Зачем мне твои неизменяемые коллекции? Они же медленные
Читая эту статью почти три года спустя, понимаю, что исследование весьма поверхностное, поэтому стоит воспринимать ее скептически.
Бывает так, что когда человек начинает писать на Kotlin, Scala или %language_name%, он делает манипуляции с коллекциями так, как привык, как “удобно”, как “понятнее” или даже “как быстрее”. При этом, разумеется, используются циклы и изменяемые коллекции вместо функций высшего порядка (таких как filter, map, fold и др.) и неизменяемых коллекций.
Эта статья - попытка убедить ортодоксов, что использование “этой вашей функциональщины” не влияет существенно на производительность. В качестве примеров использованы куски кода на Java, Scala и Kotlin, а для измерения скорости был выбран фреймворк для микробенчмаркинга JMH.

Для тех, кто не в курсе, JMH (Java Microbenchmark Harness) - это сравнительно молодой фреймворк, в котором разработчики постарались учесть все нюасы JVM. Подробнее о нем можно узнать из докладов Алексея Шипилева (например, из этого). На мой взгляд, проще всего с ним познакомится на примерах, где вся необходимая информация есть в javadoc.
Самая интересная часть в написании бенчмарков заключалась в том, чтобы заставить JVM реально что-то делать. Эта умная зараза заранее знала ответ на все и выдавала ответы за мизерное время. Именно поэтому в их исходном коде фигурирует prepare, чтобы обхитрить JVM. Кстати, Java Streams с предвычисленным результатом работали на порядок медленнее других способов.
Dicslaimer: все прекрасно знают, что написать бенчмарк правильно - невозможно, но предложения по тому, как написать его менее неправильно приветствуются. Если вам кажется, что обязательно надо рассмотреть пример с X, не стесняйтесь писать в комментариях, что еще надо потестить.
Кроме того, несмотря на то, что на одном графике будут и Kotlin, и Scala, и Java, считать это сравнением скорости кода на этих языках не стоит. Как минимум, в примерах на Scala есть накладные расходы на конвертацию scala.Int⇔java.lang.Integer и используются не Java-коллекции, а свои.
Исходный код примеров можно посмотреть на гитхабе, а все результаты в CSV - здесь. В качестве размера коллекций использовались значения от 10 до 100 000. Тестировать для бОльших размеров я особо не вижу смысла - для этого есть СУБД и другие способы работы с большими объемами данных. Все графики выполнены в логарифмической шкале и показывают среднее время выполнения операции в наносекундах.
Простой map
Начнем с самых простых примеров, которые есть в почти каждой статье про элементы функционального программирования:map, filter, fold и flatMap.
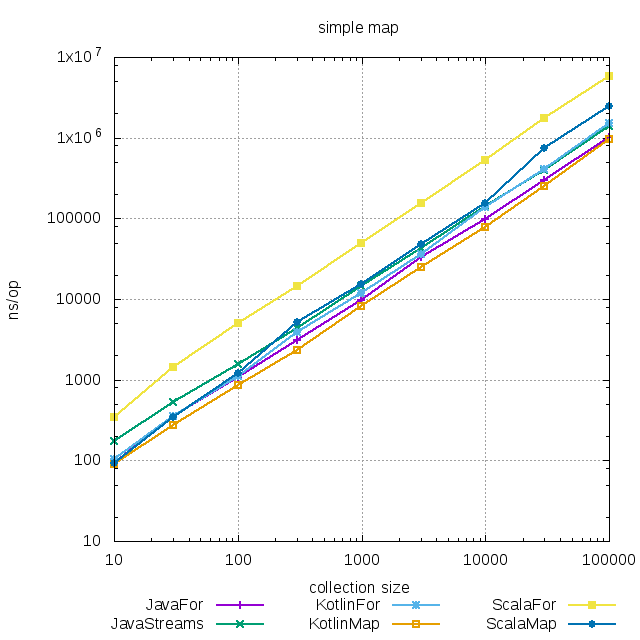 В Java циклом преобразовывать коллекции немного быстрее, чем с использованием Streams API. Очевидно, что дело в накладных расходах на преобразование в
В Java циклом преобразовывать коллекции немного быстрее, чем с использованием Streams API. Очевидно, что дело в накладных расходах на преобразование в stream, которые здесь себя не оправдывают. В Kotlin преобразование с использованием map будет быстрее, чем цикл, причем даже быстрее, чем цикл на Java. Почему же это происходит? Смотрим исходный код map:
@PublishedApi
internal fun <T> Iterable<T>.collectionSizeOrDefault(default: Int): Int =
if (this is Collection<*>) this.size else default
...
