SmartRhino 2019
Функциональное программирование часто воспринимают как что-то странное и непонятное, хотя на самом деле ничего сверхсложного в нем нет. В докладе будет краткий обзор полезных “фишек” функциональной парадигмы и будет рассказано, что они дают на практике.
UPD: Оригинал был удален из-за удаления канала.
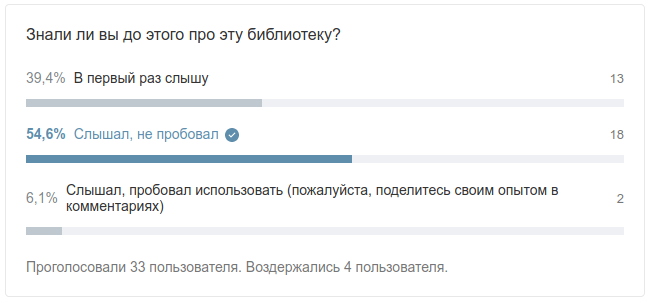
Читаете ли вы Scaladoc для «очевидных» методов коллекций? Или почему лениться не всегда хорошо
Если вы не знаете, чем отличаются
someMap.map{ case (k, v) => k -> foo(v)}
и
someMap.mapValues(foo)
кроме синтаксиса или сомневаетесь/не знаете, к каким плохим последствиям это отличие может привести и причем тут identity, то это статья для вас.
В противном случае - поучаствуйте в опросе, расположенном в конце статьи.
Начнем с простого
Попробуем втупую взять пример, расположенный до ката и посмотреть, что получится:
val someMap = Map("key1" -> "value1", "key2" -> "value2")
def foo(value: String): String = value + "_changed"
val resultMap = someMap.map{case (k,v) => k -> foo(v)}
val resultMapValues = someMap.mapValues(foo)
println(s"resultMap: $resultMap")
println(s"resultMapValues: $resultMapValues")
println(s"equality: ${resultMap == resultMapValues}")
Этот код вполне ожидаемо выведет
resultMap: Map(key1 -> value1_changed, key2 -> value2_changed)
resultMapValues: Map(key1 -> value1_changed, key2 -> value2_changed)
equality: true
И примерно на таком уровне откладывается понимание метода mapValues на ранних стадиях изучения Scala: ну да, есть такой метод, удобно изменять значения в Map, когда ключи не меняются. И правда, чего тут еще думать? По названию метода все очевидно, поведение понятно.
Примеры посложнее
Давайте немного модифицируем наш пример (я буду явно писать типы, чтобы вы не думали, что тут какой-то мухлеж с имплиситами):
case class ValueHolder(value: String)
val someMap: Map[String, String] = Map("key1" -> "value1", "key2" -> "value2")
def foo(value: String): ValueHolder = ValueHolder(value)
val resultMap: Map[String, ValueHolder] = someMap.map{case (k,v) => k -> foo(v)}
val resultMapValues: Map[String, ValueHolder] = someMap.mapValues(foo)
println(s"resultMap: $resultMap")
println(s"resultMapValues: $resultMapValues")
println(s"equality: ${resultMap == resultMapValues}")
И такой код после запуска выдаст
resultMap: Map(key1 -> ValueHolder(value1), key2 -> ValueHolder(value2))
resultMapValues: Map(key1 -> ValueHolder(value1), key2 -> ValueHolder(value2))
equality: true
Вполне логично и очевидно. “Чувак, пора бы уже переходить к сути статьи!” - скажет читатель. Давайте сделаем создание нашего класса зависимым от внешних условий и добавим пару простых проверок на идиотизм:
case class ValueHolder(value: String, seed: Int)
def foo(value: String): ValueHolder = ValueHolder(value, Random.nextInt())
...
