Rust и Wasm
Решил я в конце новогодних каникул немного заняться саморазвитием. Выбор пал на язык, на котором надо переписать ElasticSearch, а то и вообще все. Дополнить я это решил Уэб-технологиями, а именно священным граалем желанным отказом от Javascript.
Предупреждаю, что история будет изложена в хронологическом порядке и местами все будет навалено в кучу.
Ну что,

Базовые знания
Материалов, чтобы изучить Rust — предостаточно. Я прочел A half hour to learn Rust, паттерны и периодически заглядывал на Rust by Example. Ну и StackOverflow, куда же без него.
Официальный сайт языка предлагает его ставить скачиванием скрипта через curl | sh. Это триггернуло мое образование и я на такое не согласился. Безопасность начинается очень весело.
Страница с альтернативными путями установки содержит еще очень удобный способ: запустить комбо curl | sh в командной строке (sic!). Ну или использовать установщики из tar.gz. Альтернативный путь для Убунты:
snap install rustup --classic
Snap тоже то еще дно, но его я переживу, хотя гореть ему вместе с электроном в одном котле.
Дальше методом тыка я понял, что нужно сделать так:
rustup install default
rustup default stable
Написать об этом для бумеров на сайте в очевидном месте видимо никто не решился, потому что все равно правильный путь — это curl | sh. Все ставится локально для пользователя, по крайней мере по умолчанию.
После этого пишем сложную функцию
fn main() {
println!("Hello World!");
}
Компилируем через rustc 1.rs и готово, можно получить приветствие через ./1!
Системщики могут посмотреть на LLVM с помощью rustc --emit=llvm-ir 1.rs, который выглядит довольно страшно.
Первые шаги с Wasm
Тут может возникнуть закономерный вопрос

Вообще правильно бы наверно ответить про то, что за этой технологией будущее, рассказать о проблемах Javascript, и что они не решаются компиляцией в него. Но на самом-то деле ответ другой:
 (тут мог быть ваш каламбур про wasm → wasp)
(тут мог быть ваш каламбур про wasm → wasp)
Ну и чтобы ух, сразу с головой окунуться в этот прекрасный дивный мир.
По теме Wasm + Rust есть туториал, в котором есть примеры и скупые объяснения. Начать предлагают традиционно с curl | sh:
curl https://rustwasm.github.io/wasm-pack/installer/init.sh -sSf | sh
Благо, тут хотя бы пишут нормальную альтернативу:
cargo install wasm-pack
Затем предлагают сразу сгенерировать все что надо через cargo-generate, вместо того, чтобы показать, как что-то подобное делать с нуля. Я и в этот раз не сделал, как предлагали, а просто скопировал git-репозиторий с шаблоном, чтобы его поковырять. Шаблонные данные поправил руками.
Дальше нужно сбилдить проект
~/.cargo/bin/wasm-pack build
Поставить npm, если его еще нет
sudo npm install npm@latest -g
А потом инициализировать шаблон приложения с Wasm:
npm init wasm-app www
Экосистема, аднака! Которая еще и выдаст эмодзи в консоль.

(дед во мне прям кряхтит от кринжа)
После этого у нас будет готова HTML-страничка, которая умеет делать простой alert. Миллиард терабайт node_modules в комплекте.
Но мы с вами живем в мире, где нельзя просто так взять и сделать alert на простой HTML.
Если просто открыть эту html-ку в браузере, то придет мой старый враг — CORS.
Поэтому надо еще и запустить сервер
npm run start
А потом еще и поколдовать с webpack, чтобы он запускался не только на localhost. Проверил — даже на моем не самом свежем планшете работает.
Манипуляция DOM
В 2018 году на Хабре писали, что такое делать нельзя, а если и можно, то с извращениями. Отлично, значит этим мы и займемся. Поверхностное изучение вопроса привело меня к библиотеке stdweb. Документация там так себе, тупо ссылки на соответствующие разделы из JS. Да и вообще это не полноценное API, а биндинги к JS.
На основе примера я начал стряпать что-нибудь простенькое, типа передвижения объекта.
Первые грабли
Первый раз все компилировалось весьма медленно. Удалось словить веселые приколы с дефисом против подчерка в имени файла. Потом вляпался в отличия статической строки от динамической — надо руками кастовать между этими типами, да и макрос для форматирования строки тоже не блещет изяществом:
let x = 5;
let y = 6;
alert(format!("Example of format {} {}", x, y).as_str());
Привет плюсовому c_str()!
Трейты, с одной стороны прикольная вещь, а с другой — работают практически как имплиситы в Scala, со всеми вытекающими. К ним еще вернусь.
Компилятор услужливо подсказывает в некоторых местах: чувак, используй snake_case. А тут у тебя импорт не используется. В основном его предупреждения были по делу.
Через некоторое время у меня все успешно скопилировалось, чтобы упасть с паникой при открытии страницы. Понять, что не так — почти невозможно, стектрейс с кишочками из библиотеки торчит.
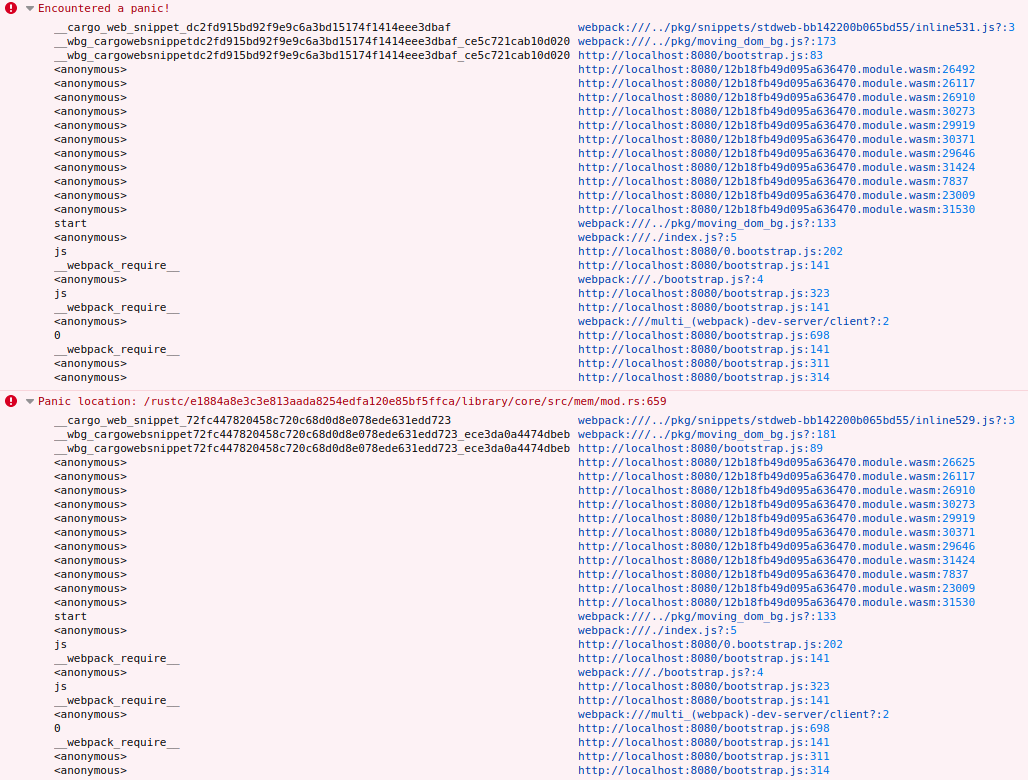
И это с учетом console_error_panic_hook, который должен делать ошибку понятной. Я вышел с этим вопросом в интернет, но нашел только странный баг в Firefox. Потыкался в console_error_panic_hook — что подключать его, что не подключать — результат одинаковый.
Озарение
Потом понимаю — что запускаю-то я сервер через npm. Горячая загрузка и все такое — это классно, но имеет ли код при таком способе запуска доступ к DOM? Ссаный фронтенд, где факт того, что у тебя запустилось, ни хрена не значит :(.
Переделываю свой код на основе другого примера. Не работает.
Ладно, наверно я дебил, пробую скомпилировать сам пример, но там ошибка компиляции:
error: missing documentation for a function

Закомментировал линтер, ура, скомилировалось, и…. Uncaught (in promise) Error: undefined. Bellissimo. Потом еще выясняется, что эта библиотека толком и не поддерживается уже.
