно, что уже на уровне типов задумка неосуществима, поэтому оправдался подход, когда сначала пишешь сигнатуру, а уже потом тело функции. Да и по сигнатуре можно быстро сориентироваться при чтении документации или использовать ее для поиска подходящего метода.
Иногда сигнатура может вводить в заблуждение, но это все приколы каррирования. Например, в этой функции
binaryOperator : String -> (Float -> Float -> Float) -> Evaluation context
binaryOperator name op context args = ...
всего два аргумента, если судить по сигнатуре, и четыре, если судить по объявлению. Но секрет в том, что Evaluation context — это тоже функция context -> List Float -> Result String Float, и именно в ней “спрятались” оставшиеся два аргумента.
Прочее
Паттерн-матчинг довольно примитивный — нет guards (дополнительных условий), нет комбинации с лямбдами, нет возможности использовать несколько паттернов для одного действия. Были моменты, когда было два стула: либо паттерн-матчинг с дублированием кода, но с красивым получением из Maybe, либо тупо if, но без него. Это одна из причин того, что тяжело работать со вложенными структурами — получается простыня из матчеров и условий.
Кортежи есть только для двух и трех элементов, но для тройного даже нет функции получения последнего элемента. Напоролся еще, что для них нельзя сделать type alias.
Для сортировки по убыванию пришлось использовать костыль. Сначала реализовал через умножение на -1 (причем оказалось, что унарный минус нельзя использовать как функцию, поэтому пришлось сделать свою), но потом выяснилось, что elm не умеет работать с NaN, в нем нет даже константы для него:
> list = [ -1, 0/0, 1, 0/0, 2, 3, 0/0, 4, 5, 6, 0/0, 5, 6, 5]
[-1,NaN,1,NaN,2,3,NaN,4,5,6,NaN,5,6,5] : List Float
> negate x = -x
<function> : number -> number
> sorted = List.sortBy negate list
[6,6,5,5,5,4,NaN,NaN,3,2,1,-1,NaN,NaN]
Чисто функциональный Random с Seed — прикольный, но очень не удобный. 100% чистота тут только мешает. А с текущим временем даже не представляю, как тяжело будет работать.
Корректность
О языке иногда говорят, что с ним “почти невозможно” получить ошибку во время исполнения — но это скорее манипуляция фактами. Да, строгая проверка типов ограждает от некоторых глупых ошибок. Но вместо некоторых ошибок просто работает странное поведение по умолчанию, например, очень легко пойти по неверной дорожке и вместо нормальной обработки Maybe пихать значение по умолчанию.
Как минимум одну ошибку во время исполнения я получил, и это баг библиотеки парсинга ссылок:
Так же никто не застрахован от того, что тупо неправильно реализована логика. Под тип String -> String можно написать очень много вариантов функций. Так что к заявлениям о том, что рефакторинг в elm ничего не ломает, тоже стоит относится скептически.
Парсер выражений и пучины рефакторинга
Большую часть времени я потратил на написание парсера выражений и на его многократный рефакторинг. Алгоритм сортировочной станции с преобразованием в обратную польскую нотацию мне показался очень скучным, поэтому я решил поискать альтернативы.
Подумывал использовать официальный парсер, но, хоть и подробные ошибки с указанием контекста были соблазнительны, инопланетный DSL и скудность примеров отпугнули. Да и хотелось более низкоуровнего решения, чтобы потренироваться кодить.
Сортировочная станция — это одна из возможных реализаций парсера грамматики с операторным предшествованием. Другая реализация — парсер Пратта. Создатель JSON, Дуглас Крокфорд использовал его в JSLint и описывает так:
It is easy to use. It feels a lot like Recursive Descent, but with the need for less code and with significantly better performance. He claimed the technique is simple to understand, trivial to implement, easy to use, extremely efficient, and very flexible. It is dynamic, providing support for truly extensible languages. […] His technique is most effective when used in a dynamic, functional programming language.