println(s"simple assert for resultMap: ${resultMap.head == resultMap.head}")
println(s"simple assert for resultMapValues: ${resultMapValues.head == resultMapValues.head}")
На выходе мы получим:
resultMap: Map(key1 -> ValueHolder(value1,1189482436), key2 -> ValueHolder(value2,-702760039))
resultMapValues: Map(key1 -> ValueHolder(value1,-1354493526), key2 -> ValueHolder(value2,-379389312))
equality: false
simple assert for resultMap: true
simple assert for resultMapValues: false
Вполне логично, что результаты теперь не равны, рандом же. Однако постойте, почему второй ассерт дал false? Неужели значения в resultMapValues изменились, мы же с ними ничего не делали? Давайте проверим, все ли там внутри также, как было:
println(s"resultMapValues: $resultMapValues")
println(s"resultMapValues: $resultMapValues")
И на выходе получаем:
resultMapValues: Map(key1 -> ValueHolder(value1,1771067356), key2 -> ValueHolder(value2,2034115276))
resultMapValues: Map(key1 -> ValueHolder(value1,-625731649), key2 -> ValueHolder(value2,-1815306407))

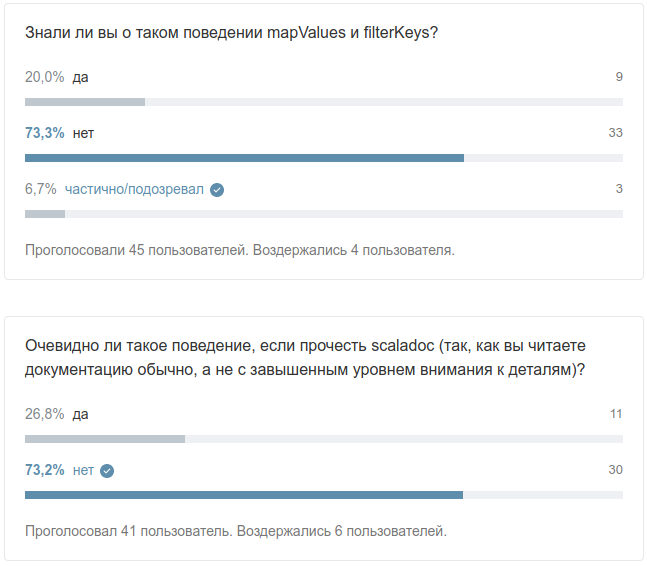
Почему это произошло?
Почему println меняет значение Map?
Пора бы уже и залезть в документацию к методу mapValues:
/** Transforms this map by applying a function to every retrieved value.
* @param f the function used to transform values of this map.
* @return a map view which maps every key of this map
* to `f(this(key))`. The resulting map wraps the original map without copying any elements.
*/
Первая строчка говорит нам то, что мы и думали - изменяет Map, применяя к каждому значению переданную в аргументах функцию. Но если прочесть очень внимательно и до конца, то выяснится, что возвращается не Map, а “map view” (представление). Причем это не нормальное представление (View), которое вы можете получить с помощью метода view и у которого есть метод force для явного вычисления. А особый класс (код из Scala версии 2.12.7, но для 2.11 там практически то же самое):
protected class MappedValues[W](f: V => W) extends AbstractMap[K, W] with DefaultMap[K, W] {
override def foreach[U](g: ((K, W)) => U): Unit = for ((k, v) <- self) g((k, f(v)))
def iterator = for ((k, v) <- self.iterator) yield (k, f(v))
override def size = self.size
override def contains(key: K) = self.contains(key)
def get(key: K) = self.get(key).map(f)
}
Если вы вчитаетесь в этот код, то увидите, что ничего не кэшируется, и при каждом обращении к значениям они будут высчитываться заново. Что мы и наблюдаем в нашем примере.
Если вы работаете с чистыми функциями и у вас все иммутабельно - то вы не заметите никакой разницы. Ну, может, производительность просядет. Но, к сожалению, не все в нашем мире чисто и идеально, и используя эти методы, можно наступить на грабли (что и случилось в одном из наших проектов, иначе бы не было этой статьи).
Разумеется, мы не первые, кто столкнулся с этим. Аж в 2011 году был открыт мажорный баг по этому поводу (и на момент написания статьи он помечен как открытый). Там еще упоминается метод filterKeys, у которого точно такие же проблемы, потому что он реализован по такому же принципу.
Кроме того, c 2015 года висит тикет на добавление инспекции в IntelliJ Idea.
Что делать?
Самое простое решение - тупо не использовать эти методы, т.к. по названию их поведение, на мой взгляд, весьма неочевидно.
Вариант чуть получше - вызвать map(identity).
identity, если кто не знает - это функция из стандартной библиотеки, которая просто возвращает свой входной аргумент. В данном случае основную работу делает метод map, который явно создает нормальный Map. Проверим на всякий случай:
val resultMapValues: Map[String, ValueHolder] = someMap.mapValues(foo).map(identity)
println(s"resultMapValues: $resultMapValues")
println(s"simple assert for resultMapValues: ${resultMapValues.head == resultMapValues.head}")
println(s"resultMapValues: $resultMapValues")
println(s"resultMapValues: $resultMapValues")
На выходе получим
resultMapValues: Map(key1 -> ValueHolder(value1,333546604), key2 -> ValueHolder(value2,228749608))
simple assert for resultMapValues: true
resultMapValues: Map(key1 -> ValueHolder(value1,333546604), key2 -> ValueHolder(value2,228749608))
resultMapValues: Map(key1 -> ValueHolder(value1,333546604), key2 -> ValueHolder(value2,228749608))
Все хорошо :)
Если вам все-таки хочется оставить ленивость, то лучше изменить код так, чтобы она была очевидна. Можно сделать implicit class с методом-оберткой для mapValues и filterKeys, который дает новое, понятное для них имя. Либо использовать явно .view и работать с итератором пар.