Возврат к wasm-bindgen и новые грабли
Ок, я тупой, надо было дальше читать туториал по wasm-bindgen и не выпендриваться. Моей ошибкой (кроме использования неактуальной библиотеки) было непонимание, что предыдущие действия были нужны для создания npm-модуля для подключения через package.json. А мне-то нужна была фронтовая библиотека, и для прямой загрузки в браузере нужно было использовать флаг --target web для wasm-pack. Запуск веб-сервера все равно нужен, но делать это можно любым инструментом, даже python3 -m http.server.
Хочу сделать двигающийся объект, смотрю пример про request_animation_frame (тут я его немного сократил):
#[wasm_bindgen(start)]
pub fn run() -> Result<(), JsValue> {
let f = Rc::new(RefCell::new(None));
let g = f.clone();
let mut i = 0;
*g.borrow_mut() = Some(Closure::wrap(Box::new(move || {
if i > 300 {
body().set_text_content(Some("All done!"));
let _ = f.borrow_mut().take();
return;
}
i += 1;
let text = format!("requestAnimationFrame has been called {} times.", i);
body().set_text_content(Some(&text));
request_animation_frame(f.borrow().as_ref().unwrap());
}) as Box<dyn FnMut()>));
request_animation_frame(g.borrow().as_ref().unwrap());
Ok(())
}
Первое впечатление — жесть, как вообще это читать? Однобуквенные переменные, куча кастов — это точно про безопасность? Вообще по wasm-bindgen дока приемлемая, но в примерах, по ощущениям, люди совсем не стесняются писать “лишь бы работало” и использовать однобуквенные переменные.
Пытаюсь сделать, что мне нужно. u32 вместо int прям-таки орет, что это язык системного уровня, а не прикладного. Ну и от сишного стиля коротких индентификаторов и аббревиатур я уже отвык.
Следующая ошибка —
expected an `FnMut<()>` closure, found `[closure@src/lib.rs:68:51: 84:6]
Компилятор показывает услужливо место, что не так. Услужливо дает возможность прочитать объяснение ошибки для даунов (rustc --explain E0277): так мол и так, ты совсем дебил, нужно определить трейт для типа. Смотрю в пример, импорты, Cargo.toml — все то же самое, что и в примере. Качаю пример — он билдится. Думаю, что еще может быть не так, методом тыка обнаруживаю, что если использовать свою функцию в замыкании, то возникает такая ошибка. Ссылочная прозрачность, епрст! Будущий я поймет, что проблема была во владении переменными, но даже с учетом этого описание ошибки все равно трешовое.
Еще одна ошибка с типами:
x += dx;
expected `i32`, found `i8`
Вот честно, я даже не хочу разбираться, в каком хитром кейсе я словлю проблем при добавлении 8-битного числа к 32-битному и как правильно сделать тут преобразование типов. Тут уже опускаешься даже ниже плюсов. При этом для ублажения компилятора достаточно сменить i8 на i32 — со сложением двух i32 проблем-то точно не будет, кек.
Дальше было трахание с указателями, статиками, замыканиями — очень интересно конечно… но хотелось бы попроще. Я вроде на современном языке пишу, а не на кроссплатформенном ассемблере.
Порадовал комментарий к замыканиям из примера wasm-bindgen:
Normally we'd store the handle to later get dropped at an appropriate
time but for now we want it to be a global handler so we use the
`forget` method to drop it without invalidating the closure. Note that
this is leaking memory in Rust, so this should be done judiciously!
Т.е. я использую Rust, чтобы достичь безопасной работы с памятью, но в итоге сам себе делаю утечку, тупо скопировав пример. Великолепно.
Хочу расшарить одну переменную на два места, чтобы одна функция читала, другая писала. Тут открывается миллион типов указателей, внутри которых еще и руками боксинг нужно делать. Плюсы отдыхают. Кое-как извратился через копию переменной и Rc. Уже устал от этого всего.
Еще всякие забавные мелочи были, например, приколы с неймингом: обнаружил, что есть flat_map, но не для Option. После Scala это выглядит странно. Еще забавное — нет унарного плюса (хотя мне бы он пригодился для читаемости).
Extension-методы — больше похожи на implicit class в Scala. Но еще и интерфейс надо определять обязательно (по крайней мере, как я понял). Не очень удобно для разового расширения, но enterprise-джавистам понравится.
Немного фронтенд-треша
Проблемы у меня возникли и по самой сути задачи двигающегося объекта: пришлось копаться с отличиями offsetWidth, clientWidth, scrollWidth, настоящими и CSS-пикселями, position fixed и absolute, нюансами margin (который зависит от тега и от браузера) и так далее. Без поллитры помощи друга не обошлось. Это, конечно, добавило мне “любви” к фронтенду.
Рефакторинг
Тем не менее, через некоторое время у меня получилось сделать что-то рабочее. Но это был один большой файл-помойка, который требовал рефакторинга. Казалось бы, что проще — нафигачил функций, да распихал по файлам.
Я думал, что вроде все пошло на лад, и у меня возникло ощущение, что я начал что-то понимать, пока опять не вляпался в синтаксис лямбд. И когда я захотел что-то выделить в виде обобщенной функции, то снова начались потрахушки с областями видимости и мутабельностью. Вроде почти решил через копирование данных на иммутабельных структурах, но вляпался опять в
error[E0277]: expected a `FnMut<()>` closure, found `[closure@src/dom_utils.rs:100:51: 110:6]`
Попробовал еще раз, с мутабельностью. Если использовать явно функцию — то все ок, если ее же передавать параметром — ошибка. Оказалось, что надо еще знать отличие между замыканием и указателем на функцию. Был еще один веселый прикольчик с
error[E0310]: the parameter type `TContext` may not live long enough
но это легко решилось.
Захотел выделить бойлерплейт для создания wasm-замыканий, но оказалось, что это сложно. Я поленился, потому что, по видимому, решение было близко к тому, что сокращение кода не сократило бы его, и решил попробовать другую фичу — макросы. Любители аббревиатур тут просто плясать могут: надо помнить, например, чем отличается tt от ty. Особенно весело читать это в первый раз в примерах. Через некоторое количество тупки у меня все-таки получилось сделать то, что я хотел, через макрос.
Потом я подумывал еще отрефакторить создание флага для остановки движения, но в какой-то момент решил, что хватит это терпеть. От перестановки кусочков местами нужно опять перепродумывать владение, потом наложатся еще замыкания… Это мне принесет не очень много нового опыта, а вот горения — предостаточно.
Заключение
Что получилось в итоге — можно посмотреть тут, а исходники — тут.
Сразу скажу, что хайп вокруг языка однозначно присутствует, и те, которые призывают переписать все на Rust — конченные люди. Я хотел бы сказать, что Rust все равно лучше чем Go, но наверно, все-таки нет.
Я ожидал язык высокого уровня, который за счет хороших абстракций решает проблемы с утечками памяти, присущие плюсам. А в итоге надо в голове держать полную модель памяти (и это чуть ли не сложнее чем помнить new/delete в старых плюсах), кто у кого что занял. Ссылочной прозрачности нет, и при простом рефакторинге нужно многое перепродумывать. Ошибки компилятора отлично говорят об ошибках, когда угадывают, что ты хотел, но почти бесполезны в ином случае.

У меня сложилось впечатление, что язык на самом деле низкого уровня, просто с сахаром. Надо понимать все чуть ли не на уровне ассемблера, но знать концепции на уровне Scala. Везде, везде сраные детали реализации. С числами два стула — либо использовать адекватные типы данных и постоянно конвертировать, либо забить и использовать везде один (как сделал я).
Вместо плюсов этот язык может чем-то и хорош. Но безопасности я в нем не очень почувствовал. Язык интересный и принуждает задумываться о других вещах, чем в мейнстриме, но я не почуствовал от этого большой пользы. Тяжело сосредоточиться на одном уровне абстракции — детали реализации всегда торчат наружу. Писать что-то на прикладном уровне на Rust — нет, спасибо.