Как раз мой случай! Парсер основан на рекурсивном спуске и ключевая идея заключается в том, что сначала парсится “левая” часть выражения, потом оператор и “правая” часть. Разумеется, последовательный парсер не знает, где находится самый низкоприоритетный оператор, поэтому при появлении оператора с более высоким приоретом уже напарсенное объединяется с левой частью, и снова запускается парсинг правой части. При этом приоритет определяется через “силу присоединения” оператора: если один и тот же элемент может попасть в выражение к оператору слева или к оператору справа, то побеждает оператор с самой большой силой присоединения. У одного оператора может отличаться сила присоединения слева и справа для правильной ассоциативности.
Например, при парсинге 1 + 2 * 3:
- Парсинг левой части вернет
1. - Парсинг оператора —
+. - Парсинг правой части возьмет
2, посмотрит, что*имеет большую силу присоединения, чем+и продолжит парсить все выражение до конца или пока не встретит оператор с меньшей силой присоединения, чем у+, т.е.2 * 3, и вернет* (2, 3). - При выходе из рекурсии возвращаем выражение с оператором —
+ (1, * (2, 3)).
А для 1 * 2 + 3 на третьем шаге парсер правой части посмотрит на + и не будет читать дальше, объединит прошлую левую часть 1 и текущее напарсенное * 2 в новое левое выражение * (1, 2), употребит в качестве правой части 3 и вернет + (* (1, 2), 3).
Первая моя реализация была адаптацией Rust-кода из этой статьи. Выглядело это максимально страшно, особенно с учетом форматирования elm. А потом я начал рефакторить: с третьего раза разбил все на файлы из одной большой помойки, выделял однотипные куски, избавлялся от миллиардов уровней вложенности, изобрел монаду State и назвал ее Reader, пробовал сделать хоть какое-нибудь обобщение функций и операторов, даже написал свой костыльный filterIsInstance, но в итоге выкинул, менял пару раз типы, писал юнит-тесты для старых типов, потом выкинул их и написал интеграционные, менял зоны ответственности токенизатора и парсера, добавлял возможность работы с “контекстом” и, наконец, все обобщил, чтобы можно было в парсер было закинуть произвольный набор функций и операторов, а он дальше все сам прожует.

Полученный код можно даже вынести в отдельную библиотеку, но с учетом фактической смерти языка делать это я, разумеется, не буду.
Веб-морда
The Elm Architecture
“Изюминкой” elm является его Архитектура, которая является вариацией MVC. Приложение состоит из модели, представления и функции обновления. Модель хранит состояние всего приложения, на ее основе генерируется представление. Из представления могут быть посланы сообщения. Сообщение и текущая модель подаются на вход функции обновления, которая обновляет модель и может генерировать команды для взаимодействия с внешним миром и JS (например, выполнить HTTP-запрос). Этот подход в elm был одним из источников вдохновения для Redux.
В целом идея довольная простая и мне она нравится. Но у нее есть и недостатки. Например, нет определения циклов в обновлении — если при отсылке сообщения оно генерирует команду, которая приводит к обновлению с этим же сообщением, то elm не может определить это и тупо ничего не делает (или в вечном цикле висит, не стал разбираться) — к слову о корректности. Я вляпался в такое, когда в одной из версий при пересчете рейтинга обновлялся путь в адресной строке, а при его обновлении менялась формула и запускался перерасчет.
Про Virtual DOM можете прочитать самостоятельно, это в любом холиваре React vs Svelte напишут. Конкретно для elm это проблематично тем, что в модели должно быть явно записано ВСЁ состояние для всех элементов. Если это не делать, то можно ловить унылые баги, например, у меня не убирался заполнитель в поле ввода. Как следствие, для каждого элемента нужно создать поле в модели, добавить сообщение про обновление элемента, добавить создание сообщения в представлении и его обработку в функции обновления. И это все лишь для того, чтобы элемент не забыл свое состояние. От такого у пользователей с опытом в других фреймворках вполне закономерно бомбит.
В процессе работы почувствовал ощутимый лаг ввода — оказалось, что при каждом сообщении все элементы пересчитывались и перерисовывались целиком. Оказалось, что нужно явно указать, что не нужно обновлять элемент, если модель (или определенная часть модели) не поменялась. Причем там идет сравнение ссылок, а не сравнение содержимого, поэтому работает это довольно хрупко. Почему элементы не ленивые по умоланию — не ясно. Я добавил lazy всего в трех местах и стало работать ощутимо быстрее.