Кроме того, стоит добавить инспекцию в среду разработки/правило в статический анализатор/куда-нибудь еще, которое предупреждает об использовании этих методов. Потому что лучше потратить немного времени на это сейчас, чем наступить на грабли и долго разгребать последствия потом.
Как вы еще можете наступить на грабли и как наступили на них мы
Кроме случая с зависимостью от внешних условий, который мы наблюдали в примерах выше, есть и другие варианты.
Например, изменяемое значение (заметьте, тут на поверхностный взгляд все “иммутабельно”):
val someMap1 = Map("key1" -> new AtomicInteger(0), "key2" -> new AtomicInteger(0))
val someMap2 = Map("key1" -> new AtomicInteger(0), "key2" -> new AtomicInteger(0))
def increment(value: AtomicInteger): Int = value.incrementAndGet()
val resultMap: Map[String, Int] = someMap1.map { case (k, v) => k -> increment(v) }
val resultMapValues: Map[String, Int] = someMap2.mapValues(increment)
println(s"resultMap (1): $resultMap")
println(s"resultMapValues (1): $resultMapValues")
println(s"resultMap (2): $resultMap")
println(s"resultMapValues (2): $resultMapValues")
Этот код выдаст такой результат:
resultMap (1): Map(key1 -> 1, key2 -> 1)
resultMapValues (1): Map(key1 -> 1, key2 -> 1)
resultMap (2): Map(key1 -> 1, key2 -> 1)
resultMapValues (2): Map(key1 -> 2, key2 -> 2)
При повторном обращении к someMap2 получили веселый результат.
К проблемам, которые могут возникнуть при необдуманном использовании mapValues и filterKeys можно добавить снижение производительности, повышение расхода памяти и/или повышение нагрузки на GC, но это уже больше зависит от конкретных случаев и может быть не так критично.
В копилку похожих граблей стоит также добавить метод toSeq у итератора, который возвращает ленивый Stream.
Мы на грабли с mapValues наступили случайно. Он использовался в методе, который с помощью рефлексии создавал набор обработчиков из конфига: ключами были идентификаторы обработчиков, а значением - их настройки, которые потом преобразовывались в сами обработчики (создавался инстанс класса). Поскольку обработчики состояли только из чистых функций, все работало без проблем, даже на производительности заметно не сказывалось (уже после наступания на грабли сделали замеры).
Но как-то раз пришлось сделать в одном из обработчиков семафор для того, чтобы только один обработчик выполнял тяжелую функцию, результат которой кешируется и используется другими обработчиками. И тут на тестовой среде начались проблемы - валидный код, который нормально работал локально, начал валиться из-за проблем с семафором. Разумеется, первая мысль при неработоспособности новой функциональности - это то, что проблемы связаны с ней самой. Долго ковырялись с этим, пока не пришли к выводу “какая-то дичь, почему разные инстансы обработчиков используются?” и только по стектрейсу обнаружили, что подгадил нам оказывается mapValues.
Если вы работаете с Apache Spark, то на похожую проблему можно наткнуться, когда внезапно обнаружится, что для какого-то элементарного кусочка кода с .mapValues можно словить
java.io.NotSerializableException: scala.collection.immutable.MapLike$$anon$2
https://stackoverflow.com/questions/32900862/map-can-not-be-serializable-in-scala
https://issues.scala-lang.org/browse/SI-7005
Но map(identity) решает проблему, а глубже копать обычно нет мотивации/времени.
Заключение
Ошибки могут таиться в самых неожиданных местах - даже в тех методах, которые кажутся на 100% очевидными. Конкретно эта проблема, на мой взгляд, связана с плохим названием метода и недостаточно строгим типом возврата.
Конечно, важно изучать документацию на все используемые методы стандартной библиотеки, но не всегда она очевидна и, если говорить откровенно, не всегда хватает мотивации читать про “очевидные вещи”.
Сами по себе ленивые вычисления - клевая шутка, и статья ни в коем случае не призывает от них отказаться. Однако когда ленивость неочевидна - это может привести к проблемам.
Справедливости ради, проблема с mapValues уже фигурировала на Хабре в переводе, но лично у меня та статья очень плохо отложилась в голове, т.к. там было много уже известных/базовых вещей и не до конца было ясно, чем может быть опасно использование этих функций:
Метод filterKeys обертывает исходную таблицу без копирования каких-либо элементов. В этом нет ничего плохого, однако вы вряд ли ожидаете от filterKeys подобного поведения
То есть ремарка про неожиданное поведение есть, а что при этом можно еще и на грабли немного наступить, видимо, считается маловероятным.
→ Весь код из статьи есть в этом gist
Скрин опроса:
Автоматизация загрузки логов из Kibana в Redmine
Типичный юзкейс для Kibana - смотрим логи, видим ошибки, создаем тикеты по ним. Логов у нас довольно много, места для их хранения мало. Поэтому просто вставить ссылку на документ из Elasticsearch/Kibana недостаточно, особенно для низкоприоритетных задач: пока доберемся до нее, индекс с логом может быть уже удален. Соответственно, приходится документ сохранять в файл и прикреплять к тикету.