Про лень и скачивание альбома из ВК
Я люблю автоматизацию, но иногда лень побеждает. Конечно, пока не настолько, чтобы менять URL в адресной строке браузера мышкой, “потому что лень клавиатуру вынимать”, но уже движусь к этому. А в итоге получается дедрофекальное программирование. Если вы не любите читать описание костылей или нытье, то можно проходить мимо этой заметки.
Захотел я скачать пару альбомов из ВК, продолжая его архивирование. Поискал что-нибудь онлайн — надо регистрироваться, да еще и входить там через VK надо — не, параноик во мне пока сильнее. Может, есть какое-нибудь расширение браузера, но искать рабочее тоже лень. Ладушки, попробуем через VK API сделать.
Но там тоже надо прокидывать свою авторизацию, либо вообще токены получать… Вроде правильный путь, но как подумаешь, что с этим возиться надо — ну его нафиг. Ведь к API мне нужно пару запросов всего послать. Потом я вспомнил, что запрос к API можно сделать прямо с сайта, через портал для разработчиков. Вот только даже с этим есть нюансы.
Во-первых, последняя версия API (5.126) вместо адекватных ссылок на изображение вернет массив с описаниями копий:
"sizes": [
{
"url": "https://pp.vk.me/c633825/v633825034/7369/wbsAsrooqfA.jpg",
"width": 130,
"height": 87,
"type": "m"
}, {
"url": "https://pp.vk.me/c633825/v633825034/736e/SKfi-9SeR0I.jpg",
"width": 200,
"height": 133,
"type": "p"
},
...
]
Конечно, это правильный подход с точки зрения API — ведь размеры могут поменяться с версиями, там еще большая вариативность для разных соотношений высоты и ширины картинки, удобно делать превьюшки и т.п. Но можно же было ссылку на оригинал как-нибудь отдельно поставить! Парсить сайт не хочется (хоть и умею, но не всю же жизнь краулер ВК писать). Написать код, который проходится по массиву и ищет картинку с максимальной шириной и/или высотой — задача для школьника, но даже этот код писать лень. Самое простое решение — переключиться на версию 5.21 и там поперек всех best-practice прочитать ссылку на максимальный размер из поля “photo_2560”.
Во-вторых, тот JSON, который показывается в окошке справа — не просто текст, а “красиво” отформатированный HTML. И если попробовать оттуда скопировать JSON, то ссылки будут урезанные, с троеточием: “https://sun9-30.u...Ktwc&type=album”. Это не наши©, подумал я. Благо есть инструменты разработчика в браузере и можно перехватить ответ сервера. Он будет примерно такого формата:
{
"payload": [
0,
["JSON с ответом API, сереализованный в строку"]
]
}
М-м-м, JSON-строка внутри JSON, мое любимое! Ну ладно, тут уже много мозгов не надо, сохраняем в файл, и накидываем немного питона:
import json
import sys
with open(sys.argv[1]) as f:
response = json.load(f)
photos = json.loads(response["payload"][1][0])
for photo in photos['response']['items']:
print(photo["photo_2560"])
Вывод можно кинуть либо в промежуточный файл, либо сразу в | xargs -P 10 -n 1 curl -sO, который знаком по предыдущей статье.
Одна проблемка осталась: название файла уж больно длинное и содержит куски запроса после ‘?’. И порядок фото будет случайный.
Немного мазохизма с башем приведут к такой комбинации:
| nl -nrz | xargs -L1 -P10 sh -c 'curl -s -o"$0.jpg" "$1"'
nl нумерует строки (но это можно сделать и через cat -n), а его аргумент -nrz добавляет нули справа для тех просмотрщиков фото, которые не умеют понимать человеческий порядок. А портянка с xargs работает через промежуточный шелл, чтобы можно было разделить аргументы. Это можно сделать и попроще: xargs -L1 -P10 curl -s -o, но тогда не будет расширения .jpg у файлов, а нормальное разбивать аргументы так, чтобы еще их можно было подставлять, xargs не умеет.
Что бы ни делать, лишь бы нормальный код не писать! Однако цель достигнута: ВК поруган, альбом скачан, полениться удалось, что-то новое узнать — тоже.
Должны ли аналитики и техписатели читать код, и в каком количестве нужна документация
На мой взгляд любой исполнитель должен быть не “специалистом по левой ноздре”, а хотя бы в общих чертах представлять весь процесс, в котором он участвует. Чем ближе процесс к нему, тем лучше он его должен представлять. Т.е. конкретный специалист он не потому, что знает только что-то одно, а потому что именно свою область знает лучше всех. Соответственно, программист должен знать, как составлять требования, как управлять проектом, как приоритезировать задачи и управлять бэклогом, как развертывать с нуля приложение на всех средах, как задокументировать изменения и т.п. При этом он может не вникать в какие-то мелкие детали, т.е. работа остальных специалистов для него серый ящик (ближе к белому), но ни в коем случае не черный.
Соответственно, в моем представлении хороший аналитик, как и любой другой специалист, должен понимать, в чем заключается работа программиста и как в общих чертах работает сервис. Более того, классический аналитик — это связующее звено между белой горячкой заказчика и рефакторным мракобесием/архитектурной упоротостью разработчика, поэтому он должен хорошо понимать как одного, так и другого.
Конкретнее относительно чтения кода: я считаю, что это вполне нормальное явление, когда аналитик или техписатель читает код, чтобы его задокументировать. Как минимум, это имеет смысл для прояснения узких кейсов и/или сложной бизнес-логики. На предыдущей работе у нас сложилась такая схема:
- Разработчик сам пишет документацию в общих словах по ключевым алгоритмам и в рамках выполнения тикета обновляет рабочую документацию в Wiki. Рабочкой пользуются все внутри команды, там написано разрабами для разрабов, но и другим членам команды понятно.
- Когда надо сдавать официальные доки, техписатель из рабочки создает документацию по всем ГОСТам, написанную для заказчика и его специалистов. Если что-то непонятно — читает код. Если что-то совсем не понятно — спрашивает разрабов.
Понятно, что не на каждый проект такое натянешь, но идея того, что техписатель читает код, на мой взгляд, вполне адекватна.
По поводу степени подробности документирования: тут важна золотая середина. Мало подробностей или ноль — документация бесполезна и никому не нужна (однако немного документации все-таки лучше, чем ноль). Много подробностей — много времени, чтобы ее постоянно актуализировать (или она устаревает), и ее тяжело хорошо структурировать. Мы исходили обычно из потребности. Т.е. есть какая-то база, дока на которую должна быть обязательна: краткое описание функции сервиса, перечень его контрактов, взаимодействие со внешними системами, крупными мазками схема с архитектурой (в мире ведь не только микросервисы с рестами бывают), конфигурация (если там что-то не очевидно). Кроме базы есть еще нюансы, нетривиальности и т.п., которые нужно описывать с бизнесовой или функциональной точки зрения, чтобы не только понимать, почему в коде наверчена нетривиальная шляпа, но и понять, когда ее можно убрать. И бывают сложные реализации, когда по какой-то причине не получилось сделать просто — это тоже описываем. На всякую мелочевку по реализации ответят код и юнит-тесты. А все остальное скорее всего очевидно и вряд ли кому-то нужно.
Я думаю, что документация должна быть частью процесса, но не единой сущностью с кодом. Все эти javadoc, doxygen и т.п. хороши для библиотек, когда тебе по-быренькому надо посмотреть что-нибудь и лень читать нормальную документацию. В обычном коде комментарии нужны только для неочевидной шляпы (и это реально редкий кейс). Документация именно кода скорее вредна — это будет либо капитан очевидность, либо суррогат нормальной документации. Если код нормально написан, то он самоописательный (самодокументирующийся).
Выбор библиотеки ассертов для проекта на Kotlin
В одном из старых проектов в кучу были навалены ассерты из JUnit, kotlin.test и AssertJ. Это было не единственной его проблемой: его вообще писали как письмо Дяди Федора, а времени остановиться и привести к единому виду не было. И вот это время пришло.
В статье будет мини-исследование про то, какие ассерты лучше по субъективным критериям. Хотел сначала сделать что-то простое: накидать набор тестов, чтобы быстренько копипастом клепать варианты. Потом выделил общие тестовые данные, некоторые проверки автоматизировал, и как поехало все… В результате получился небольшой розеттский камень и эта статья может пригодится вам для того, чтобы выбрать библиотеку ассертов, которая подойдет под ваши реалии.