Представление
Для создания странички можно генерировать HTML прямо в коде, для этого на каждый тег есть своя функция. Выглядит это весьма cтремно:
view model =
div [ class "jumbotron" ]
[ h1 [] [ text "Welcome to Dunder Mifflin!" ]
, p []
[ text "Dunder Mifflin Inc. (stock symbol "
, strong [] [ text "DMI" ]
, text <|
"""
) is a micro-cap regional paper and office
supply distributor with an emphasis on servicing
small-business clients.
"""
]
]
Подход Svelte с тегами для компонентов мне нравится больше.
Но есть и другой подход — elm-ui, библиотека компонентов, в которой [почти] не нужно думать о HTML и CSS. Для нее даже есть WYSIWYG-редактор для генерации кода. Эта библиотека весьма удобна до тех пор, пока желаемое дозволено и реализовано в компонентах. А возможностей для расширения тут не очень много, и некоторые вещи реализованы кривовато, например, из коробки не работает изменение цвета для посещенной ссылки.
Из мелочей — удобно, что вместо огородов с Maybe Element можно просто написать Element.none, чтобы не отображать опциональный компонент.
Из неприятного — довольно плохо реализована работа с вводом, даже если не считать проблемы с бойлерплейтом для хранения состояния. В первой версии я использовал обычное поле ввода, и чтобы добавить действие при нажатии на Enter, разработчик официально советует использовать костыль, в котором добавляется обработчик на keyup и проверяется, что key == "Enter". Почему этого нет в самой библиотеке — непонятно.
Автозаполнение
Но костыли с Enter — еще не самое страшное. Когда я начал разбираться с автозаполнением, выяснилось, что в библиотеке есть флаг на его включение, точнее есть специальные вариации полей ввода с автозаполнением, но в некоторых флаг тупо не включен, а при использовании других выясняется, что он вообще не работает. Кажется, эту функциональность даже не тестировали. Все из-за того, что автозаполнение работает только при выполнении трех условий:
- у поля ввода есть имя и id;
- оно находится внутри формы;
- у формы есть кнопка “submit”.
Я уже вляпывался в это, когда делал морду для статистики пулл-реквестов, но в голове не отложилось :/

Поддержки форм в elm-ui нет, поэтому пришлось первый пункт решить добавлением атрибутов, а для второго пришлось городить костыль, когда элемент трансформируется в HTML, потом вместе со скрытой кнопкой оборачивается в форму и конвертируется обратно в элемент, а потом еще и оборачивается в псевдоэлемент, потому что из-за оборачивания сломалась верстка — неправильно считались отступы. Еще пришлось явно указывать, что стиль нужно применить только для элемента, потому что в противном случае генерировалось несколько глобальных CSS-стилей, которые конфликтовали друг с другом. Вот тебе и “почти” не надо знать об HTML и “корректная работа”, если по типам все хорошо.
Зато костыль с обработкой нажатия Enter перестал быть актуален и я его убрал.
К сожалению, автозаполнение заполняется только при взаимодействии с формой, а при нажатии на кнопку это не происходит, потому что она не submit. И сделать таковой ее легко не получится, потому что в генерируемом HTML это просто div, а не button или input. Переписывать на HTML еще и это мне уже не захотелось.
А еще автозаполнение будет работать даже при выполнении только первых двух пунктов, просто показывать будет старые результаты и не будет добавлять новые. Я этот момент упустил и ошибочно удалил костыль со скрытой кнопкой, вернул обратно уже когда эту статью писал.
Навигация
Навигацию для SPA, как мне кажется, можно было бы сделать проще. Для ее работы нужно поменять тип приложения, добавить в перечисление сообщения про клик по ссылке и изменение URL, добавить их обработку в функцию обновления (это будет тупо копипаста стандартного подхода) и добавить в модель ключ навигации, который нужен только для того, чтобы его потом везде перепрокидывать. Подобные технические решения конечно можно объяснить, но от этого более удобными они не становятся.
Парсинг ссылок тоже довольно уныло реализован, частично ссылку парсить нельзя, только полностью. Ну и про поддержку протоколов уже писал выше.