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapTo(
destination: C,
transform: (T) -> R
): C {
for (item in this)
destination.add(transform(item))
return destination
}
...
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
Получаем выигрыш за счет того, что заранее известен конечный размер коллекции. Конечно можно и в Java так сделать, но часто ли вы такое встречали?
В Scala разница между циклом и map уже ощутима. Если в Kotlin map довольно прямолинейно конвертируется в цикл, то в Scala уже не все так просто: если неявный CanBuildFrom - переиспользуемый ReusableCBFInstance из списка, то применяется хитрый while (заинтересованные могут посмотреть исходный код скаловского map для списка здесь).
Простой filter
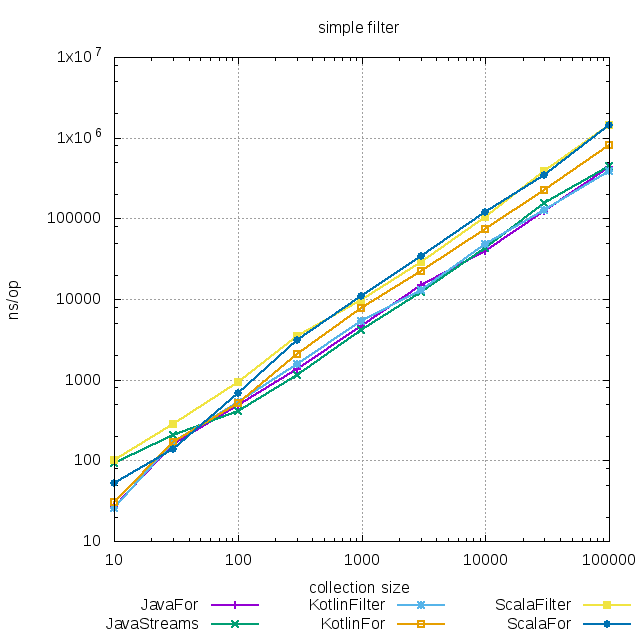 В Java для коллекций очень маленького размера Stream API немного медленнее, чем цикл, но, опять же, несущественно. Если коллекции нормального размера - разницы вообще нет.
В Java для коллекций очень маленького размера Stream API немного медленнее, чем цикл, но, опять же, несущественно. Если коллекции нормального размера - разницы вообще нет.
В Kotlin разницы практически нет (прозрачная компиляция в цикл), но при больших объемах цикл чуть медленнее.
В Scala ситуация аналогична Java: на маленьких коллекциях функциональный подход немного проигрывает, на больших - нет разницы.
Простой fold
Не совсем подходящий пример (потому что на выходе число), но все равно довольно интересный.
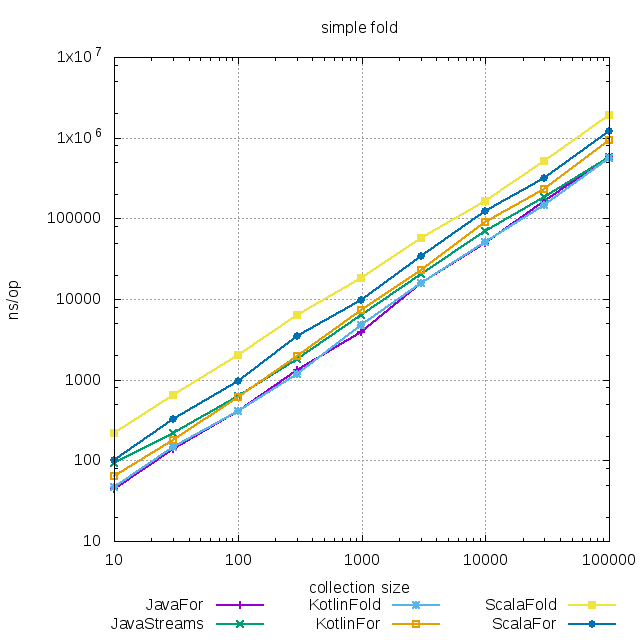 Во всех трех языках различия между итеративной формой и функциональной несущественны, хотя
Во всех трех языках различия между итеративной формой и функциональной несущественны, хотя fold в Scala работает медленнее, чем хотелось бы.