Сразу оговорюсь, что в статье не будет сравнения фреймворков для тестирования, подходов к тестированию и каких-то хитрых подходов к проверке данных. Речь будет идти про несложные ассерты.

Если вам лень читать занудные рассуждения, историю моих мытарств и прочие подробности, то можете перейти сразу к результатам сравнения.
Немного бэкграунда
Долгое время моим основным ЯП была Scala, а фреймворком для тестов — ScalaTest. Не то чтобы это был лучший фреймворк, но я как-то к нему привык, поэтому мое мнение может быть искажено из-за этого.
Когда на старой работе начали писать на Kotlin, через какое-то время даже делали свою библиотечку, имитирующую поведение скаловских матчеров, но сейчас она имеет мало смысла после появления Kotest (хотя в ней лучше было реализовано сравнение сложных структур, с рекурсивным выводом более подробного сообщения).
Требования
Сразу оговорюсь, требования весьма субъективны и предвзяты, а часть — вообще вкусовщина. Требования получились такие:
- Бесшовная интеграция с Kotlin и IntelliJ Idea. Scala-библиотеки по этому принципу отпадают — извращаться с настройкой двух рантаймов нет желания. Несмотря на это, ScalaTest будет присутствовать в сравнении как отправная точка, просто потому что с ним много работал. Под интеграцией с IntelliJ я подразумеваю возможность клика на
<Click to see difference>, чтобы увидеть сравнение реального значения и ожидаемого. Эта фича, вообще говоря, работает в кишках IntelliJ Idea — но ведь разработчики Kotlin-библиотек наверно про нее все-таки слышали и могут решить эту проблему, да?
- Возможность быстро понять проблему. Чтобы было не
1 != 2и стектрейс, а нормальное сообщение, содержащее в идеале название переменной и разделение на “expected” и “actual”. Чтобы для коллекций было сообщение не просто “два множества на 100 элементов не равны, вот тебе оба в строковом представлении, ищи разницу сам”, а подробности, например “… эти элементы должны быть, а их нет, а вот эти не должны, но они есть”. Можно конечно везде описания самому писать, но зачем тогда мне библиотека? Как выяснилось чуть позже, название переменной — это была влажная мечта, и при недолгих раздумьях будет очевидно, что это не так-то просто сделать. - Адекватность записи.
assertEquals(expected, actual)— Йоды стиль читать сложно мне, вкусовщина однако это большая. Кроме того, я не хочу задумываться о тонких нюансах библиотеки — в идеале должен быть ограниченный набор ключевых слов/конструкций, и чтобы не надо было вспоминать особенности из серии “это массив, а не коллекция, поэтому для него нужен особый метод” или помнить, что строка неcontains, аincludes. Другими словами — это одновременно читаемость и очевидность как при чтении, так и при написании тестов. - Наличие проверки содержания подстроки. Что-то вроде
assertThat("Friendship").contains("end"). - Проверка исключений. В качестве контр-примера приведу JUnit4, в котором исключение ловится либо в аннотацию, либо в переменную типа
ExpectedExceptionс аннотацией@Rule. - Сравнение коллекций и содержание элемента(ов) в них.
- Поддержка отрицаний для всего вышеперечисленного.
- Проверка типов. Если ошибка будет выявлена компилятором — то это гораздо круче, чем если она будет выявлена при запуске теста. Как минимум, типизация не должна мешать: если мы знаем тип ожидаемого значения, то тип реального значения, возвращенного generic-функцией, должен быть выведен. Контр-пример:
assertThat(generic<Boolean>(input)).isEqualTo(true).<Boolean>тут лишний. Третий вариант заключается в игнорировании типов при вызове ассерта. - Сравнение сложных структур, например двух словарей с вложенными контейнерами. И даже если в них вложен массив примитивов. Все же знают про неконсистентность их сравнения? Так вот ассерты — это последнее место, где я хочу об этом задумываться, даже если это отличается от поведения в рантайме. Для сложных структур по-хорошему должен быть рекурсивный обход дерева объектов с полезной информацией, а не тупо вызов equals. Кстати в той недо-библиотеке на старой работе так и было сделано.
Не будем рассматривать сложные поведенческие паттерны или очень сложные проверки, где надо у объекта человек прям сразу проверить, что он и швец, и жнец, и на дуде играет, и вообще хороший парень в нужном месте и время. Повторюсь, что цель — подобрать ассерты, а не фреймворк для тестов. И ориентир на разработчика, который пишет юнит-тесты, а не на полноценного QA-инженера.
Конкурсанты
Перед написанием этой статьи я думал, что достаточно будет сравнить штук 5 библиотек, но оказалось, что этих библиотек — пруд пруди.
Я сравнивал следующие библиотеки:
- ScalaTest — как опорная точка для меня.
- JUnit 5 — как опорная точка для сферического Java-разработчика.
- kotlin.test — для любителей multiplatform и официальных решений. Для наших целей — это обертка над JUnit, но есть нюансы.
- AssertJ — довольно популярная библиотека с богатым набором ассертов. Отпочковалась от FestAssert, на сайте которого по-японски торгуют сезамином по всем старым ссылкам на документацию.
- Kotest — он же KotlinTest, не путать с kotlin.test. Разработчики пишут, что их вдохновлял ScalaTest. В кишках есть даже сгенерированные функции и классы для 1-22 аргументов — в лучших традициях scala.
- Truth — библиотека от Гугла. По словам самих создателей, очень напоминает AssertJ.
- Hamсrest — фаворит многих автотестировщиков по мнению Яндекса. Поверх нее еще работает valid4j.
- Strikt — многим обязан AssertJ и по стилю тоже его напоминает.
- Kluent — автор пишет, что это обертка над JUnit (хотя на самом деле — над kotlin.test), по стилю похож на Kotest. Мне понравилась документация — куча примеров по категориям, никаких стен текста.
- Atrium — по словам создателей, черпали вдохновение из AssertJ, но потом встали на свой путь. Оригинальная особенность — локализация сообщений ассертов (на уровне импорта в maven/gradle).
- Expekt — черпали вдохновение из Chai.js. Проект заброшен: последний коммит — 4 года назад.
- AssertK — как AssertJ, только AssertK (но есть нюансы).
- HamKrest — как Hamсrest, только HamKrest (на самом деле от Hamcrest только название и стиль).
Если вы хотите нарушить прекрасное число этих конкурсантов — пишите в комментах, какую достойную сравнения библиотеку я упустил или делайте пулл-реквест.
Эволюция методики оценки
Когда уже написал процентов 80 статьи и добавлял все менее известные библиотеки, наткнулся на репозиторий, где есть сравнение примерно в том виде, что мне думалось изначально. Возможно кому-то там проще будет читать, но там меньше конкурсантов.
Сначала я создал набор тестов, которые всегда валятся, 1 тест — 1 ассерт. Несмотря на то, что я люблю автоматизировать всякую дичь, писать какую-то сложную лабуду для проверки требований мне было откровенно лень, поэтому я планировал проверять все почти вручную и вставить шутку “то самое место, где вы можете влепить минус за “низкий технический уровень материала””.
Потом решил, что все-таки надо защититься от банальных ошибок, и средствами JUnit сделал валидатор, который проверяет, что все тесты, которые должны были завалиться, завалились, и что нет неизвестных тестов. Когда наткнулся на баг в ScalaTest, решил сделать две вариации: одна, где все тесты проходят, вторая — где ничего не проходит и дополнил валидатор. Внимательный читатель может спросить: а кто стрижет брадобрея и какие ассерты использованы там? Отчасти для объективности, отчасти для переносимости ассертов там вообще нет:). Заодно будет демо/аргумент для тех, кто считает, что ассерты не нужны вообще.
Затем я оказался на распутье: выносить ли или нет константы типа listOf(1,2,3)? Если да — то это упоротость какая-то, если нет — то при переписывании теста на другие ассерты обязательно ошибусь. Составив список библиотек, которые стоит проверить для претензии на полноту исследования, я плюнул и решил решить эту проблему наследованием: написал общий скелет для всех тестов и сделал интерфейс для ассертов, который нужно переопределить для каждой библиотеки. Выглядит немного страшновато, зато можно использовать как розеттский камень.