Работа с GraphQL
Для GraphQL-запроса использовал библиотеку, которая генерирует тонны страшного кода. Еще не с первого раза поставилось (пришлось сначала поставить, а потом удалить модуль, потому что автоматом тянулась версия для 0.18), но потом достаточно было выполнить
npx elm-graphql 'https://api.profunctor.io/v1/graphql' --base ProfunctorIo
чтобы генератор выкачал схему и по ней создал типы для всего API. Однако в сгенерированных типах оказались сплошные Maybe, и все равно пришлось писать еще свой конвертер в нормальную модель. Гении-разработчики решили еще в примерах сделать alias, чтобы две разные сущности назывались одинаково — Character. Потратил время, чтобы разобраться, как правильно сделать у себя. Кстати, тут компилятор мог бы и ругнуться, а то shadowing нельзя, импортировать разные функции с одинаковыми именем нельзя, а два одинаковых псевдонима — пожалуйста!
Вообще подход с генерацией конечно прикольный, но кажется, что это стрельба из огромной пушки по воробьям: мне нужен всего один запрос, а в ответе отдается простенький JSON. Но тут написано, что для этого все равно небольшую портянку с декодерами надо написать, и я поленился, хоть потом и посмотрел, что не все так страшно.
Что можно было бы еще сделать
Нет предела совершенству, но надо когда-то остановиться. Часть идей я решил просто бросить, потому что с ними много предсказуемой мороки, а выгоды не очень много хотя как будто она была от всего проекта.
Первый момент — это ошибки. Их стоило бы сделать более жестко типизированными, а не тупо строками. Чтобы потом во view генерировать представление текстом или даже переводить. Но для этого нужно было потенциально упороться с конвертированием при переходе между разными функциями (например, конвертировать ошибку токенизации в ошибку парсера или в ошибку валидации) и написать кучу бойлерплейта для их конвертации в строку. Еще можно было сохранять контекст для токенов, чтобы выводить очень красивое и подробное отладочное сообщение о том, в чем именно проблема и валидировать выражение перед его парсингом, но для этого пришлось бы опять переделывать парсер, токенизатор и возможно Reader, что мне немного надоело.
С точки зрения самого парсера стоило как-нибудь обобщить обработку скобок или возможно добавить еще другие варианты (например, модуль обозначать через |x|, а не abs(x)). Еще можно было бы разрешить многосимвольные операторы (**, например). Но оба этих улучшения показались слишком незначительными, а без них парсер выглядит проще. Еще я откровенно заленился обрабатывать деление на ноль или NaN (см. корректность), хоть и оставил заготовки под это.

Мне очень хотелось написать фаззинг-тесты, но, увы, я не придумал хорошего инварианта, который был бы достоин проверки: к сожалению, в выражениях мешаются скобки, которые для выражения (1+2) могут стоять, а могут отсутствовать, да и генерировать хочется преимущественно корректные варианты, чтобы их потом вычислять и проверять. Эта задача по трудозатратам кажется почти эквивалентной написанию парсера, так что от нее я в итоге отказался.
Заключение
Поиграться с полученным рейтингом можно тут, почитать код — на GitHub. В качестве разминки для мозгов можно попробовать найти формулу, чтобы нужный человек был в топ-1 :) Кидайте в комменты/лс ваши варианты (если эту статью вообще хоть кто-то осилил). Профунктор округляет результат вниз и сортирует уже с округленным значением, а еще выкидывает из рейтинга людей с NaN, так что если случится такое, что запостите мем с нулем дизлайков, то в рейтинг не попадете. Дублировать эти костыли я не стал, так что рассчитанный рейтинг может немного отличаться от оригинала.
В языке есть интересные идеи, но чувствуется, что он не очень зрелый, а местами сделано явно тяп-ляп. Иногда приходится писать откровенный бойлерплейт. Хотелось бы больше фунциональности иметь из коробки.
Я от души поразвлекался с Railway-oriented programming. Подход хороший, но с учетом последних веяний кажется устаревшим: это как писать на Future или Promise, когда есть асинхронщина и корутины. Слишком многословно получается, хочется отрешиться от типов и замести под ковер детали — либо сахаром, как в Haskell или Scala, либо каким-то иным, более высокоуровневым способом работать с эффектами. Пока мне больше всего нравится идея с переосмыслением исключений в Scala.