Простой flatMap
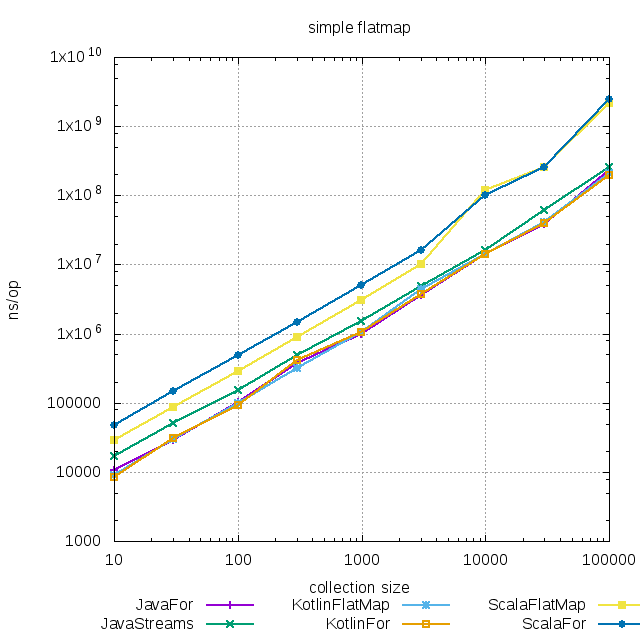 Снова разница между подходами практически неразличима.
Снова разница между подходами практически неразличима.
Цепочка преобразований
Давайте рассмотрим еще пару примеров, в которых выполняются сложные преобразования. Отмечу, что очень много задач можно решить комбинациейfilter и map и очень длинные цепочки встречаются редко.
При этом если у вас все-таки получилась длинная цепочка преобразований, то имеет смысл перейти на ленивые вычисления (т.е. применять преобразования только тогда, когда необходимо). В Kotlin это преобразование к Sequence, в Scala - iterator. Streams в Java всегда выполняются лениво.
Рассмотрим цепочку flatMap⇒filter⇒fold:
someList
.flatMap(this::generate)
.filter(this::filter)
.fold(initialValue(), this::doFold)
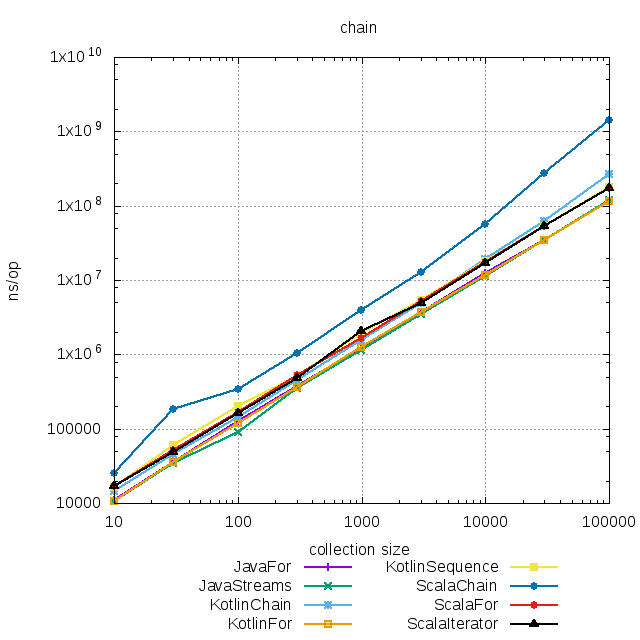 Разница по скорости между императивным подходом и функциональным снова весьма мала. Исключение составляет Scala, в которой функциональный подход медленнее цикла, но с
Разница по скорости между императивным подходом и функциональным снова весьма мала. Исключение составляет Scala, в которой функциональный подход медленнее цикла, но с iterator разница сводится к нулю.