Однако есть проблема с параметризованными проверками и type erasure. Reified параметры могут быть только в inline-функциях, а их переопределять нельзя. Поэтому хорошо заиспользовать конструкции типа
assertThrows<T>{...}
в коде не получится, пришлось использовать их дополнения без reified параметра:
assertThrows(expectedClass){...}
Я честно немного поковырялся в этой проблеме и решил на нее забить. В конце концов, в kotlin.test есть похожая проблема с интерфейсом Asserter: ассерт на проверку исключения в него не включен, и является внешней функцией. Чего мне тогда выпендриваться, если у создателей языка та же проблема?:)
Весь получившийся код можно посмотреть в репозитории на GitHub. После накрученных абстракций вариант со ScalaTest я оставил как есть, и положил в отдельную папку отдельным проектом.
Результаты
Дальше тупо суммируем баллы по требованиям: 0 — если требование не выполнено, 0.5 — если выполнено частично, 1 — если все в целом ок. Максимум — 9 баллов.
По-хорошему, надо расставить коэффициенты, чтобы более важные фичи имели больший вес. А по некоторым пунктам так вообще дробные оценки давать. Но я думаю, что для каждого эти веса будут свои. В то же время, хоть как-то табличку мне надо было отсортировать, чтобы “скорее хорошие” библиотеки были наверху, а “скорее не очень” библиотеки были внизу. Поэтому я оставил тупую сумму.
| Библиотека | Интеграция | Описание ошибки | Читабельность | Подстрока | Исключения | Коллекции | Отрицания | Вывод типов | Сложные структуры | Итого |
|---|---|---|---|---|---|---|---|---|---|---|
| Kotest | ± | ± | + | + | + | + | + | нет | + | 7.0 |
| Kluent | ± | ± | + | + | + | + | + | нет | - | 6.0 |
| AssertJ | ± | + | ± | + | ± | + | + | нет | ± | 6.0 |
| Truth | ± | + | + | + | - | + | + | нет | - | 5.5 |
| Strikt | ± | ± | ± | + | + | + | + | нет | - | 5.5 |
| ScalaTest | ± | ± | ± | + | + | + | + | нет | - | 5.5 |
| HamKrest | ± | - | ± | + | + | ± | + | да | - | 5.5 |
| AssertK | ± | ± | ± | + | ± | + | + | нет | - | 5.0 |
| Atrium | ± | ± | ± | + | + | ± | + | нет | - | 5.0 |
| Hamсrest | ± | ± | ± | + | - | ± | + | да | - | 5.0 |
| JUnit | + | + | - | ± | + | - | ± | игнор | - | 4.5 |
| kotlin.test | + | ± | - | - | + | - | - | да | - | 3.5 |
| Expekt | ± | ± | - | + | - | ± | + | нет | - | 3.5 |
Примечания по каждой библиотеке:
Kotest
- Чтобы подключить только ассерты, надо немного поковыряться. На мой взгляд сходу это понять тяжело.
- Не имеет варианта ловли исключения с явным параметром, а не reified, но это на самом деле не особо и нужно: мало кто будет заниматься такими извращениями.
- Сложные структуры: тест с вложенными массивами не прошел. Я завел на это тикет. UPD: Через месяц его пофиксили, и мой тест прошел. Разработчик даже сделал пулл-реквест в мой репозиторий с тестами.
- Интеграция:
<Click to see difference>есть только для простых ассертов. - Типизация: иногда при использовании дженериков надо писать им явный тип.
- Описание ошибок: почти идеальное, не хватило только подробностей отличия двух множеств.
Kluent
- Можно писать как
"hello".shouldBeEqualTo("hello"), так и"hello" `should be equal to` "hello". Любителям DSL понравится. - Интересная запись для ловли исключения:
invoking { block() } shouldThrow expectedClass.kotlin withMessage expectedMessage - Описания ошибок в целом отличные, не нет подробностей отличия двух коллекций, что не так. Еще расстроила ошибка в формате
Expected Iterable to contain none of "[1, 3]"— непонятно, что на самом деле проверяемый Iterable содержит. - Интеграция:
<Click to see difference>есть только для простых ассертов. - Сложные структуры: тест с вложенными массивами не прошел.
AssertJ
- Впечатляющее количество методов для сравнения — еще бы запомнить их… Надо знать, что списки надо сравнивать через
containsExactly, множества — черезhasSameElementsAs, а словари — через.usingRecursiveComparison().isEqualTo. - Интеграция:
<Click to see difference>есть только для простых ассертов. - Исключения: ловится просто какое-то исключение, а не конкретное. Сообщение об ошибке, соответственно, не содержит название класса.
- Сложные структуры: есть
.usingRecursiveComparison(), который почти хорошо сравнивает. Однако ошибку хотелось бы иметь поподробнее: ассерт определяет, что значения по одному ключу не равны, но не говорит по какому. И несмотря на то, что он корректно определил, что два словаря с массивами равны, отрицание этого ассертасработало некорректно: для одинаковых структур не завалился тест на их неравенство.assertThat(actual) .usingRecursiveComparison() .isNotEqualTo(unexpected) - Типизация: иногда при использовании дженериков надо писать им явный тип. Видимо, это ограничение DSL.
Truth
- Подробные сообщения об ошибках, иногда даже многословные.
- Исключения: не поддерживаются, пишут, что надо использовать
assertThrowsиз JUnit5. Интересно, а если ассерты не через JUnit запускают, то что? - Читаемость: кроме прикола с исключением, странное название для метода, проверяющего наличие всех элементов в коллекции:
containsAtLeastElementsIn. Но я думаю на общем фоне это незначительно, благо тут можно для сравнения коллекций не задумываясь писатьassertThat(actual).isEqualTo(expected). - Интеграция:
<Click to see difference>только для примитивного ассерта. - Сложные структуры: тест с вложенными массивами не прошел.
- Типизация: тип не выводится из ожидаемого значения, пришлось писать явно.
- Веселый стектрейс с сокращалками ссылок “для повышения читаемости”:
expected: 1 but was : 2 at asserts.truth.TruthAsserts.simpleAssert(TruthAsserts.kt:10) at common.FailedAssertsTestBase.simple assert should have descriptive message(FailedAssertsTestBase.kt:20) at [[Reflective call: 4 frames collapsed (https://goo.gl/aH3UyP)]].(:0) at [[Testing framework: 27 frames collapsed (https://goo.gl/aH3UyP)]].(:0) at java.base/java.util.ArrayList.forEach(ArrayList.java:1540) at [[Testing framework: 9 frames collapsed (https://goo.gl/aH3UyP)]].(:0) at java.base/java.util.ArrayList.forEach(ArrayList.java:1540) at [[Testing framework: 9 frames collapsed (https://goo.gl/aH3UyP)]].(:0) at java.base/java.util.ArrayList.forEach(ArrayList.java:1540) at [[Testing framework: 17 frames collapsed (https://goo.gl/aH3UyP)]].(:0) at org.gradle.api.internal.tasks.testing.junitplatform.JUnitPlatformTestClassProcessor$CollectAllTestClassesExecutor.processAllTestClasses(JUnitPlatformTestClassProcessor.java:99) ...
Strikt
- Не имеет варианта ловли исключения с явным параметром, а не reified, но это на самом деле не особо и нужно: мало кто будет заниматься такими извращениями.
- Отрицание для содержания подстроки в строке выглядит неконсистентно:
expectThat(haystack).not().contains(needle), хотя для коллекций есть нормальныйexpectThat(collection).doesNotContain(items). - Читаемость: для массивов надо использовать
contentEquals. Та же проблема с отрицанием:expectThat(actual).not().contentEquals(unexpected). Более того, надо еще думать о типе, потому что дляArray<T>Strikt почему-то не смог определить нужный ассерт сам. Для списков —containsExactly, для множеств —containsExactlyInAnyOrder. - Типизация: иногда при использовании дженериков надо писать им явный тип. Более того, для массивов нужно еще с вариацией правильно тип подобрать. Посмотрите на этот кусочек кода:
Он не скомпилируется, потому что компилятор не сможет определить перегрузку для
val actual: Array<String> = arrayOf("1") val expected: Array<String> = arrayOf("2") expectThat(actual).contentEquals(expected)contentEquals. Это происходит потому, что нужныйcontentEqualsопределен с ковариантным типом:
Из-за этого надо писатьinfix fun <T> Assertion.Builder<Array<out T>>.contentEquals(other: Array<out T>)val actual: Array<out String> = arrayOf("1") val expected: Array<String> = arrayOf("2") expectThat(actual).contentEquals(expected) - Интеграция: нет
<Click to see difference>. - Описание ошибки: нет подробностей для словаря и массивов, а целом довольно подробно.