Если один раз это делать, то это еще куда ни шло, но создавать уже десять тикетов подряд будет тупо лень, поэтому я решил это “быстренько” (ха-ха) автоматизировать.

Под катом: статья для пятницы, экспериментальная фича javascript, пара грязных хаков, небольшая регулярка с галочками, reverse proxy, проигрыш безопасности удобству, костыли и очевидная картинка из xkcd.
Варианты решения
Сходу можно придумать достаточно много решений проблемы. Во-первых, можно пихать сразу все логи в RM (внезапно, для этого даже есть плагин logstash), предварительно их фильтруя/агрегируя - знай себе меняй описание да исполнителя. Это, конечно, прикольно, но надо будет долго отлаживать/настраивать и появится много новой рутинной работы - давать описания/удалять лишнее.Второй вариант - намастрячить какой-нибудь скрипт, который получает ссылки на логи, скачивает их, спрашивает дополнительные параметры у пользователя и через API Redmine создает новый тикет. Но к этому надо будет нормальный интерфейс пилить, да и дублировать часть функций RM…
Можно извратиться и сделать кликер или с помощью selenium подготовить тикет, чтобы потом в привычном интерфейсе дозаполнить что надо, но нельзя будет трогать мышку… Да и редактирование может вдруг понадобиться.
Плагин для браузера? Окститесь, его еще регистрировать и поддерживать, да еще хотя бы под два браузера делать.
Плагин Redmine? Не, это ж API надо будет изучать, да и лезть в кишки RM… Простого дополнительного поля недостаточно будет.
В итоге приходим к букмарклету (выполнению javascript из закладок) и/или пользовательскому скрипту (greasemonkey/tampermonkey и т.п.) - javascript‘ом вроде можно и интерфейс нарисовать, и логи скачать через ajax-запрос, да и вообще почти все что угодно со страницей сделать.
Загрузка файлов
Пока самая неясная часть - это загрузка файлов. Все остальное вроде можно легко сделать… За загрузку файлов на странице создания тикета RM отвечает обычный<input type="file">, при изменении которого вызывается функция addInputFiles(this).
По идее, надо всего лишь изменить список файлов у этого элемента и дернуть этот метод. Есть только одна мааааленькая проблема:

Сделано это ради того, чтобы нельзя было отправить на сервер
/etc/passwd, /etc/shadow/ или фото вашего кота с рабочего стола. В принципе, разумно, но надо это как-то обойти. Впрочем, если нельзя, но очень хочется, то можно заиспользовать такой грязный хак, который основан экспериментальной фиче - Clipboard API.
function createFileList(files){
const dt = new ClipboardEvent("").clipboardData || new DataTransfer();
for (let file of files) {
dt.items.add(file);
}
return dt.files;
}
Т.е. тут имитируется добавление файлов из буфера обмена, которые мы потом получаем списком. Сам по себе “файл” из текста создается элементарно:
function createFile(text, fileName){
let blob = new Blob([text], {type: 'text/plain'});
let file = new File([blob], fileName);
return file;
}
Пользовательский интерфейс
Тут все просто, как топор: делаем в нужном месте надпись, поле ввода и кнопку загрузки. Поскольку делается "для своих" с форматом ввода (и его валидацией) особо не стал заморачиваться - пусть будет текстовое поле, одна строка - один лог (ссылка и имя создаваемого файла через пробел).Для букмарклета еще пригодилось предварительное удаление себя по id.