Хоть язык и мертвый, я считаю, что потратил время не зря, нашел для себя пищу к размышлениям и узнал немного нового. Да и тренировка получилась неплохая. Рекомендую всем поиграться с чистым ФЯП для общего развития!

Я третий месяц работаю на маке и у меня почти не бомбит
На работе выдали мак, описываю свой опыт. У этой заметки нет цели, только путь.

Клавиатура
Одним из первых впечатлений была раскладка клавиатуры, но об этом я уже писал. Дополняют непривычную раскладку непривычные горячие клавиши, которые порой могут состоять из трех или даже четырех нажатий (как вам, например, Shift + Command + 4 + Space для скриншота окна?). Иногда чувствовал, что рука расположена как-то так:

Причем не все можно поменять — например, раскладку клавиатуры на Alt + Shift уже не переключишь. На ноутбучной клавиатуре это еще терпимо (можно нажать Fn), но на внешней — уныло. Бонусом идет тупка с путаньем Ctrl vs Command при переключении на домашний комп. А еще не хватает Home и End — только подпорки, которые не везде работают. Справедливости ради, иногда комбинации логичнее, чем “привычные”: например, нормально работающая вставка в терминале (потому что она висит на Command + V, а управляющие команды — на Ctrl).
Мышь
На тачпаде немного поработал, но все-таки это не мое — мышка удобнее. Долгое зажатие вместо правой кнопки — сомнительное решение. 4-5 кнопки из коробки не работают — только через костыли в Karabiner. Иногда даже при не очень большой нагрузке курсор сильно лагает и “дергается” — это жутко бесит, особенно когда из-за этого промахиваешься по элементам (и это явно не проблема с оборудованием, а с приоритетом обработки ввода). Не помню, чтобы винда или линукс такое себе позволяли.
Надежность
Бытует мнение, что в Apple лучшие инженеры™ создают единственно верную ОС™, которая идеально работает на специально подобранном оборудовании™. Мол, не надо поддерживать зоопарк писюков и все поэтому работает зашибись. Так вот, это брехня собачья.
Я не мог залогиниться в App Store. Казалось бы, критичная функциональность, чтобы ПЛОТИТЬ деньги. Но нет, логинишься, что-то там грузится, потом логинься опять. И я такой не один. Уже не вспомню, как у меня в итоге получилось это сделать, но наверняка “надо было просто держать в правой руке”.
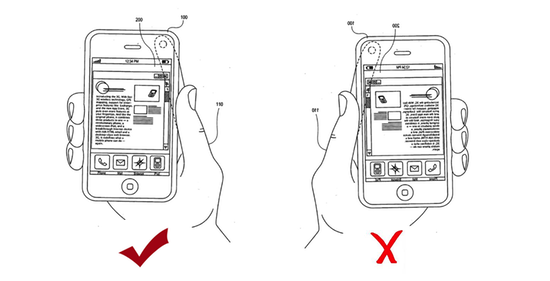
Другой прикол — после обновления (Monterey 12.1) в Safari перестал работать микрофон. Похожая проблема была еще в 2018. Я потратил несколько часов на попытки решения этой проблемы, даже пробовал стремную комбинацию со сбросом памяти Option + Command + P + R, но это никак не лечилось. Поскольку Safari — важный системный компонент (как Internet Explorer), то ни переустановить, ни изменить его версию нельзя, пришлось пересесть на другой браузер, чтобы в Meets говорить. И новое обновление (12.2) эту проблему не решило.
В качестве третьего примера скажу, что у меня один раз завис Dock (панелька внизу для запуска приложений). Благо был открыт браузер и терминал, и я смог его перезапустить, но осадочек все равно остался.
Наконец, в выданном мне стареньком маке уже лагает видеокарта или встроенный монитор (показывает периодически случайный набор пикселей) и вентилятор шумит, как космолет.
Приложения
brew — просто must have, потому что из коробки почти ничего не стоит. К сожалению, при каждом запуске он качает кучу всего (например, свои обновления). Магазин — это конечно прикольно, но все, что я ставил из него, оказалось бесполезным.
Из коробки нет нормального текстового редактора — только вшивый блокнот, который поддерживает немного форматирования, и приложение для заметок, 1-в-1 как на iOS. После почти любого линукса, в котором будет блокнот с подсветкой кода (gedit, kate и т.п.) — уныло. Для офисных форматов поставил LibreOffice, для всякой мелочи использую что попало.