- Сложные структуры: тест с вложенными массивами не прошел.
ScalaTest
- Интеграция: при сравнении коллекций нельзя открыть сравнение.
- Описание ошибки: в коллекциях написано, что просто не равны. Для словаря тоже подробностей нет.
- Читабельность: надо помнить об особенностях DSL при отрицании и
contains, отличииcontainsиinclude, а также необходимостиtheSameElementsAs. - Сложные структуры: тест с вложенными массивами не прошел, на это есть тикет.
- Типизация: тип не выводится из ожидаемого значения, пришлось писать явно.
Hamkrest
- Проект, судя по тикетам, в полузаброшенном состоянии. Вдобавок документация весьма жиденькая — пришлось читать исходный код библиотеки, чтобы угадать название нужного матчера.
- Ожидал, что достаточно сменить импорты Hamcrest, но не тут-то было: довольно многое тут по-другому.
- Запись ловли исключений — зубодробительная:
assertThat( { block() }, throws(has(RuntimeException::message, equalTo(expectedMessage)))) - Коллекции: нет проверки наличия нескольких элементов. Пулл-реквест висит 3,5 года. Написал так:
assertThat(collection, allOf(items.map { hasElement(it) })). - Поддержки массивов нет.
- Сложные структуры: тест с вложенными массивами не прошел.
- Интеграция: нет
<Click to see difference>. - Описание ошибки — как-то ни о чем:
expected: a value that not contains 1 or contains 3 but contains 1 or contains 3
AssertK
- Как можно догадаться из названия — почти все совпадает с AssertJ. Однако синтаксис иногда немного отличается (нет некоторых методов, некоторые методы называются по-другому).
- Читаемость: Если в AssertJ написано
assertThat(collection).containsAll(items), то в AssertK та же конструкция сработает неправильно, потому что в немcontainsAllпринимаетvararg. Понятно, что цель наcontainsAll(1,2,3), но продумать альтернативный вариант стоило бы. В некоторых других библиотеках есть похожая проблема, но в них она вызывает ошибку компиляции, а тут — нет. Причем разработчикам проблема известна — это один из первых тикетов. Вдобавок, нужно отличатьcontainsOnlyиcontainsExactly. - Интеграция: нет
<Click to see difference>. - Исключения: ловится просто какое-то исключение, а не конкретное, потом его тип надо отдельно проверять.
- Сложные структуры: аналога
.usingRecursiveComparison()нет. - Типизация: иногда при использовании дженериков надо писать им явный тип.
- Описания ошибок — подробности есть (хоть и не везде), но местами странные:
Вот почему тут на первый индекс два сообщения?expected to contain exactly:<[3, 4, 5]> but was:<[1, 2, 3]> at index:0 unexpected:<1> at index:1 unexpected:<2> at index:1 expected:<4> at index:2 expected:<5>
Atrium
- Поставляется в двух вариантах стиля: fluent и infix. Я ожидал отличий вида
assertThat(x).isEqualTo(y)противx shouldBe y, но нет, этоexpect(x).toBe(y)противexpect(x) toBe y. На мой взгляд весьма сомнительная разница, с учетом того, что инфиксный метод можно вызвать без “инфиксности”. Однако для инфиксной записи иногда нужно использовать объект-заполнительo:expect(x) contains o atLeast 1 butAtMost 2 value "hello". Вроде объяснено, зачем так, но выглядит странно. Хотя в среднем по больнице мне нравится infix-ассерты (вертолеты из-за скаловского прошлого), для Atrium я писал во fluent-стиле. - Читабельность: странные отрицания:
notToBe, ноcontainsNot. Но это не критично. Пришлось думать, как сделать проверку наличия нескольких элементов в коллекции:containsпринимаетvararg, аcontainsElementsOfне может вывести тип, сделал тупой каст. Понятно, что цель наcontains(1,2,3), но продумать альтернативный вариант стоило бы. Отрицание наличия нескольких элементов записывается какexpect(collection).containsNot.elementsOf(items). - Поддержки работы с массивами нет, рекомендуют преобразовывать через
toList. - Не имеет варианта ловли исключения с явным параметром, а не reified, но это на самом деле не особо и нужно: мало кто будет заниматься такими извращениями.
- Сложные структуры: тест с вложенными массивами не прошел.
- Интеграция: нет
<Click to see difference>. - Описание ошибки: местами нет подробностей (при сравнении словарей, например), местами описание довольно запутанное:
expected that subject: [4, 2, 1] (java.util.Arrays.ArrayList <938196491>) ◆ does not contain: ⚬ an entry which is: 1 (kotlin.Int <211381230>) ✘ ▶ number of such entries: 1 ◾ is: 0 (kotlin.Int <1934798916>) ✔ ▶ has at least one element: true ◾ is: true - Типизация: иногда при использовании дженериков надо писать им явный тип.
Hamcrest
- Читабельность: странный синтаксис для отрицаний (либо
assertThat(actual, `is`(not(unexpected)))
либо
assertThat(actual, not(unexpected))
Надо знать нюанс containsString vs contains vs hasItem vs hasItems. Пришлось думать, как сделать проверку наличия нескольких элементов в коллекции: hasItems принимает vararg, а Set<T> без знания T просто так не преобразуешь в массив. Понятно, что цель на hasItems(1,2,3), но продумать альтернативный вариант стоило бы. Получилось в итоге
assertThat(collection, allOf(items.map { hasItem(it) }))
С отрицанием еще веселее:
assertThat(collection, not(anyOf(items.map { hasItem(it) })))
- В продолжение этой вакханалии с
hasItems, я поставил ± в графу “коллекции”, потому что лучше б не было ассертов, чем такие. - Исключения: отдельной проверки нет.
- Интеграция: нет
<Click to see difference>. - Описание ошибки: для коллекций нет подробностей.
- Сложные структуры: тест с вложенными массивами не прошел.
JUnit
- Читабельность: Йода-стиль
assertEquals(expected, actual), надо помнить нюансы и отличия методов: что массивы надо сравнивать черезassertArrayEquals, коллекции черезassertIterableEqualsи т.п. - Описание ошибок: для тех случаев, когда у JUnit все-таки были методы, оно было вполне нормальным.
- Подстрока: через
assertLinesMatch(listOf(".*$needle.*"), listOf(haystack))конечно можно, но выглядит это не очень. - Отрицания: нет отрицания для
assertLinesMatch, что логично, нет отрицания дляassertIterableEquals. - Коллекции: нет проверки содержания элемента,
assertIterableEqualsдляMapиSetне подходит совсем, потому что ему важен порядок. - Сложные структуры: тупо нет.
kotlin.test
- Очень бедно. Вроде как это должна быть обертка над JUnit, но методов там еще меньше. Очевидно, что это расплата за кроссплатформенность.
- Проблемы те же, что и у JUnit, и плюс к этому:
- Нет проверки подстроки.
- Нет даже намека на сравнения коллекций в лице
assertIterableEquals, нет сравнения массивов. - Типизация: JUnit’у пофиг на типы в
assertEquals, а kotlin.test ругнулся, что не может вывести тип. - Описание ошибок: не по чему оценивать.
Expekt
- Можно писать в двух стилях
expect(x).equal(y)иx.should.equal(y), причем второй вариант не инфиксный. Разница тут ничтожна, выбрал второй. - Читабельность:
contains(item)противshould.have.elements(items)иshould.contain.elements(items). Причем есть приватный методcontainsAll. Пришлось думать, как сделать проверку наличия нескольких элементов в коллекции:should.have.elementsпринимаетvararg. Понятно, что цель наshould.have.elements(1,2,3), но продумать альтернативный вариант стоило бы. Для отрицания нужно еще вспомнить проany:.should.not.contain.any.elements. - Типизация: тип не выводится из ожидаемого значения, пришлось писать явно.
- Поддержки исключений нет.