Элементарные вещи
function removeSelf(){
let old = document.getElementById(ui_id);
if (old != null) old.remove();
}
function createUi(){
removeSelf();
let ui = document.createElement('p');
ui.id = ui_id;
let label = document.createElement('label');
label.innerHTML = "Logs data:";
ui.appendChild(label);
let textarea = document.createElement('textarea');
textarea.id = data_id;
textarea.cols = 60;
textarea.rows = 10;
textarea.name = "issue[logs_data]";
ui.appendChild(textarea);
let button = document.createElement('button');
button.type = "button";
button.onclick = addLogsData;
button.innerHTML = "Add logs data";
ui.appendChild(button);
let attributesBlock = document.querySelector("#attributes");
attributesBlock.parentNode.insertBefore(ui, attributesBlock);
}
Основная работа
Здесь тоже все просто: разбиваем текст из поля ввода на пары "ссылка"-"имя файла", скачиваем все из эластика, потому что Kibana так просто данные не отдаст, заливаем на RM, изменяем описание тикета и все. Благо к RM уже подключен jquery и ajax-запросы легко создаются.Скучный код, регулярку искать здесь
function addLogsData(){
let text = document.getElementById(data_id).value;
let lines = text.split('\n');
let urlsAndNames = lines
.filter(x => x.length > 2)
.map(line => line.split(/\s+/, 2));
downloadUrlsToFiles(urlsAndNames);
}
const kibana_pattern = /http:\/\/([^:]*):\d+\/app\/kibana#\/doc\/[^\/]*\/([^\/]*)\/([^\/]*)\/?\?id=(.*?)(&.*)?$/;
const es_pattern = 'http://$1:9200/$2/$3/$4';
function downloadUrlsToFiles(urlsAndNames){
let requests = urlsAndNames.map((splitted) => {
let url = splitted[0].replace(kibana_pattern, es_pattern);
return $.ajax({
url: url,
dataType: 'json'
});
});
$.when(...requests).done(function(...responses){
let files = responses.map((responseRaw, index) => {
let response = responseRaw[0];
checkError(response);
let fileName = urlsAndNames[index][1];
return createFile(JSON.stringify(response._source), fileName + '.json');
});
uploadFiles(files, urlsAndNames);
}).fail((error) => {
let errorString = JSON.stringify(error);
alert(errorString);
throw errorString;
});
}
function uploadFiles(files, urlsAndNames){
pseudoUpload(files);
changeDescription(urlsAndNames);
removeSelf();
}
Отлично, все готово! Делаем тестовый запуск и…

Безопасность
Для тех кто не в курсе, запрашивать http-данные, находясь на https ресурсе, - очень плохо, потому что вам могут подпихнуть левые данные через MITM атаку. Более того, какой-нибудь Firefox даже если вам и разрешит это сделать, просить у него разрешение надо будет каждый раз - и белого списка никогда не будет. Это все правильно и хорошо с точки зрения пользователя, но для скрипта на коленке это только палки в колеса.Что ж, покупать X-Pack для Elasticsearch ради вшивого скрипта не хочется, поэтому придется сделать прокси https -> http. Он же reverse proxy. Вариантов тут достаточно много, от монструозного squid до питонячего скрипта. Самым подходящим мне показался haproxy - он и прост в настройке/установке, и ресурсы не жрет.
Достаточно лишь сгенерить самоподписанный сертификат (прости, let‘s encrypt, но мы в траст-зоне)
openssl genrsa -out dummy.key 1024
openssl req -new -key dummy.key -out dummy.csr
openssl x509 -req -days 3650 -in dummy.csr -signkey dummy.key -out dummy.crt
cat dummy.crt dummy.key > dummy.pem
и, собственно, настроить haproxy:
frontend https-in
mode tcp
bind *:9243 ssl crt /etc/ssl/localcerts/dummy.pem alpn http/1.1
http-response set-header Strict-Transport-Security "max-age=16000000; includeSubDomains; preload;"
default_backend nodes-http
backend nodes-http
server node1 localhost:9200 check
Теперь на порту 9243 будет прозрачная прокси до эластика (соответственно, меняем порт в регулярке и добавляем https).
Однако и это не удовлетворит наш браузер, который печется о безопасности пользователя. На этот раз проблема в том, что нельзя запрашивать данные с другого домена, если он это не разрешил. Решается это с помощью механизма CORS. Хорошо хоть, что Elasticsearch это сам умеет:
http.cors.allow-headers: X-Requested-With, Content-Type, Content-Length
http.cors.allow-origin: "/.*/"
http.cors.enabled: true
Userscript
Напомню, что мы все еще// ==UserScript==
// @name KIBANA_LOGS
// @grant none
// @include https://<rm-address>/*issues*
// ==/UserScript==
(function(){document.body.appendChild(document.createElement('script')).src='https://<kibana-address>:4443/kibana_logs_rm.js';})();
Зато и в букмарклетах у параноиков будет обновляться. Для раздачи этой фигни нам понадобится https-сервер. Тут я уже откровенно заленился и взял первый попавшийся (да еще и на python 2.7) *посыпаю голову пеплом*:
import BaseHTTPServer, SimpleHTTPServer
import ssl
httpd = BaseHTTPServer.HTTPServer(('0.0.0.0', 4443),
SimpleHTTPServer.SimpleHTTPRequestHandler)
httpd.socket = ssl.wrap_socket(httpd.socket, certfile='/etc/ssl/localcerts/dummy.pem',
server_side=True)
httpd.serve_forever()
Вот теперь пользователям осталось только создать юзерскрипт/букмарклет, добавить в исключения сертификат и все будет работать.