Нет аналога Paint. Где теперь рисовать убогие мемы? Можно, конечно, использовать встроенный Preview, но он хорош только для мелких правок — типа шлепнуть текст поверх скриншота или обвести что-нибудь (что и редактор в телеге умеет). Добавить пустое место — уже нетривиально. Все редакторы, которые попробовал, либо лагали, либо тупо не запустились, либо имели настолько порезанный функционал, что смысла в них не было. Видимо, настоящие маководы — это дизайнеры и сразу в фотошопе все хреначат.
В мире, где правит SaaS, это все некритично, но впечатления, что получаешь готовую для большинства задач систему из коробки — нет.
Безопасность
Классный подход к безопасности и изоляции приложений — например, можно явно запретить приложению пользоваться камерой, слать уведомления или даже получать доступ к папкам на диске. Но это палка о двух концах — если хочешь пошарить экран в слаке, то изволь запросить сначала разрешения, потом перезапустить слак и перезайти в созвон. Безопасность против удобства, классика:)

Но бывают моменты, когда Большой Брат Стив Знает, Что Тебе Это Не Нужно. Например, в рутовой ФС ничего создавать нельзя. Совсем-совсем, даже если очень надо.
Интеграции
Очень классная интеграция почты и календаря с Гуглом — один раз залогинился, и все работает. Разумеется, если почта не на Гугле — то страдай. Интеграция с Intellij Idea, когда в Dock показывается прогресс билда — просто супер. Увы, еще примеры тяжело назвать.
UX
По идее, я должен был проникнуться и удивляться, как все удобно и продумано. Конечно, есть приятные мелочи и просто забавные штуки (типа анимированных аватаров на логине входа), но есть и мелкие раздражения (например, в файловом менеджере не работает вырезание, а в Safari нет иконок для закладок). Вау-эффекта система в целом не произвела.
Со всякими свистелками и перделками с окошками я наигрался еще в 2007 с Beryl верните мне мой 2007. И мак вроде ими славится, но все равно некоторых вещей не хватает: нельзя, например, закрепить окно поверх остальных (хотя при этом быстрые заметки открываются как раз поверх всех окон).
Чувствуется, что Apple идет на сближение с мобильными интерфейсами — приложения и иконки как в iOS, некоторые действия похожи на мобильные (например, в Safari, внезапно, долгое нажатие левой и нажатие правой кнопкой мыши — это разные действия, и для перехода назад на несколько шагов в истории нужно именно долгое нажатие, а логичная ПКМ — не работает). Понятно, что трендам надо следовать, но не уверен, что это хорошая идея (луддит во мне ворчит).
Ожидаемо расстроила логичность настроек и вообще возможность настройки чего-либо. Например, чтобы включить звук уведомлений в слаке, нужно включить в приложении внутренние звуки через системные настройки, а не разрешить издавать звуки уведомлениям слака в центре уведомлений. С переходом в сон вообще беда. Линусковый ноут я выключал тупо закрыв крышку и выключив мышку. С маком такой номер не пройдет. Ты закрыл крышку, но у тебя подключен внешний монитор? Бро, ты наверно еще работаешь, подумал за тебя, в сон уходить не буду. Ты отсоединил моник, закрыл крышку, но сдвинул мышку на 0.00000001 мм, чтобы ее выключить? Бро, наверно ты хочешь еще поработать, проснусь обратно. В итоге я выключаю мышку, потом тачпадом через меню включаю сон, и только потом закрываю крышку. Спасибо, Apple, что думаете за меня, как мне удобно!
Рестарт для обновления кажется уже таким устаревшим. Не понимаю, как это все выносят, особенно когда это занимает минут 30, в течение которых с ноутом ничего делать нельзя.
Итого
Несмотря на то, что статья получилась в привычном стиле (“У меня бомбит от X”), в целом жить на маке можно. Часть перделок можно перенести на линукс (если захотеть), часть довольно уникальна. Работать определенно удобнее, чем в винде, примерно понятно, почему некоторые разработчики хотят работать на нем. Но линукс лучше (кек), как минимум потому, что при сопоставимом уровне удобства платишь гораздо меньше:).
