Мои впечатления от Kotlin-JS
… или мышки плакали, кололись, но продолжали пробовать фреймворки для генерации кода для web-странички.
Зарождение идеи и MVP #
Идея ко мне пришла, когда я ждал одобрения своего пулл-реквеста в Kotlin. Заинтересовался вопросом — как долго можно будет ждать ответа, особенно с учетом большого числа открытых PR. Попробовал поискать готовое решение, но ничего не нашел.
Потом потратил примерно полчаса-час на то, чтобы накалякать скрипт на питоне, который подключался к GitHub REST API, скачивал все пулл-реквесты и считал перцентили для времени закрытия пулл-реквестов. Потом решил, что штука получилась полезная, надо сделать доступной для всех. Kotlin Multiplatform прет из всех щелей, Kotlin билдится в JavaScript уже тысячу лет, в Scala переделать JVM в JS было довольно просто — почему бы и нет? Думал, что использую кросс-платформенные библиотеки, а потом сделаю тоненькую прослойку для фронта и будет готово.

Hello world #
Выставить экспорт оказалось сложнее, чем в Scala. Во-первых, надо добавлять префикс с именем файла (github_pr_stats.someFunc вместо просто someFunc). Во-вторых, если функция лежит в каком-нибудь пакете, то писать надо будет полное имя (github_pr_stats.ru.ov7a.pull_requests.ui.someFunc). Можно использовать аннотацию @JsName("shortName"), чтобы писать… github_pr_stats.ru.ov7a.pull_requests.ui.shortName. В итоге я так и не нашел способа сделать человеческое имя для экспорта. В Scala для этого было достаточно написать @JSExportTopLevel("shortName").
Intellij иногда немного тупила и не подсвечивала нормально код, иногда ломалась навигация. Один раз вообще какая-то фигня внезапно случалась с webpack с очень понятной ошибкой
[webpack-cli] Invalid configuration object. Object has been initialized using a configuration object that does not match the API schema.
- configuration has an unknown property '_assetEmittingWrittenFiles'. These properties are valid:
object { bonjour?, client?, compress?, dev?, firewall?, headers?, historyApiFallback?, host?, hot?, http2?, https?, liveReload?, onAfterSetupMiddleware?, onBeforeSetupMiddleware?, onListening?, open?, port?, proxy?, public?, setupExitSignals?, static?, transportMode?, watchFiles? }
Помогло обновление версии Kotlin, но осадочек остался. С одной стороны, логично, что используется существующая экосистема JavaScript, но с другой — все ее проблемы едут вместе с ней. Печалит, что она не очень инкапсулирована.
Hot-reloading — прикольно, когда работает, но уныло, когда ломается. С учетом того, что для его работы требовалась перекомпиляция, которая иногда валилась с ошибкой, проще было сразу делать ребилд.
Было ожидание, что я пишу код “как обычно”, а взаимодействую с JavaScript только в отдельно выделенном загончике — слое интеграции. Однако

Например, хотел вынести шаблон строки в константу, чтобы потом вызывать String.format, но фигушки — format существует только в JVM-мире. Похожая история с регулярками: JavaScript не поддерживает матчинг-группы. Еще хотел с помощью рефлексии генерировать список необходимых полей в запросе — тоже нельзя, в JavaScript рефлексией почти ничего нельзя сделать.
Библиотеки #
Кроссплатформенные библиотеки — это правильная и хорошая идея, но чувствуется, что они в очень ранних стадиях и заточены под конкретные кейсы. Я задолбался везде проставлять аннотации @OptIn для экспериментальных фич: вроде как логично, потом проще будет выпиливать, а с другой стороны — компилятор-то на что? Поменяется API в новой версии — пусть не компилируется, а если компилируется — то пусть работает. Можно было бы помечать по аналогии с @Deprecated: простое предупреждение, которое можно подавить, а не обязательно помечать.
Документация Ktor клиента оставляет желать лучшего, да и по коду тяжело разобраться. Шаг в сторону от единственного правильного способа — уже хлебаешь проблем.
Например, есть DSL для составления запроса и метод HttpMessageBuilder.accept(type: ContentType). Как туда прописать что-то нестандартное? Никак, в явном виде добавить append(HttpHeaders.Accept, CUSTOM_CONTENT_TYPE). При этом сам вспомогательный метод делает ровно то же самое, и добавить в DSL аналогичный метод, принимающий строку — нет проблем. Странно что это не сделали, смесь DSL и не-DSL выглядит стремно.
Похожая ситуация с авторизацией. Для нее вообще нет DSL, можно только добавить как заголовок. Почему? Потому что создатели посчитали, что единственный верный способ прописывания авторизации в клиенте — прописать ее при создании клиента. Причем поведение по умолчанию — посылать запрос без авторизации, а если словил 401 — перепосылать с авторизациией. Даже base64 не заиспользуешь из клиента — он недоступен наружу, пришлось копипастить.
Настроить путь запроса можно примерно тремя способами: get(url), get(куча параметров, но не все), get(){куча dsl}), и каждый неудобен по-своему. Разумеется, можно еще эти способы комбинировать. Первый еще парсит URL: разбивает его на кусочки, чтобы потом собрать обратно. API для преобразования URL из строки в объект — URLBuilder().takeFrom(url).build(), короче не нашел. Опять два стула: один с неполным DSL, другой с фабриками и билдерами. В тестах еще наткнулся на проблему, что объект Url c путем /path и path — это два разных Url, хотя полная строка выглядит одинаково. Очень весело такое было дебажить.
Сериализации есть куда расти. Для каждой DTO надо явно прокидывать @Serializable, но это скорее хорошо, чем плохо.
Duration — основной поставщик @OptIn в коде. Местами не очень логичен. Например, для получения Instant с текущим временем нужно вызывать не Instant.now(), а Clock.System.now(). В целом впечатления смешанные: вроде удобно, но встречается неконсистентная логика. Joda Time все-таки качественнее будет.
Корутины #
Это мой первый проект с корутинами. Я решил набить побольше шишек, да:)
Первая грабелька, на которую наступил — двухцветные функции. И это был осознанный шаг команды разработчиков.
А столкнулся я с этим в первый раз когда написал sequence, на котором вызывался map с suspend-функцией внутри. Пришлось читать туториал про каналы и потоки (забавно, что в нем в качестве примера тоже используется работа с GitHub), чтобы выяснить, что мне подходит Flow (холодный асинронный поток данных). И ладно бы надо было поменять тупо sequence на flow везде, но нет — все работает немного по-другому. Из позитивного — понравилась функция transformWhile, которая отлично подходит для прерывания потока после получения последнего элемента. А вот генерацию потока с нуля в чисто функциональном стиле (как с generateSequence) сделать не получилось. В итоге у меня в коде так себе кусочек с мутабельной переменной и do-циклом, причем даже рекурсию там скорее всего не получится сделать. Странно, что в стандартной библиотеке нет аналога generateSequence.
Разумеется, вскрылись проблемы, связанные с JavaScript. Экспортируемую функцию нельзя сделать suspend (хотя непонятно, почему). В JavaScript нет runBlocking, что особенно больно в тестах, хотя конкретно для них есть какое-то шевеление. Вроде как это обосновывается тем, что можно иметь только один поток в JavaScript, но с другой стороны — есть же еще воркеры.
Одним из последних штрихов было добавление индикатора прогресса. Я хотел сначала попробовать разделить Flow, чтобы изолировать основную логику от логики обновления процента выполнения. Вроде как мне нужен был SharedFlow, но из официальной документации не понял, как его сделать красиво из обычного. Внезапно, самой понятной оказалась документация для Android.
Ладно, создал SharedFlow, запустил основной поток в логику вычисления, второй — в индикатор прогресса… и ничего. Было выполнено несколько запросов, но результаты никто не обработал. В консоли пусто, ошибки нет ни на стадии компиляции, ни во время исполнения. Долго с этим разбираться не стал, хотелось сделать красиво, не получилось — ну и ладно. Сделал в итоге явную передачу объекта для потребления прогресса. Позже планирую сделать MWE и завести баг. Возможно это опять из-за однопоточности JavaScript, но хотелось тогда хотя бы получать нормальную ошибку.
Интеграция с JavaScript-библиотеками #
Честно говоря, я охренел, насколько погано и неудобно работать с куками в чистом JavaScript. Решил подключить популярную библиотеку для этого, и это оказалось довольно просто. У Kotlin есть встроенная генерация типов из TypeScript-дефиниций. Жаль, что пришлось понизить версию библиотеки, потому что для нее не было актуальных дефиниций типов. Получилось вот так:
implementation(npm("js-cookie", "2.2.1"))
implementation(npm("@types/js-cookie", "2.2.7", generateExternals = true))
Видимость модуля глобальная, что немного печалит. Вляпался в отличия способов подключения модулей, пришлось явно указывать, что используется CommonJs — опять экосистема JavaScript течет через абстракции. Дальше возникла проблема с передачей аргумента в библиотечный метод: в библиотеке принимается сырой JSON-объект, а в сгенерированных определениях это был интерфейс без реализации. Попытался сделать по-честному: сделать реализацию интерфейса (получалось по-уродски, если честно). Однако получил в рантайме очень описательную ошибку:
TypeError: o[s].split is not a function
Самым простым решением оказалось пихнуть сырой JSON. Типизация это хорошо, но в данном случае она только добавляет хлопот.
Расстроило, что мало реализовано преобразований. Например, как сконвертировать сырой JSON в Map? А никак, только руками. Примерно та же история с преобразованием HTMLCollection в нормальный список — там проще, но элементы надо явно преобразовывать к HTMLElement.
Основная логика #
Inside every large program is a small program struggling to get out (Tony Hoare).
Основная логика была самой простой частью. Считать перцентили — легко, но вот обобщить — не очень. Внезапно я обнаружил себя читающим всякие статьи по поводу того, как правильно называется группа, позволяющая считать среднее. К сожалению, у Kotlin’а даже нет обобщений над Number, не говоря уже об утиной типизации или классов типов, хоть на это и есть причины. Пришлось имитировать, получилось немного страшновато.
При обработке посмотрел еще раз на Result — и это уныние, кастрированный Either, который не получится даже нормально сматчить через when, и опять возникают проблемы с “двойным nullable”. Да, есть альтернативы, и можно написать свой, но я решил доупороться и использовать все стандартное.
При работе с индикатором прогресса наткнулся на проблему, что не знаю, как посчитать количество пулл-реквестов без лишнего запроса. Пришлось перейти с REST API на GraphQL API. Сначала пробовать сделать запрос через поисковый запрос
{
search(query: "type:pr repo:jetbrains/kotlin state:closed", type: ISSUE, first: 100) {
issueCount
edges {
node{
... on PullRequest {
url
createdAt
mergedAt
state
}
}
}
}
}
но обнаружил, что количество расходится с аналогичным при REST-запросе. Зато при запросе к коллекции все совпало.
{
repository(name: "kotlin", owner: "jetbrains") {
pullRequests(first: 100) {
totalCount
nodes {
url
createdAt
mergedAt
updatedAt
closedAt
state
}
}
}
}
Уж не знаю, с чем это связано, но тратить время на исследование этой проблемы не захотелось.
Увы, GitHub GraphQL API пока не работает без авторизации. Это ставило под вопрос демо (да и работу было жаль выкидывать), поэтому я решил оставить оба клиента: для неавторизованных запросов использовать REST с приблизительной оценкой количества, а для авторизованных — GraphQL.
Кроссплатформенной библиотеки для работы с GraphQL из Kotlin я не нашел, поэтому запрос выглядит страшновато, но адекватных альтернатив я не придумал. Выяснилось, что объекты пулл-реквестов в REST API и GraphQL отличаются: в REST используется snake_case, а GraphQL — СamelCase, и немного отличался enum статуса, но это решилось тупеньким конвертером.
Классной фишкой GitHub GraphQL API оказалась скорость: запрос через него выполняется за 200-500 миллисекунд, в то время как через REST — от двух секунд. В целом работа с GraphQL оставила приятные впечатления.
Веб-морда #
Интерфейс получился довольно скучный, с рисованием у меня, увы, плохо (я же не фронтендер). Немного не очевидны были моменты с автозаполнением формы, действием при нажатии на Enter и обработкой ошибок ввода, но это все было вызвано моей неопытностью.
Для генерации использовал kotlinx.html. Не понравилось, что нужно вызывать document.create для создания элемента, и что для присвоения в innerHtml полученный объект надо преобразовывать в строку, в то время как append нормально добавляет элементы. Унарный плюс для добавления текста был довольно не очевидным моментом, причем это не вызывает ошибку компиляции — просто выводится пустое содержимое, потому что строка используется как имя класса.
Тесты #
Поддержка тестирования расстроила. Тут начало всплывать много особенностей JavaScript.
Нельзя использовать названия методов с пробелами, как это обычно делают в unit-тестах на JVM. Т.е. вместо fun `should fetch single page properly`() надо писать fun should_fetch_single_page_properly(). Вроде мелочь, но неприятно.
С корутинами была уже упомянутая проблема, что нет возможности запустить тест через runBlocking(), в итоге пришлось использовать костыль с GlobalScope.promise:
@OptIn(DelicateCoroutinesApi::class)
fun runTest(block: suspend (scope: CoroutineScope) -> Unit): dynamic = GlobalScope.promise { block(this) }
и оборачивать явно каждый тест. Вроде можно попробовать альтернативные способа запуска тестов, но, опять же, хотелось пощупать стандартные инструменты.
Тесты запускаются через фреймворк Karma в реальном браузере, причем не в каком-нибудь, а в том, который явно указан в конфиге, один из популярных на выбор. Как следствие, возникла проблема с подгрузкой ресурсов из файлов. Очень грустно, что подобное не работает из коробки. require("fs") не работает в браузере. В итоге пришлось извратиться с window.fetch и конфигурацией Karma, который надо настраивать через исполняемый js-файл в специальной папочке (sic!). Но даже с таким подходом все равно были проблемы с корутинностью — ловил стремную ошибку:
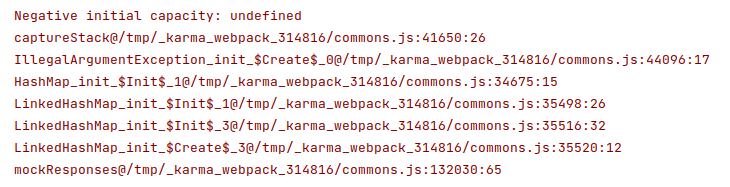 А все потому, что надо было выполнять операции в корутине. Но корутины в JavaScript нельзя вызвать с блокированием, поэтому в итоге получился синхронный запрос через XMLHttpRequest:
А все потому, что надо было выполнять операции в корутине. Но корутины в JavaScript нельзя вызвать с блокированием, поэтому в итоге получился синхронный запрос через XMLHttpRequest:
fun loadResource(resource: String): String {
XMLHttpRequest().apply {
open("GET", "/base/$resource", async = false)
send()
return responseText
}
}
Запускаются все тесты скопом, даже если указал один метод или один класс. Позже понял, что проблема с пакетами, и если заменить в настройках теста полное имя на обычное, то прогоняется ровно 1 тест, но тогда отваливается интеграция с Intellij :( С другой стороны, она оставляет желать лучшего: дебажить через нее у меня так и не получилось. Такое подозрение, что класть код в пакеты не очень почетно, потому что нельзя иметь тесты с одинаковым именем класса, даже если они в разных пакетах. Запуск при этом ругается на то, что не может загрузить временную папку :/
С точки зрения ассертов Kotest работает просто замечательно, не зря я его выбрал победителем среди прочих библиотек.
Методы для тестирования Ktor клиента оставляют желать лучшего. Тестирование запросов через мок — классно, но тогда надо прокидывать явно MockEngine, который теперь не получить автоматически для платформы. Более того, MockEngine конфигурируется только один раз и удобно можно только задать последовательность ответов, поэтому пришлось навертеть фабричных лямбд. Конечно, MockEngine можно сделать глобальным, и переиспользовать, меняя мутабельный конфиг, но изначально он должен быть непустым. Опять DSL создает ограничения, а не помогает. Вообще API не очень человечное: например, если надо матчить запрос (что он с правильными параметрами идет) — пиши обертку. Какой-нибудь HttpRequestData содержит executionContext от корутин — офигенно конечно матчить то, что по факту в дата-класс можно превратить. Были проблемы и с обычными методами. Помимо упомянутой проблемы с парсингом URL, которую очень весело было искать без дебага, метод toString() у объекта ответа выводит только первые несколько символов у содержимого — спасибо, теперь надо писать колбасу
(request.body as TextContent).bytes().decodeToString()
для отладки. Функция для получения содержимого в байтовом представлении — асинхронная, поэтому ее не используешь просто так.
Заключение #
Я не настоящий сварщик, поэтому некоторые проблемы, с которыми я столкнулся, могут показаться детскими для матерых фронтендеров. С другой стороны, кажется, я как раз попадаю в одну из целевых ниш Kotlin-JS: человек, который плохо знаком с JavaScript, которому нужно написать что-нибудь на нем, желательно типобезопасно.
На мой взгляд, идея неплохая, но реализация немного подкачала. Считаю, что для прода Kotlin-JS не очень готов, особенно если учитывать, как больно его тестировать. Ожидал, что инкапсуляция будет получше и что особенности JavaScript не будут везде торчать.

Поиграться с результатом можно тут, а почитать код — на GitHub.
В будущем планирую сделать красивый индикатор загрузки (потому что <progress> HTML5 не позволяет универсально отобразить проценты), поковыряться с SharedFlow, и попробовать Kotlin MultiPlatform — портировать проект на Native.