Пара багов
Суть первой проблемы заключается в следующем: когда нужно обработать результаты сразу нескольких ajax-запросов, в функцию передается столько аргументов, сколько было запросов. Но когда запрос один, jquery "любезно" его раскрывает в три аргумента. Поэтому пришлось писать такой костыль:let responses;
if (requests.length == 1){
responses = [arguments];
} else {
responses = Array.from(arguments);
}
Второй баг связан с тем, что при смене трекера или при смене статуса заявки Redmine сохраняет все введенные данные, запрашивает новый интерфейс (прямо html cо встроенным js), пересоздает интерфейс и перезаполняет поля с помощью функции replaceIssueFormWith. Звучит немного дико, но это сделано для реализации workflow (а там на разных стадиях поля для ввода потенциально могут отличаться). Тут тоже пришлось сделать костыль ad-hoc решение:
function installReplaceHook(){
let original = window.replaceIssueFormWith;
window.replaceIssueFormWith = function(html){
let logs_data = document.getElementById(data_id).value;
let ret = original(html);
createUi();
document.getElementById(data_id).value = logs_data;
return ret;
};
}
Т.е. просто делаем хук на оригинальную функцию и делаем аналогичные ей действия для своего поля.
Заключение
Полную версию скрипта можно посмотреть в моем gist. Вот картинка, которую должно большинство ожидать к концу этой статьи:
А вообще автоматизировать вещи - весело и полезно, и позволяет изучить что-то новое в другой области. Пользователи скрипта довольны, создание тикетов по логам в кибане теперь не так сильно напрягает.
SmartRhino 2018
Первый доклад на конференции. За речь свою немного стыдно, но хотя бы за контент не стыдно.
Как писать чистый и понятный код, который будет легко поддерживать? По этому поводу можно найти много рекомендаций, зачастую противоречащих друг другу. Лекция поможет сориентироваться в этом ворохе советов. Будут рассмотрены наиболее распространенные ошибки в “студенческом” коде и продемонстрировано на примере, к каким негативным последствиям они могут привести.
UPD: Оригинал был удален из-за удаления канала.
Опыт использования библиотеки Puniverse Quasar для акторов
С появлением котлиновских корутин и маячащим релизом project loom эта статья потеряла свою актуальность
В прошедшем, 2017 году, был небольшой проект, который почти идеально ложился на идеологию акторов, решили поэкспериментировать и попробовать использовать их реализацию от Parallel Universe. От самих акторов особо много не требовалось - знай себе храни состояние да общайся с другими, иногда изменяйся по таймеру и не падай.
Библиотека вроде достаточно зрелая, почти 3 тысячи звезд на гитхабе, больше 300 форков, пара рекомендаций на Хабре… Почему бы и нет? Наш проект стартовал в феврале 2017, писали на Kotlin.
 Казалось бы, что могло пойти не так?
Казалось бы, что могло пойти не так?
Вкратце о библиотеке
→ Разработчик→ Документация
→ GitHub
Основное предназначение библиотеки - легковесные потоки (fibers), уже поверх которых реализованы Go-подобные каналы, Erlang-подобные акторы, всякие реактивные плюшки и другие подобные вещи “для асинхронного программирования на Java и Kotlin”. Разрабатывается с 2013 года.
Настройка сборки
Т.к. проект на котлине, сборка будет на gradle. Важный момент: для работы легковесных потоков необходимы манипуляции с Java байт-кодом (instrumentation), которые обычно делают с помощью java-агента. Этого агента quasar любезно предоставляет. На практике это означает, что:
Для начала нам понадобится добавить конфигурацию quasar:
configurations {
quasar
}
Подключим зависимости:
dependencies {
compile("org.jetbrains.kotlin:kotlin-stdlib-jre8:$kotlin_version") // котлин
compile("co.paralleluniverse:quasar-core:$quasar_version:jdk8") // основные функции quasar
compile("co.paralleluniverse:quasar-actors:$quasar_version") // акторы
compile("co.paralleluniverse:quasar-kotlin:$quasar_version") // обертки для котлина
quasar "co.paralleluniverse:quasar-core:$quasar_version:jdk8" // для java-агента
//... и другие
}
Говорим, что все gradle-таски надо запускать с java-агентом:
tasks.withType(JavaForkOptions) {
//uncomment if there are problems with fibers
//systemProperty 'co.paralleluniverse.fibers.verifyInstrumentation', 'true'
jvmArgs "-javaagent:${(++configurations.quasar.iterator())}"
}
Cвойство co.paralleluniverse.fibers.verifyInstrumentation отвечает за проверку в рантайме корректности манипуляций с байт-кодом. Разумеется, если эта проверка включена, то все начинает тормозить:)
Для релиза написал еще функцию для генерации bat/sh файлов, которые запускают приложение с java-агентом. Ничего особо интересного, просто создать файлик и прописать туда нужную строку запуска, с нужной версией quasar‘a:
def createRunScript(String scriptPath, String type) {
def file = new File(scriptPath)
file.createNewFile()
file.setExecutable(true)
def preamble = "@echo off"
if (type == "sh") {
preamble = "#!/bin/bash"
}
def deps = configurations.quasar.files.collect { "-Xbootclasspath/a:\"libs/${it.name}\"" }.join(" ")
def flags = "-Dco.paralleluniverse.fibers.detectRunawayFibers=false"
def quasarAgent = configurations.quasar.files.find { it.name.contains("quasar-core") }.name
file.text = """$preamble
java -classpath "./*.jar" -javaagent:"libs/$quasarAgent" $deps $flags -jar ${project.name}.jar
"""
}
И таск release, который создает отдельную папку со всем необходимым:
task release(dependsOn: ['build']) {
group = "Build"
def targetDir = "$buildDir/release"
doLast {
copy {
from "$buildDir/libs/${project.name}.jar"
into targetDir
}
copy { //копируем все библиотеки quasar, чтобы javaagent мог их подцепить
from(configurations.quasar.files)
into "$targetDir/libs"
}
copy { // конфиг по умолчанию, раз уж релиз делаем все равно
from("src/main/resources/application.yml")
into targetDir
}
//скрипты для запуска
createRunScript("$targetDir/${project.name}.bat", "bat")
createRunScript("$targetDir/${project.name}.sh", "sh")
}
}
Посмотреть подробнее пример можно в моем gist или в официальном примере для gradle. Теоретически, вроде как существует возможность изменить байт-код на стадии компиляции и не использовать java-агент. Для этого в quasar есть ant-таск. Однако даже с вагоном костылей и изоленты настроить его у меня не удалось.