Цепочка со вложенными преобразованиями
Рассмотрим последовательность преобразований, где элементами промежуточной коллекции тоже являются коллекции, и над которыми тоже надо выполнять действия. Например топ-10 чего-то по какой-нибудь хитрой метрике:someList
.groupBy(this::grouping)
.mapValues {
it.value
.filter(this::filter)
.map(this::transform)
.sum()
}
.entries
.sortedByDescending { it.value }
.take(10)
.map { it.key }
Честно говоря, мне такое уже тяжело было написать в императивном стиле (к хорошему быстро привыкаешь; я сделал две тупых ошибки и в одном месте перепутал переменную).
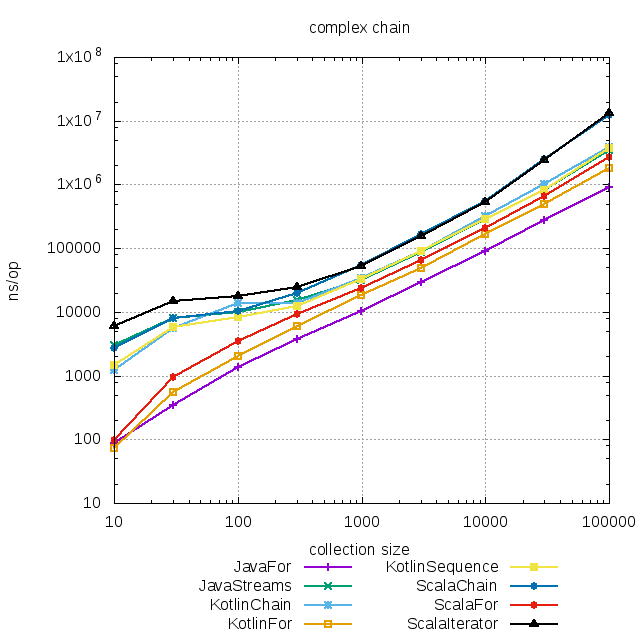 Здесь результаты уже немного интереснее. На коллекциях размером до сотни разница между итеративным и функциональным подходом стала заметна. Однако на коллекциях большего размера разницей можно уже пренебречь. Стоит ли вам экономить 10 микросекунд процессорного времени? Особенно если при этом надо поддерживать код вроде такого:
Здесь результаты уже немного интереснее. На коллекциях размером до сотни разница между итеративным и функциональным подходом стала заметна. Однако на коллекциях большего размера разницей можно уже пренебречь. Стоит ли вам экономить 10 микросекунд процессорного времени? Особенно если при этом надо поддерживать код вроде такого:
Map<Integer, Integer> sums = new HashMap<>();
for (Integer element : someList) {
Integer key = grouping(element);
if (filter(element)) {
Integer current = sums.get(key);
if (current == null) {
sums.put(key, transform(element));
} else {
sums.put(key, current + transform(element));
}
}
}
List<Map.Entry<Integer, Integer>> entries = new ArrayList<>(sums.entrySet());
entries.sort(Comparator.comparingInt((x) -> -x.getValue()));
ArrayList<Integer> result = new ArrayList<>();
for (int i = 0; i < 10; i++) {
if (entries.size() <= i){
break;
}
result.add(entries.get(i).getKey());
}
return result;
Заключение
В целом получилось, что для всех случаев у функционального подхода если и есть проигрыш, то, на мой взгляд, он несущественный. При этом код, на мой взгляд, становится чище и читабельнее (если говорить про Kotlin, Scala и другие языки, изначально поддерживающие ФП), а под капотом могут быть полезные оптимизации.Не экономьте на спичках: вы же не пишете на ассемблере, потому что “так быстрее”? Действительно, может получиться быстрее, а может и нет. Компиляторы сейчас умнее одного программиста. Доверьте оптимизации им, это их работа.
Если вы все еще используете какой-нибудь mutableListOf, задумайтесь. Во-первых, это больше строк кода и бОльшая вероятность сделать ошибку. Во-вторых, вы можете потерять оптимизации, которые появятся в будущих версиях языка (или уже есть там). В-третьих, при функциональном подходе лучше инкапсуляция: разделить filter и map проще, чем разбить цикл на два. В-четвертых, если вы уж пишете на языке, в котором есть элементы ФП и пишете “циклами”, то стоит следовать рекомендациям и стилю (например, Intellij Idea вам будет настоятельно рекомендовать заменить for на соответствующее преобразование).