- Поддержки массивов нет.
- Сложные структуры: тест с вложенными массивами не прошел.
- Описание ошибки: просто разный текст для разных ассертов без подробностей.
- Интеграция: нет
<Click to see difference>.
Заключение
Лично мне из всего этого разнообразия понравились Kotest, Kluent и AssertJ. В целом я в очередной раз опечалился тому, как фигово работать с массивами в Kotlin и весьма удивился, что нигде кроме AssertJ нет нормального рекурсивного сравнения словарей и коллекций (да и там отрицание этого не работает). До написания статьи я думал, что в библиотеках ассертов эти моменты должны быть продуманы.
Что в итоге выбрать — еще предстоит решить команде, но насколько мне известно, большинство пока склоняется к AssertJ. Надеюсь, что и вам эта статья пригодилась и поможет вам выбрать библиотеку для ассертов, подходящую под ваши нужды.
Опросы:
- А какая библиотека больше всего нравится вам?
- Какой библиотекой пользуетесь?
UPD
Статья удостоилась репоста.
Разработчик Kotest пофиксил проблему со сложными структурами и даже сделал пулл-реквест в мой репозиторий с тестами. Обновил статью.
Как найти что-то из своего во ВКонтакте и немного grep-магии
Когда я собирал свои смешнявки для галереи, взбрело мне в голову посмотреть, что там есть в ВК — вдруг что-то смешное я сделал и отослал через него? Если смотреть все вручную, то так можно и кукухой поехать, поэтому я решил поехать кукухой автоматизированно.
Disclaimer: Длительное чтение историй своих переписок 10-летней давности может привести к необратимым повреждениям психики и к потере кучи времени. Повторять описанное стоит с максимальными мерами предосторожности.
Кому не интересно нудное описание, что есть и чего нет в архиве — листайте до заголовка Ищем информацию
Скачиваем архив с данными
С этим все почти просто. Заходим по ссылке, запрашиваем архив. Есть нюанс: для скачивания понадобится привязка к мобильному устройству и/или к мобильному телефону, так что если вы до сих пор злостный анон, ВК захочет вас послать. Не забудьте в настройках поставить все галочки — по умолчанию они не все установлены.
Мой архив был готов через пару часов после запроса.
Смотрим, что внутри
Первое, что бросается в глаза — очень маленький размер архива, всего 13 мегабайт. Я в ВК 14 лет и в моей жизни был период, когда “вся жизнь там”. Очень сомнительно звучит, что “это самый полный архив”.
Внутри лежит поганый HTML. С одной стороны — удобно для обывателя, но с другой — я ожидал выгрузку в машиночитаемом формате. Те же операторы связи закинут список ваших звонков в CSV. Или телега, которая дает выбор — либо красивую HTML-ку, либо JSON (правда, для индивидуальных чатов — только HTML). Ну ладно, это не самое страшное.
Вишенкой к формату идет кодировка — конечно же, это всеми любимая CP1251. Ну, хоть не KOI8-R, и на том спасибо.
Малый размер объясняется тем, что внутри только текстовая информация. Картинок нет, только ссылки на них. При этом телега честно скачает, если ее попрость, а тут такой опции нет. Получается, что как бэкап этот архив использовать не получится. Истории тоже особо нет, только та информация, которую и без этого архива можно посмотреть на сайте. С некоторыми оговорками — см. далее.
Что в итоге есть?
Информация о профиле
Которую и так видно на главной странице. Всякие вузы, интересы, даты рождения, отношения к алкоголю и т.п.
Список друзей
Для каждого друга покажут: текущее имя или DELETED, ссылку на страницу и дату добавления в друзья (текстом). При этом примерно до июня 2009 года текст даты будет “очень давно”.
Подарки
Картинка, ссылка на профиль подарившего, дата.
Подписки
Тупо список пабликов с ссылкой на них. Иногда с пометкой “Администратор” или “Владелец”.
Черный список
В формате списка друзей, только вместо “очень давно” — “Дата добавления неизвестна”. И DELETED может быть не только ссылкой, но и просто текстом. Спасибо, ВК, теперь я знаю, что у меня в черном списке есть
DELETED
Дата добавления неизвестна
Сообщения
Разбиты по диалогам. Только текстовая информация. Даже картинки указаны голой ссылой, а не в <img> теге. Даты, разумеется, только текстом. Часть контента просто заменяется текстом, например, сообщение может содержать только “пересланное сообщение” без ссылки — и решай ребус, что же ты там такого переслал. Особенно если это чат с DELETED. Похожая ситуация с “1 прикреплённое сообщение” и “Запись на стене”.
Вы, 17 мая 2018 в 16:39:27
2 прикреплённых сообщения
Возникают также сомнения, что история сообщений действительно вся: скорее всего только то, что и так через интерфейс можно посмотреть. Но проверять уже желания нет. “Этот вопрос оставлен как упражение читателю”, как говорится.
Стена
Примерно в том же формате, что и сообщения, но еще есть ссылка на оригинал. Репосты раскрываются, а не показываются дурацкосй строкой вроде “Запись на стене”. Однако “Аудиозапись” и “Граффити” — без ссылки. Посты от других людей на стене тоже есть. И даже есть ссылка на комментарии к записи, которые в этом же архиве.
Лайки
5 категорий: Фото, Видео, Стена, Заметки, Товары. В каждой — список ссылок. Тут хотя бы логично, хотя насколько я знаю, даты лайков ВК тоже знает.
Фотографии
Альбомы из профиля и вдобавок фотографии со страницы, со стены, сохраненные и из “фото со мной”. Для альбомов есть даты сохранения и обновления. Фотки в таком же формате, как и стена, со ссылкой на комменты. Но зато сама фотка вставлена <img> тегом.
Видео
Загруженные и добавленные. Как фотки (есть превьюшка), есть еще длительность и количество просмотров. Но прямой ссылки на скачивание нет.
Музыка
Список композиций с именем и длительность, без ссылок.
Документы
Список с датой загрузки, названием файла и ссылкой на него в документах. Никаких превью и прямых ссылок на скачивание.
Товары
К сожалению, я не настолько успешен, чтобы иметь свой бизнес в ВК, поэтому у меня тут пусто.
Истории
Aka “сториз”. Не умею таких делать, и тут у меня тоже пусто.
Приложения
Список текущих приложений с названием, ссылкой, правами доступа в формате “кучей через запятую” и датой в формате “Дата последнего запуска неизвестна”.
Закладки
Нет, не те. Страницы, записи, видео, товары, статьи, ссылки, подкасты. Везде “Данных нет”.
История изменений
Для имени, почты и телефонов. У меня там пусто, но вот немного печалит, что мне суют всяких DELETED, когда ВК все это про них знает. Привязки к телефонам по классике: “Привязан номер телефона 1234547”. Ишь чего, машиночитаемый формат захотел!
Платежи
Все, чего у меня нет: карты, история платежей, голоса, голоса внутри приложений, подписки, история переводов.
Реклама
Это уже поинтереснее: всего этого не посмотришь на сайте. Ретаргетинг:
Вы попали в 3271 группу ретаргетинга
Кабинет пользователя
Что бы это ни значило.
Интересы
Бизнес
Пользовательский интерес
ИТ (компьютеры и софт)
Пользовательский интерес
Образование
Пользовательский интерес
iPad
Системный сегмент
Firefox
Системный сегмент
Windows 10
Системный сегмент
Android (бюджетные)
Системный сегмент
Друзья именинников — всех, 3 дня
Системный сегмент
Друзья именинников — всех, 7 днeй
Системный сегмент
Друзья именинников — женщин, 3 дня
Сторонний сегмент
Друзья именинников — женщин, 7 дней
Сторонний сегмент
Образование
Пользовательский интерес
Наука и техника
Пользовательский интерес
Общество
Пользовательский интерес
Интересы к “Windows 10” и “Android (бюджетные)” даже натолкнули на мысль, что меня ломанули. Но в целом нормальный список, понимаешь, почему тебе суют рекламу IT-конференций.
В “Кабинетах” и “Часто посещаемых местах” закономерно пусто, но про последние не очень ясно, что они делают в рекламе.