Использование акторов
Перейдем собственно к акторам. В моем понимании основа акторов - это постоянный обмен сообщениями. Однако из коробки Quasar представляет только универсальныйco.paralleluniverse.kotlin.Actor с методом receive. Для постоянного обмена пришлось реализовать небольшую прослойку:
abstract class BasicActor : Actor() {
@Suspendable
abstract fun onReceive(message: Any): Any?
@Suspendable
override fun doRun() {
while (true) {
receive { onReceive(it!!) }
}
}
fun <T> reply(incomingMessage: RequestMessage<T>, result: T) {
RequestReplyHelper.reply(incomingMessage, result)
}
}
Которая по сути только делает вечный цикл приема сообщений.
Кроме того, с переходом на Kotlin 1.1 у библиотеки начались проблемы, которые не решены до сих пор (привожу кусок их кода):
// TODO Was "(Any) -> Any?" but in 1.1 the compiler would call the base Java method and not even complain about ambiguity! Investigate and possibly report
inline protected fun receive(proc: (Any?) -> Any?) {
receive(-1, null, proc)
}
Из-за этого в нашем BasicActor пришлось сделать обертку для receive. Ну и для понятности был сделан метод reply и extenstion-метод ask:
@Suspendable
fun <T> ActorRef<Any>.ask(message: RequestMessage<T>): T {
return RequestReplyHelper.call(this, message)
}
Обратите внимание, чтобы послать сообщение-вопрос, оно обязательно должно быть унаследовано от RequestMessage. Это немного ограничивает сообщения, которыми можно обмениваться в формате вопрос-ответ.
Очень важна аннотация @Suspendable - при использовании quasar ее надо вешать на все методы, которые обращаются к другим акторам или легковесным потокам, иначе получите в рантайме исключение SuspendExecution, и толку от “легковесности” не будет. С точки зрения разработчиков библиотеки - очевидно, что это нужно для java-агента, но с точки зрения программиста-пользователя - это неудобно (существует возможность сделать это автоматически, но будет это далеко не бесплатно).
Дальше, реализация актора сводится к переопределению метода onReceive, что достаточно просто можно сделать с помощью when, делая что-то в зависимости от типа сообщения:
override fun onReceive(message: Any) = when (message) {
is SomeMessage -> {
// Do stuff
val someotherActor = ActorRegistry.getActor("other actor")
someotherActor.send(replyOrSomeCommand)
}
is SomeOtherMessage -> {
process(message.parameter) // работает smart-cast
val replyFromGuru = guruActor.ask(Question("Does 42 equals 7*6?"))
doSomething()
}
else -> throw UnknownMessageTypeException(message)
}
Для того, чтобы получить ссылку на актор, надо обратиться к статическому методу ActorRegistry.getActor, который по строковому идентификатору вернет ссылку на актор.
Осталось только акторы запустить. Для этого надо актор сначала создать, потом зарегистрировать, и наконец запустить:
val myActor = MySuperDuperActor()
val actorRef = spawn(register(MY_ACTOR_ID, myActor))<
(Почему нельзя было сразу это одним методом сделать - неясно).
Некоторые проблемы
Как вы думаете, что произойдет, если актор упадет с исключением?А ничего. Ну упал актор. Теперь он сообщения принимать не будет, ну и что. Великолепное поведение по умолчанию!