Прочее
“Обращения в Поддержку”: только в новую, в старую — нет. Блокировки: когда блокировали вход в страницу и почему. “Сеансы авторизации”: только недавние, с именем, User-Agent и IP. “Импортированные контакты”: из почты, телефона, Twitter, FB, G+ и ОК — там у меня пусто. “Верификация”: для тех, у кого галочка рядом с именем.
Комментарии
Одной большой кучей. Текст, ссылка на оригинал и дата. Комментарии могут быть:
- к публикациям на вашей стене.
- к публикациям на чужих стенах, в т.ч. в пабликах. Причем даже если владелец стены их скрыл.
- комментариями от имени сообщества, если писал от его имени.
- ВНЕЗАПНО публикациями в пабликах — когда пишешь на стену паблика от своего имени. Почему ВК считает это комментарием — непонятно.
Приятный бонус заключается в том, что можно прочитать комментарии к постам, доступа к которым уже нет.
Немного удручает, что нет никакой информации о том, что комментируешь, только ссылка. Особенно прикольно, когда есть id стены, профиль удален, из текста непонятно, кому ты это писал — и решай ребус, что это за чел. Иногда помогает гугление (причем гугл может не помнить, а яндекс выдаст результат, но, опять же, не для всех).
Чего в архиве точно нет
Если вы надеялись, что в архиве будет суперполное досье на вас, то у меня для вас печальные новости: ВК явно хранит данных о вас гораздо больше, чем присылает в архиве. Я приведу список того, чего точно нет, но я наверняка о чем-то забыл. А чего-то вообще не знаю.
Обсуждений в группах
Имеются в виду те, которые отдельно от стены.
Постов от имени сообщества
Если вы админ сообщества и на стену публиковали записи от имени сообщества, то их не будет. Не важно, подписывались ли вы своим именем или нет. Забавно с учетом того, что комментарии от имени сообщества в архиве есть.
Постов на чужих стенах
С учетом того, что записи на стенах пабликов есть — очень странно.
Некоторых комментариев
Например, к фотографиям в чужих альбомах. Комментариев, отправленных через виджет ВК на сторонних сайтах. Возможно, еще каких-то.
Обращений в старую поддержку и баг-репортов
Отчетливо помню, как парочку багов заводил. Баг-репорты, видимо, сгинули вместе со старым баг-трекером, как и обращения в ТП. Второе может быть объяснено тем, что обращение осуществлялось через обсуждения в специальном паблике.
Мнений
Олды помнят, как говорится. Когда-то давно были “мнения”, где человеку можно было анонимно написать что-нибудь. Прикольно, правда? Ну это хотя бы можно понять: сейчас такого уже нет, сервак отключили, данные удалили и все это забыли.
Закладок людей
Да, в ВК можно добавлять людей в закладки. У меня там 25 человек, которые не в друзьях. И этого в архиве нет, хотя другие закладки есть.
Немного про безопасность
Все ссылки на фото (даже которые в личке грузили!) являются публично доступными. СЕСУРИТИ. Документы хоть закрыты — но за это ВК уже нагибали. Так что если вы слали нюдсы в личных сообщениях, то не такие уж они и приватные. Хотя вряд ли это вас смутит, если вы шлете дикпики через интернет.
Ищем информацию
Текст
Наконец-то можно приступить к поиску иголки в стоге сена. Начнем с поиска текста. Самый очевидный вариант — это grep, но если вы попробуете что-то поискать, то вас будет ждать облом. Потому что кодировка не та. Чтобы это исправить, поможет iconv, который умеет конвертировать данные между разными кодировками:
grep -Rnia "$(iconv -t CP1251 <<<'привет')" . | iconv -f CP1251
Не забудьте флаг a, который говорит grep, что мы работаем с бинарным форматом, иначе он будет спамить текстом Binary file matches.
Однако и с такой командой есть проблема: несмотря на флаг -i, который нам говорит игнорировать регистр, grep ничего не знает о нашей кодировке и не знает, что ‘п’ и ‘П’ — это одна буква. Поэтому спереди надо дописать LC_CTYPE=ru_RU.CP1251.
Стоит также учесть, что всякие знаки препинания в html записаны мнемониками или кодом, поэтому писать их в шаблоне поиска не стоит.
Комментарии мне было удобно читать по обсуждениям. Чтобы выдрать все обсуждения, в которых поучаствовали, выполняем
grep -Raioh 'https://vk.com/wall[^?]*' ../Archive/comments | sort | uniq
Довольно много комментариев будут на вашей стене, лучше отфильтровать по своему id. Повторюсь, что есть скрытые комментарии. Судя по всему, они появились следующим образом: пользователь закрыл комменты к своей стене. По крайней мере, API ВК пишет Access to post comments denied.
Картинки
С поиском по картинкам сами знаете, как обстоят дела, поэтому придется их смотреть своими глазами. Но для этого их надо сначала скачать. Если вы дата сатанист, то все равно в хозяйстве пригодится — какую-нибудь очередную генерилку треша написать, например. У меня в личке было всего полторы тысячи картинок.
Качать будем из сообщений, т.к. на стене — только ссылки на посты. Но если нужны картинки со стены — они есть в альбомах. Насчет комментариев — не знаю, не нашел у себя ни одного комментария с картинкой.
Включаем grep-магию:
grep -RiohPa "attachment__link' href='\K.*?(?=')" ../Archive/messages | grep 'userapi' | xargs -P 10 -n 1 curl -sO
Что тут происходит? Мы занимаемся запрещенными темными искусствами — парсим HTML с помощью регулярных выражений :) И не простых, а перловых (-P), да еще с positive look-ahead ((?=)) и zero-width look-behind (\K). Флаг -o говорит нам о том, что нас интересует только совпадение, т.е. сама ссылка, которая находится после href в одинарных кавычках. Подробнее про это можно почитать на Unix StackExchange.
Потом выбираем ссылки только на картинки, которые хранятся на серверах ВК. А дальше с помощью xargs в 10 потоков скачиваем все через curl. Подробнее про связку xargs с curl. Клево, но будут потенциальные проблемы, если что-то не получится загрузить. Тогда было бы мудрее записать все в файл, убрав дубликаты (у меня штук 30 было), и потом сверять список скачанного и список из файла.
Если нужны картинки из фоток, то можно немного поменять первую команду:
grep -RiohPa "img src=\"\K.*?(?=\")" ../Archive/photos/
Ссылки
Пришлось добавить вариантов завершения ссылки, т.к. она может быть текстом. А еще в HTML от ВК где-то двойные кавычки используются, а где-то одинарные.
grep -Raioh 'https\?://[^"<'\'']*' ../Archive | grep -v -e 'vk.com/wall' -e 'www.w3.org' -e 'vk.com/id' | sort | uniq > all_links.txt
Второй grep отсеивает лишние результаты: ссылки на стены и профили ВК, строку с ссылкой на стандарт из шапки. Дальше можно анализировать этот список как душе угодно: читать все подряд, искать grepом интересное, удалить к чертям.
Можно посмотреть топ доменов ваших ссылок:
cat all_links.txt | grep -ioP '://\K[^/]*' | sort | uniq -c | sort -n
Но предварительно лучше разобраться с поддоменами, чтобы были более четкие данные. Я особо не парился и писал ручками обрезку домена третьего уровня через sed:
cat all_links.txt | grep -ioP '://\K[^/]*' | sed 's/.*.userapi.com/userapi.com/g' | sed 's/.*.joyreactor.cc/joyreactor.cc/g' | sort | uniq -c | sort -n
Заключение
Я на самом деле хотел только картинки посмотреть. А потом одно посмотрел, другое посмотрел, да и затянуло. Разумеется, в обычных условия я не позволи бы себе столько времени потратить на такую чушь — не повторяйте мою ошибку :). Но, признаюсь, чтение некоторых старых переписок навеяло… воспоминания. Эмоции. Пищу для размышлений и рефлексии. Так что, может быть, эти часы копания в прошлом были потрачены не совсем зря.
UPD
 Вторым ответом техподдержка ВК признала, что есть недочеты и передала разработчикам.
Вторым ответом техподдержка ВК признала, что есть недочеты и передала разработчикам.
ВНЕЗАПНО публикациями в пабликах
как выяснилось, такое происходит не всегда, почему — не знаю. Просмотрел часть своих старых групп на 1,5 землекопа - моих постов со их стен в архиве нет.