В связи с этим пришлось реализовать актор-наблюдатель, который следит за состоянием акторов и роняет все приложение, если что-то пошло не так (к отказоустойчивости требования не предъявлялись, так что могли себе позволить):
class WatcherActor : BasicActor(), ILogging by Logging<WatcherActor>() {
override fun handleLifecycleMessage(lcm: LifecycleMessage): Any? {
return onReceive(lcm)
}
override fun onReceive(message: Any): Any? = when (message) {
is ExitMessage -> {
log.fatal("Actor ${message.actor.name} got an unhandled exception. Terminating the app. Reason: ", message.getCause())
exit(-2)
}
else -> {
log.fatal("Got unknown message for WatcherActor: $message. Terminating the app")
exit(-1)
}
}
}
Но для этого приходится запускать акторы с привязкой к наблюдателю:
@Suspendable
fun registerAndWatch(actorId: String, actorObject: Actor<*, *>): ActorRef<*> {
val ref = spawn(register(actorId, actorObject))
watcherActor.link(ref)
return ref
}
Вообще, по впечатлениям, многие моменты были неудобны или неочевидны. Возможно, “мы просто не умеем готовить” Quasar, но после Akka некоторые моменты выглядят диковато. Например, метод для реализации запроса по типу ask от Akka, который где-то закопан в утилитах и еще требует связывать типы сообщения-вопроса и сообщения-ответа (хотя с другой стороны, это неплохая фича, которая уменьшает число потенциальных ошибок).
Еще одна серьезная проблема возникла с завершением актора. Какие стандартные методы для этого есть? Может быть destroy, unspawn или unregister? А вот и нет. Только костыли:
fun <T : Actor<Any?, Any?>> T.finish() {
this.ref().send(ExitMessage(this.ref(), null))
this.unregister()
}
Есть конечно ActorRegistry.clear(), который удаляет ВСЕ акторы, но если залезть к нему в кишочки, то можно увидеть следующее:
public static void clear() {
if (!Debug.isUnitTest())
throw new IllegalStateException("Must only be called in unit tests");
if (registry instanceof LocalActorRegistry)
((LocalActorRegistry) registry).clear();
else
throw new UnsupportedOperationException();
}
Ага, только в юнит-тестах можно вызывать. А как же они это определяют?
boolean isUnitTest = false;
StackTraceElement[] stack = Thread.currentThread().getStackTrace();
for (StackTraceElement ste : stack) {
if (ste.getClassName().startsWith("org.junit")
|| ste.getClassName().startsWith("junit.framework")
|| ste.getClassName().contains("JUnitTestClassExecuter")) {
isUnitTest = true;
break;
}
}
unitTest = isUnitTest;
Т.е. если вы вдруг используете не junit - до свидания.
Погодите-погодите, вот же метод ActorRegistry.shutdown(), он то наверняка вызвает у каждого актора закрытие! Смотрим реализацию абстрактного метода в LocalActorRegistry:
@Override
public void shutdown() {
}
Еще один момент, библиотека может таинственно падать с каким-нибудь NPE без видимых на то причин/объяснений:
https://github.com/puniverse/quasar/issues/182
Кроме того, если вы используете сторонние библиотеки, с ними могут возникнуть проблемы. Например, в одной из зависимостей у нас была библиотека, которая общалась с железом (не очень качественная), в которой был Thread.sleep(). Quasar‘у это очень не понравилось, и он плевался логами с исключениями: мол, Thread.sleep() блокирует поток и это плохо скажется на производительности (см. подробнее здесь). При этом конкретных рецептов, как это исправить (кроме как тупо отключить логирование таких ошибок системным флагом) или хотя бы “понять и простить” только для сторонних библиотек, Parallel Universe не дают.
Ну и напоследок, поддержка Kotlin оставляет желать лучшего - например проверка java-agent будет ругаться на некоторые его методы (хотя само приложение при этом может продолжать работать без видимых проблем):
https://github.com/puniverse/quasar/issues/238 https://github.com/puniverse/quasar/issues/288
В целом отлаживать работу приходилось по логам - и это было довольно грустно.
Заключение
В целом впечатления от библиотеки нейтральны. По впечатлениям, акторы в ней реализованы на уровне "демонстрации идеи" - вроде работает, но есть проблемы, которые обычно всплывают при первом боевом применении. Хотя потенциал у библиотекиНам еще “очень повезло”: внимательный читатель мог заметить, что последний релиз был в декабре 2016 (по документации) или в июле 2017 (по гитхабу). А в бложике компании последняя запись вообще в июле 2016 (с интригующим заголовком Why Writing Correct Software Is Hard). В общем, библиотека скорее мертва, чем жива, поэтому в продакшене ее лучше не использовать.
P. S. Тут еще внимательный читатель может спросить - а что же тогда Akka не использовали? В принципе, с ней никаких криминальных проблем не было (хотя по сути получалась цепочка Kotlin-Java-Scala), но т.к. проект был некритичный, решили попробовать “родное” решение.
Скрин опроса: