Профдеформация и C
C/C++ (именно в таком сочетании) я в базовом варианте изучил за пару летних месяцев перед универом. Тогда для меня он был просто заменой паскалю, и уровень задач был соответствующий — всякая мелочевка для развлечения и разнообразные числодробилки. Универ со своими лабами не сильно что изменил (я получил автомат по программированию в те времена, когда по всем предметам надо было сдавать экзамены и не было балльной системы); Python, JavaScript и даже Java мимо пробегали, но всякие тесты булевой функции на монотонность проще писались на C/C++.
На первых двух работах мне даже платили за то, что я писал на C++, но я тогда был джуном и это все сейчас кажется несерьезным (хотя уже будучи зрелым специалистом написал на C++ модуль ядра для BSD, это был прикольный, но мимолетный опыт). Тем более что потом переключился на Python, оттуда на Scala и понеслось…
В общем, получается, что всерьез, профессионально, на Си я и не писал никогда. А вот в последние несколько месяцев я как раз этим и занимался в рамках научного проекта. И (вполне закономерно) оказалось, что процесс не сильно-то отличается от других языков.
Все стандартные паттерны в наличии, например:
- разделение интерфейса (
.h) и реализации (.c) - своего рода полиморфизм можно построить на структурах и указателях на функции
- разделение
apiиimpementationв зависимостях (где включать заголовок — в.cили.h) - всякие билдеры, стратегии и фасады — это вообще легко
typedef— one love ❤️- даже шаблоны можно сделать, правда макросами
- и т.п.
При этом возникает понимание многих конструкций, которые казались “лишними”: extern, static, макросы (увы, некоторые прикольные штуки только ими и получается делать), префиксы для функций из разных модулей (даже в не очень большом проекте словил коллизию имен, неймспейсов не хватает), #ifdef DEBUG и отдельная сборка под valgrind или санитайзеры (потому что без отладочного -g особо и не отладишь утечки памяти, а еще valgrind не знает всех инструкций из -march=native и может даже врать про номера строк на -03). Более того, -Wall выдает все замечания по делу! Хотя inline с его приколами все еще невнятный какой-то :/
В более высокоуровневых языках обычно многие вещи делаются гораздо проще (но не во всех конечно *выразительно смотрит на java*), да и “мыслишь” после них более абстрактно. Часто себя ловил на мысли, что вот тут лямбду надо бы, а их особо и нет (только указатели на функции), а вот тут хотелось бы иметь возможность тип менять (вместо void *), а вот тут частичное применение функции прям зашло бы… Не хватает простых вещей типа Option, а указатели уже не хочешь использовать, потому что дешевле структуру передать.
Увы, инструменты разработки — не сильная сторона Си. Makefile еще можно потерпеть, autoconf сотоварищи — просто жесть, пакетный менеджер — мимо, VS Code опять выбесил по какой-то фигне, а добил меня миллион настроек clang-format, после которых я “обманываю” форматтер пустым комментарием, чтобы не совсем отвратно выдавал список аргументов функции. Впрочем, ничего нового (осторожно, по ссылке кринж). После космических технологий вроде IntelliJ Idea или Gradle — все очень грустно.
При этом язык все еще развивается. Например, весьма пригодились составные литералы:
return (some_struct_t){
.field1 = value1,
.field2 = .value2, // trailing comma FTW!
}
Сейчас есть стандарт c17, а еще грядет c23 — и там есть много прикольных штук, про многие из которых я могу сказать: да, такая фича пригодилась бы! Даже лямбды маячат на далеком горизонте, но добавить их — непростая задача.
В общем, писать что-то на низкоуровневом языке достаточно интересно (если это не Zig :)). Это полезное упражнение, чтобы понять, как много делают всякие хорошие инструменты и библиотеки, да и собственный прогресс оценить. “Вернуться к истокам” тоже прикольно. Когда писал пост, откопал в папке со своей универской фигней вот такую хрень, которая датируется 2010 годом:
#include <stdio.h>
class foo
{
friend bool operator < ( bool left, const foo& right );
friend int operator ^ ( int left, const foo& right );
};
bool operator < ( bool left, const foo& right ) { return left; }
int operator ^ ( int left, const foo& right ) { return left; }
int main()
{
int O_o = 0, _ = 0, baka = 0; foo o_O, neko;
bool XD = O_o >_< o_O;
int nya = baka ^_^ neko;
//printf("%d ",nya);
printf("%d ",XD);
return 0;
}
Очевидно, все вышеизложенное хорошо так субъективизировано связанными воспоминаниями из тех времен :) Но даже с учетом этого впечатления останутся положительными.
Что бы там не пророчили, кажется, что Си пока рано умирать.

Мой профессиональный рост
Первые две свои работы я нашел “по знакомству” благодаря универу. В своем первом “настоящем” резюме я чисто ради кеков указал:
∏ρ؃uñçτØρ Øπτµç∑ принял от меня 6 постов, если это важно.
Большинство потенциальных работодателей на это не обращали внимания (кто ж читает эти резюме), некоторые не знали, что это вообще, пара человек удивились и похвалили. Но строчку все равно я оставил, только счетчик постов увеличивал.
Потом мою смешнявку админ профунктора не просто принял, но еще и репостнул себе в личный канал. Не зная, как совладать с этим, я жахнул на сайтик галерею со своими картиночками.
{kind=link}

Потом еще сделал альтернативный рейтинг смешнявок, чтобы компенсировать свое падение в его рейтинге с 9 места на 26-ое. Скинул админу, он заценил, но, увы, время было совсем неподходящее для таких развлекух, обещал, что позже постнет. “Позже” не наступило… Между тем оригинальный рейтинг уже не грузится, а мой еще работает.
После этого завирусилась шутка про говно.
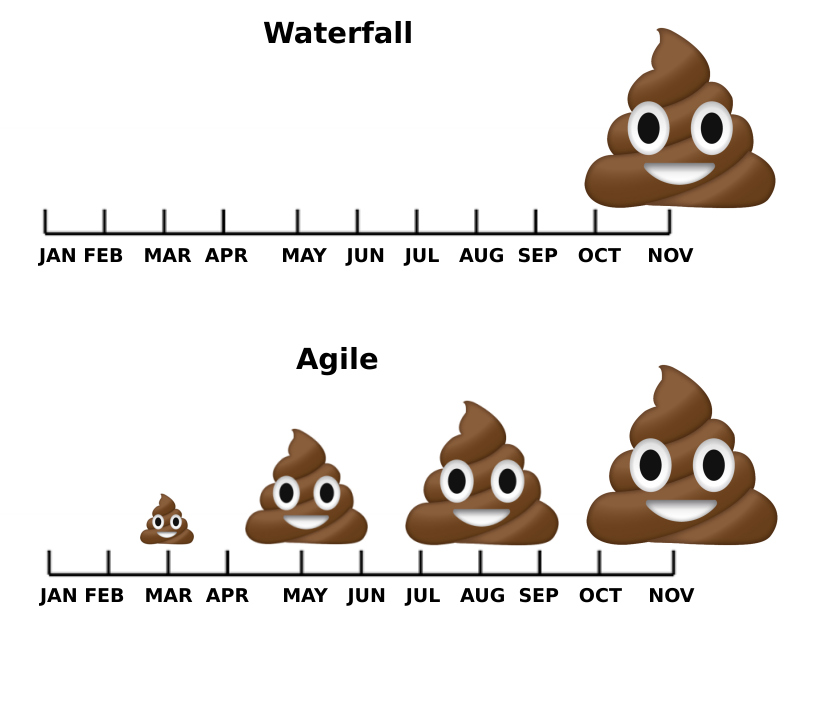 По крайней мере я ее видел очень много где, и в недружественном интернете тоже.
По крайней мере я ее видел очень много где, и в недружественном интернете тоже.
В последнем резюме я кеки уже не указывал: место надо экономить, да “и не солидно” же. Но через год работы мой мем используют для рекламы нашего платного продукта. На сайтике, я, разумеется, оставлю первую версию:

Успех, чо :)
Автовыбор браузера с Zig
Написал небольшую утилиту на Zig, которую можно использовать в качестве маршрутизатора для браузеров, чтобы, например, гугл-доки и прочую работу открывать в хроме (сесурити беспощадное), а все остальное — в Firefox. Поделюсь своими страданиями, можете использовать тепло моего пердака холодными вечерами:)
Предварительные ласки
Продающее видео
Честно говоря, про Zig я раньше слышал довольно мало и имел смутное представление, что это очередная попытка заменить Си, что там есть киллер-фича с вычислениями во время компиляции и своя система сборки с кросс-компилятором.
Знакомство я начал с довольно рекламного видео от создателя. Несмотря на то, что оно в основном про язык, все равно рекомендую его глянуть, т.к. кроме демонстрации собственно языка и фич типа компиляции, смешивания с Си, сборки и т.п. там есть довольно интересный фрагмент на 19:45 про жизненный цикл компаний с целью получения прибыли в противовес некоммерческим организациям. Да и сам доклад хорошо подан и дает пищу для размышлений.
Я немного пошарился по официальному сайту и обнаружил полный финансовый отчет за предыдущий год. Такая прозрачность подкупает, да и сами данные весьма интересные.
Ресурсы для обучения
Вдохновленный докладом, я полистал неофициальный туториал. В целом он сойдет для того, чтобы узнать, что есть в принципе в языке, но местами он очень сильно упрощает некоторые вещи, а иногда даже откровенно врет. Например, в разделе про условия четко написано:
Zig’s if statements only accept bool values (i.e. true or false). There is no concept of truthy or falsy values.
Круто же! А потом начинаешь писать код, и приехали:
if (default) |def| {
...
Ну и что это такое, я вас спрашиваю?
Фича-то классная (default — nullable значение, а условие проверяет на равенство null и при его выполнении уже гарантированно не-null значение будет в def), но зачем тогда на ровном месте придумывать несуществующие принципы?
Официальная документация в этом плане получше, но примеры довольно куцые. И это документация чисто по языку, а для стандартной библиотеки есть аналог JavaDoc, со всеми его минусами.
Очень не хватало примеров использования. На удивление, одним из самых полезных источников оказался Reddit. Второй по качеству — тупо поиск в GitHub по конструкциям. Пробовал пользоваться ChatGPT — полная шляпа.
В итоге я решил последовать своим стандартным путем: писать как пишется, разбираться с проблемами по ходу дела. Кривая обучения фиговая, зато материал на пост наберется:)

Уже ближе к концу эксперимента вспомнил про learn X in Y minutes — довольно неплохой вариант в итоге оказался для введения, правда, дорога ложка к обеду.
Выбор проекта
Изначально я думал сделать что-нибудь число-дробильное, типа генерации лабиринта. Подумывал даже использовать фреймворк WASM-4, чтобы получилась мини-игра в браузере.
Но мне было лениво разбираться еще и с алгоритмом. Да и вспоминая свои приключения в связке Rust + WASM, решил отказаться от этой идеи (там есть еще и другие языки, чтобы на них пострадать).
Вспомнив свой опыт с Kotlin, решил посмотреть, что интересного есть в репозитории. Список contributor-friendly задач довольно занятный:
- simplify the panic handler function to be only one function; remove -fformatted-panics
- Genericize tracing interface
- Allow COFF output for freestanding target
- Support inferred error sets in recursion
- Add SIMD Support
- add a builtin function for every llvm C library intrinsic and bit manipulation instrinsics
Эээ, не, ну я конечно слова понимаю, но я ожидал чего-то типа “поправь тут мелкий баг”…
Ладно, выберем задачку попроще. Опять всплыла проблема разделения рабочего/нерабочего по разным браузерам по причине безопасной безопасности. Поэтому можно написать простенькую консольную программу, которая возьмет ссылку и выберет, в каком браузере ее открыть, и поставить ее в качестве браузера по умолчанию. С конфигом можно особо не париться — простого текстового файлика с регулярками хватит за глаза. Конечно, все случаи это не покроет, но “внутри” браузеров можно будет специальные расширения использовать.
В общем, простая консольная программка, которой нужно прочитать файл, прочитать аргумент командной строки, проверить его по регулярке и запустить приложение. Язык должен отлично для этого подходить, что может пойти не так?

Впечатления от языка
Парсим аргументы командной строки
Первое, что я обнаружил по этому вопросу — ноль информации в документации.
Я вышел с данным вопросом в интернет и обнаружил, что это оказывается пипец какая непростая задача.
Во-первых, нельзя просто так взять и прочитать argc и argv.
Во-вторых, очевидный метод std.process.args() не кроссплатформенный.
Вместо него нужно использовать специальный метод, который принимает аллокатор (как и все методы Zig, которые могут выделить память: это вообще довольно полезная фича, особенно когда вы пишите что-то вроде Redis).
Однако и тут есть пара вариантов: либо использовать итератор, либо слайс (массив с размером).
Второй вариант вроде привлекательнее, но он требует передавать аллокатор в деструктор (W A T), поэтому решил использовать итератор.
В итоге это безобразие выглядит так:
var args = try std.process.ArgIterator.initWithAllocator(allocator);
defer args.deinit();
_ = args.next(); // args[0], ignore
if (args.next()) |link| {
... // do stuff
Существенное улучшение читабельности по сравнению с сишным вариантом char * link = argv[1], не правда ли?
Уважаемые знатоки, внимание вопрос: на кой черт мне нужны все эти низкоуровневые детали, если аргументы я все равно не могу без аллокатора получить?
И какого черта аллокатор нужен в деструкторе при варианте с std.process.argsAlloc(alloc)?
var и const
Уже де-факто стандарт индустрии, отличная штука.
Правда в Zig есть нюанс с этим.
В примере с аргументами я не мог понять, что не так с аргументами: почему переменная с итератором var, а не const.
Даже у ChatGPT спросил:
In Zig, the const qualifier denotes that a value is immutable. This means that the value cannot be modified after it has been assigned. However, when working with an ArgIterator for command-line arguments, you typically want to advance the iterator to process each argument in sequence. The act of advancing the iterator involves modifying its internal state, which is not allowed for const values. The ArgIterator type likely has methods like next that internally update the iterator’s state to point to the next argument. These methods, by nature, involve modifying the iterator, making the iterator itself non-const.
Довольно достойный ответ, и правдивый. Жаль только, что это был последний хороший ответ от ChatGPT.
printf и ошибки компилятора
О, да это же System.out.println!
main.zig:14:18: error: expected 2 argument(s), found 1
std.debug.print("Wat?\n");
Хмм, а если std.debug.print("Wat?\n", "another string");?
/opt/homebrew/Cellar/zig/0.11.0/lib/zig/std/fmt.zig:87:9: error: expected tuple or struct argument, found [:0]const u8
@compileError("expected tuple or struct argument, found " ++ @typeName(ArgsType));
Мягко говоря, не очень понятные ошибки от компилятора. Читать документацию — для лохов, ща все настоящие программисты с ChatGPT все пишут!
ChatGPT начал меня газлайтить: сначала сказал, что мой код неправильный, и предложил исправить…. на мой же код. Я указал на это и он сказал, что да, так и должно быть. Ну, спасибо, чо.
Потом пригляделся к ошибке и заметил, что компилятор не показывает номер строки с ошибкой:
/opt/homebrew/Cellar/zig/0.11.0/lib/zig/std/fmt.zig:87:9: error: expected tuple or struct argument, found void
@compileError("expected tuple or struct argument, found " ++ @typeName(ArgsType));
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~

Ошибка в итоге оказалась, разумеется, очень дебильной: у меня стояло {} вместо .{}.
Дело в том, что print принимает в качестве второго аргумента кортеж, и если аргументы не нужны, то надо явно передать пустой (.{}).
А номера строки с ошибки не было видно потому, что шаблон формировался на этапе компиляции (та самая фишка с выполнением на этапе компиляции).
К счастью, на данный момент у меня был ровно один print и я смог разобраться.
Но чуть позже, уже по колено в коде, у меня снова появилась ошибка без указания строки:
/opt/homebrew/Cellar/zig/0.11.0/lib/zig/std/fmt.zig:499:17: error: cannot format optional without a specifier (i.e. {?} or {any})
@compileError("cannot format optional without a specifier (i.e. {?} or {any})");
и у меня на этот момент было уже куча print’ов, так уже и не поймешь, в каком проблема.
Перепробовав несколько вариантов в наиболее вероятном месте
std.debug.print("Failed to execute command: {}\n", .{err});
...
std.debug.print("Failed to execute command: {any}\n", .{err});
...
std.debug.print("Failed to execute command: {!}\n", .{err});
...
std.debug.print("Failed to execute command: {s}\n", .{@errorName(err)});
и не получив успеха, я решил все-таки как-то достать номер строки — ну не может же быть все настолько плохо. И правда, есть баг, но он исправлен. Зато есть другой, и он исправлен в следующей версии. В общем, провал.
Пришлось искать ручками.
В итоге нашлась проблема, но блин, это такая базовая вещь, я ожидаю этого в 0.2.0, но не в языке, которому 7 лет -_-.
Проблема довольно тупая — в шаблон для строки {s} передавалось nullable значение, для которого, соответственно, нужен {?s}.
Строки
Все просто, строки — это массивы байт! Годы опыта кучи разрабов, UTF-8 и прочая лабуда идут прямиком в помойку, ура!
И разумеется, как и для любого указателя, есть константный []const u8 и неконстантный вариант []u8.
*вьетнамские вертолеты из Си*.
Для строк нет ничего толкового из коробки.
Хочешь сравнить две строки?
memcmpstd.mem.eql(u8,s1,s2).
Хочешь проверить, начинается ли строка с какой-то подстроки?
std.mem.eql(u8, line[0..3], "cmd")!
Хочешь найти позицию пробела — пиши функцию, братан.
Разбить строку по пробелу — вспоминай лабу номер 147 из универа, образование наконец пригодилось!
Чтобы было еще веселее, у нас есть строки, слайсы (массив с размером), и нулл-терминальные. Разумеется, без адекватных методов конвертации между ними. Поэтому даже в стандартной библиотеке есть, например,
fn execveZ(path: [*:0]const u8, child_argv: [*:null]const ?[*:0]const u8, envp: [*:null]const ?[*:0]const u8) ExecveError
и
fn execve(allocator: Allocator, argv: []const []const u8, env_map: ?*const EnvMap) ExecvError
которые делают одно и то же — выполняют команду с аргументами.
Для удобства использования они еще и в разных пакетах — std.os и std.process соответственно.
Разумеется, я выбрал первый вариант: потому что он оптимальнее, там же не надо выделять память! Ну еще и потому, что он был в найденных примерах, и про второй вариант я просто не знал :).
Отдельно отмечу [*:null]const ?[*:0]const u8 — чувствуете, как все стало гораздо проще по сравнению с этими ужасными Сями?
Как эволюционировало человечество и теперь прочитать и понять тип может любой ребенок или чат-бот?
Putting it all together, it seems like the code declares a constant named u8 with an optional pointer or array of zero elements that can be null, and the constant holds an unsigned 8-bit integer value. The null and the optional aspect suggest that the constant might be a nullable pointer or array.
В какой-то момент у меня получился вот такой монстр:
fn launch(cmd: Cmd, link: String, allocator: std.mem.Allocator) !void {
const cmd0: [*:0]const u8 = try allocator.dupeZ(u8, cmd);
const link0: [*:0]const u8 = try allocator.dupeZ(u8, link);
const argv = [_:null]?[*:0]const u8{link0};
const env = [_:null]?[*:0]u8{};
const result = std.os.execvpeZ(cmd0.ptr, &argv, &env);
std.debug.print("Failed to execute command: {}\n", .{result});
}
Этот маленький кусочек кода стоил мне пары часов жизни. Я очень долго трахался с нулл-терминалами, чтобы понять, что не ту функцию зову. В итоге все упростилось до
const cmd_args = [_][]const u8{cmd, link};
// either executes or returns an error
const err = std.process.execv(allocator, &cmd_args);
std.debug.print("Failed to execute command: {}\n", .{err});
Да, я тупой, надо было сразу нормальную функцию использовать, но кто ж знал-то! Тем более после изврата с аргументами командной строки это казалось не таким уж неадекватным.

Читаем файл
Разумеется, опять все плохо с документацией и примерами.
И опять надо думать — а что, если строка не поместится в буфер? Как тогда поступить?
Есть ли какие-то удобные абстракции, чтобы не было char[1024][1024]u8?
Ну что-то конечно можно наскрести, но так погано это выглядело, что я забил и оставил фиксированный буфер.
Пути файлов — это просто строки. Прошу прощения, слайсы байтов. Нет UTF-8, нет проблем со всякими NFD и NFC!
Просто так файл нельзя открыть, нужен Reader, да еще и обернутый для буферизации (привет джавистам!).
readline — слишком неочевидно, нужно максимально точно описать действие:

Не стоит забывать и об обработке ошибок. Жаль конечно, что вызов функции — в условии цикла, придется это делать прямо там:
var file = try std.fs.cwd().openFile(path, .{});
defer file.close();
var buf_reader = std.io.bufferedReader(file.reader());
var in_stream = buf_reader.reader();
var buf: [1024]u8 = undefined;
while (in_stream.readUntilDelimiterOrEof(&buf, '\n') catch |err| {
std.debug.print("Error during file reading: {}\n", .{err});
return null;
}) |line| {
... //do stuff
}
Потом еще натыкаюсь на эту статью, в которой все делают “правильно”, а код в итоге медленнее чем аналог на Go. Здорово, правда?
undefined и nullable
У nullable те же проблемы, что и для Kotlin, повторяться не буду, да и не очень это тут мешало.
А вот undefined немного странный.
Вроде это как lateinit с не очень понятным синтаксисом.
Им можно инициализировать, но сравнить с ним уже нельзя:
config.zig:65:18: error: operator == not allowed for type '[]const u8'
if (!(default == undefined)){
В итоге тупо заменил на nullable.
Скорее стоит рассматривать undefined как неинициализированную переменную, такая ментальная модель работает.
Хотя я бы написал просто var default: String, это более логично.
Видимо опять явное лучше неявного, но = напрягает и ломает привычную семантику.
Импорты и альясы типов
Программка начала разрастаться, надо бы выделить конфиг в отдельный файлик.
Импорты довольно интересно реализованы: это функция, которая возвращает структуру.
У импортов всегда есть префикс, т.е. никаких тебе from std import *, from std import mem или using namespace std;.
Не очень удобно, но это сложившаяся практика из плюсов.
Благо есть альясы, т.е. можно написать
const Allocator = std.mem.Allocator;
Однако, если я хочу везде использовать альясы типов, то тогда придется либо в каждом файле писать const String = types.String; либо везде types.String — не очень удобно, если альясов много.
Сейчас осознал, что надо было бы третий файл создать чисто для альясов типов, но когда писал код, заленился делать это ради трех строчек.
Регулярки
Их нет. Впрочем, с учетом молодости языка, не так уж и страшно. Есть два стула — какой-то очень стремный вариант с regex.h и библиотека. Выбираем библиотеку, опять наступаем на грабли с const/не const и пишем
var matcher = filter.matcher;
if (matcher.match(link) catch false){
вместо
if (filter.matcher.match(link) catch false){
Это прям прикол, т.е. я из константного указателя сделал неконстантный просто добавлением промежуточной переменной? Но зачем регулярке быть мутабельной? Да даже если и надо было, то как/почему добавление промежуточной переменной помогает ситуации? Оставлю это как упражнение читателю. Ссылочная прозрачность нервно стоит в углу — ей тут явно не рады.
Обработка ошибок
Синтаксис довольно нестандартный — это можно заметить в примере кода выше, где мы “ловим” false.
На самом деле matcher.match(link) catch false означает
val result = matcher.match(link)
switch (result){
case Success(value) => value
case Error(_) => false
}
По сути, многие функции возвращают аналог Result, который либо искомое значение, либо ошибка.
Ошибки — это тоже тип-объединение, т.е. один из паттернов это
catch |err| switch (err) {
error.SomeType => ...
error.AnotherType => ...
...
}
Можно эскалировать ошибку через try statement: если вернется ошибка, то она просто будет возвращена из текущей функции.
По факту, это еще один взгляд на обработку эффектов и аналог проверяемых исключений.
Вроде короче и можно привыкнуть, но иногда читается тяжело, как в примере с catch false.
То, что try и catch не могут в одной конструкции появиться и несовместимы, рвет шаблон.
Первое время еще путал catch с oresle от nullable-значений (он просто возвращает другое значение, если искомое это null).
Все это звучит конечно очень классно, но, честно говоря, я немного задолбался писать обработку ошибок на каждый чих, чтобы было 100% корректно. И некоторые ошибки при этом все равно засовываются под ковер. Получается, что я обязан обработать ошибку, что аллокатор не выделил память, но могу забить на то, что у меня слайс с отрицательным размером.
Есть еще функции, которые просто ошибку возвращают (например, execve), они довольно криво обрабатываются, потому что это уже не объединение с ошибкой и ни try, ни catch не применимы.
В итоге 6 гошных if err != nil { return err } из 10.

Функции
Аргументы передаются по значению. Опять надо думать об указателях (и не забывать про константность!).
Аргументов по умолчанию нет — явное лучше неявного (джависты опять передают привет!).
Забавно, что в заведенном тикете с обсуждением этого точно такой же пример функции, которая нужна была мне: поиск подстроки в строке.
Кстати, с неироничным goto.
По колено в коде я понял, что что-то не сходится: я ж структуры туда-сюда передаю, причем сложные, с HashMap, неужели они копируются тупо? Или копируются указатели? Читаем документацию:
Structs, unions, and arrays can sometimes be more efficiently passed as a reference, since a copy could be arbitrarily expensive depending on the size. When these types are passed as parameters, Zig may choose to copy and pass by value, or pass by reference, whichever way Zig decides will be faster. This is made possible, in part, by the fact that parameters are immutable.

Т.е. у нас явное лучше неявного, везде надо быть максимально прозрачными и однозначными, для соглашений о вызове есть отдельное ключевое слово callconv, но вот тут и конкретно тут компилятор будет на рандоме это решать?
Коллекции
main.zig:12:13: error: type 'array_list.ArrayListAligned(config.Filter,null)' is not indexable and not a range
for (config.filters) |filter|{
~~~~^~~~~~
main.zig:12:13: note: for loop operand must be a range, array, slice, tuple, or vector
Nuff said.
Нельзя итерироваться по arrayList, Карл!
Даже не буду заикаться про всякую функциональщину.
Вывести массив в консоль?
Пиши функцию, братан, удачи с циклами.
Никаких тебе готовых .toString(), максимум тип и адрес (хватит списывать у Java!).
Типы и дженерики
Для хорошей ошибки нужно было вывести ключи хэш-таблицы. Дженерики очень мутные. Прикольно, что с типам можно работать как со значениями: записывать в переменные, передавать как аргументы функции, использовать функции для конструирования сложных типов… и все это на этапе компиляции! Но только до тех пор, как тебе нужно этот тип указать. Тот самый, который пропущен через 2-3 функции. Еще хуже — указать ограничения на тип. В итоге у меня получилось что-то такое:
fn getHashMapKeys(comptime K: type, map: std.hash_map.HashMap(K, String, std.hash_map.StringContext, 80)) ![]K {
var keys = std.ArrayList(K).init(map.allocator);
var keys_iter = map.keyIterator();
while (keys_iter.next()) |key| {
try keys.append(key.*);
}
return keys.items;
}
И если вы думаете, что это работает, то ошибаетесь.
Среди прочих проблем отмечу тут 80 — это коэффициент по умолчанию.
Да, это параметр типа (наконец-то можно привет и плюсам передать).
Как его проигнорировать, я не понял.
Теоретически можно было проверить тип, но я уже вертел что-то такое делать и просто скопипастил кусок кода в двух местах.
Финальный удар
Уже на этапе тестирования я заметил, что ничего не работает (кек). Почему-то в хэш-таблице у меня был какой-то мусор.
Я сделал очень тупую проверку: вставлял в таблицу, и сразу же проверял вставленное — работает. Проверяю на следующей итерации — этого значения уже нет. И тут на меня снизошло озарение.
Суть в том, что я парсил конфиг, брал слайсы от строк, разбивал их на ключ-значение и клал в хэш-таблицу. Что-то вроде
cmds.put(line[4..space_pos], line[space_pos+1..])
Оказалось, что HashMap просто копировала слайс.
А line — мутабельная память, в которую чтец файла писал текущую строку из файла.
И в ключах я видел не мусор, а подстроки текущей строки из файла.

Т.е. я должен дрочить обработку ошибок на каждый чих, но вот мутабельные ключи в хэш-таблице это совершенно нормально и мне даже предупреждения никто не покажет?
На всякий случай: это не какая-то там левая библиотека, это стандартная библиотека и стандартная таблица!
Спасибо, хоть тикет есть.
Есть еще bufMap, но она только для строк массивов байт.
С этого у меня сгорело очень знатно -_-
Деплоим
Собираем
Прикольно, что можно сделать просто zig run main.zig и все соберется и запустится.
Вроде как даже инкрементально.
Жаль только, что это мгновенно ломается, как только появляются внешние зависимости, и уже надо делать zig build run.
Скрипт сборки — это тоже код на Zig. Вроде прикольно и гибко, но только не очень понятно, зачем мне 30 строк, где половина мне не нужны, а назначение еще трети не очень понятны.
С инкрементальностью тоже были проблемы — я случайно удалил итоговый исполняемый файл и пересборка его не создала (ну а че, входные данные-то не поменялись, логично же).
В итоге просто удалил zig-out и пересобрал с нуля.
Пакетный менеджер появился только в текущей версии, 0.11. Документации на него, разумеется, ноль. Лучшее, что есть — запись в бложике, но даже с ней зависимость подключилась не с первого раза.
Чтобы подключить библиотеку, нужно найти ее на гитхабе, найти нужный коммит и его хэш, сформировать правильную ссылку на архив и правильно добавить ее в спискок зависимостей (два раза в скрипт для сборки и один раз в аналог package.json).
Встроена проверка целостности.
Увы, это не какой-нибудь известный хэш, а что-то, покрытое завесой тайны.
Народ советует буквально посмотреть на ошибку валидации и просто вставить из нее ожидаемых хэш (“Это безопасно” — Дэвид, эксперт по безопасности).
Т.е. вроде похоже на Go, тоже качаем с гитхаба, только еще куча дополнительных приседаний.
Итоговый исполняемый файл получился 1.4 мегабайта на MacOS, 2.3 на Linux.
Да-да, МЕГА.
Но если включить оптимизацию под размер (zig build -Doptimize=ReleaseSmall), то можно скукожить до 64 Кб.
С учетом того, что у бинарника 0 зависимостей — неплохо.
Mac
Наконец-то есть консольное приложение, работает как надо, пора сделать его браузером по умолчанию! Увы, нельзя просто так взять и поставить какое-то случайное приложение браузером, вы должны доказать, что это приложение, и что это браузер!
Как из бинарника сделать приложение App?
Это какая-то дичь.
Нужно сделать иерархию папок, положить туда бинарник, положить рядом специальный текстовый файл Info.plist с кучей текста, потом выполнить одну команду, чтобы получить пакет-архив, сделать еще Distributions.plist где вся та же информация, что в Info.plist, но другая, выполнить другую команду, которая такая же как предыдущая, но другая.
Получившуюся лабуду протащить через все карантины и вот, это уже App.
Все это я слепил по примерам из даркнета и на основе установленного Firefox раза с 20-го. Увы, я не смог найти волшебной команды “вот бинарник, сделай приложение, позязя”.
Разумеется, приложение не заработало.
Оказывается, у Apple свой путь даже в этом.
Передавать аргументы через argv — это для красноглазиков, поэтому всякая информация передается приложениям только через события AppleEvents.
В 10.6 (2009 год, на минуточку) теоретически можно такое делать, но обратная совместимость не дремлет, поэтому другого пути, как я понял, нет.
Только события по закрытому протоколу, только хардкор.
Я потыкался некоторое время в поисках хоть какого-то костыля, который позволит это обойти. Увы, ничего простого не нашлось, подключай библиотеку для эти событий.
Посмотрел, как это сделано в браузерах. В хромиуме вообще куча исходников на Objective-C++, и в одном из них как раз идет извлечение ссылки из события. В Firefox, тоже есть Objective-C++ и там аналогично используются эппловские библиотеки, чтобы получить ссылку из события.
Кстати, узнал, что в Firefox внезапно используется Gradle и не ради какого-нибудь билда на андроиде, а в качестве оркестратора более сложной системы сборки, в которой фигурируют CMake, Cargo и Python.
В общем, я понял, что тут еще на недельку горения (изучение библиотек Apple, протокола, попытки создать троллейбус из Zig и Objective-C++), решил пока плюнуть. Может, вернусь к этому позже.
Linux
В линуксе регистрация приложения как браузера зависит от оконного менеджера.
Я попробовал сначала через update-alternatives: скопировать в /opt, зарегистрировать вариант, и поставить его вариантом по умолчанию.
Всего три команды, жаль, не сработало:)
Окей, план №2.
Создаем ярлык, точнее, копируем имеющийся для хромиума и удаляем весь лишний мусор типа переводов на болгарский (Name[bg]=Уеб четец Chromium).
Говорим, что этим ярлыком можно открывать ссылки.
Ставим ярлык в качестве браузера по умолчанию с помощью xdg-settings.
Готово, вы великолепны!
Попутно еще научился трюку, как скрипт заставить запустить самого себя от sudo, а потом еще и от имени пользователя что-то доделывать.
Никогда не думал, что буду получать удовольствие от написания скриптов на баше. Но после Zig и Java это так освежает:)
Итого
Чтобы вы не думали, что я весь такой негативщик и везде только плохое ищу, вот бложик, который содержит похожие впечатления о языке и дополнительные приколы. А тут более сдержанное мнение, с объяснениями, почему так происходит.
Я считаю, что страдал слишком много с этим языком. С Rust я тоже страдал, но там я хотя бы понимал, что я получаю взамен, и было понятно, откуда возникают сложности. Про Zig я такое сказать не могу. Мне кажется, что даже при написании кода на Go я меньше фрустрировал — там хотя бы попроще были многие вещи и местами лучше абстракции.
Я не очень понял нишу Zig. Улучшенный C? Я вижу кучу проблем, которые помню из Си и которые сохранились (например const/не const). Да, что-то стало лучше, но не уверен, что оно стоит того. Скорее ощущение, что все многое из плохого осталось, да еще и нового добавили.
Может, все ради производительности? Да, можно управлять аллокаторами. Да, программист вынужден использовать более низкоуровневые абстракции. Но вот приколы, когда ты не знаешь, по указателю ли будет передан аргумент или по значению (компилятор решит) — так себе с этим стыкуется. Ну и конечно, поведение стандартной хэш-таблицы — это просто дичь. Если мне нужна производительность в ущерб корректности, я выберу Си. Да и насчет производительности, как выяснилось в истории про чтение файла, у сообщества есть вопросики.
Безопасная работа с памятью? Ну может тут и лучше ситуация, чем в Си, но после ситуации с хэш-таблицей это смешно. И до Rust тут как до Луны, вот там-то с памятью и владением не забалуешь.
Может быть, язык проще? Очень сомневаюсь. Да, проще, чем Rust, возможно проще для людей, которые только на Си и пишут, но тут это скорее за счет малого числа абстракций. И это скорее минус, чем плюс, по-моему. Если вам нужно “проще”, то берите Go.
Какая-то классная фича, которая прямо расширила мое сознание? Снова нет. Я даже не почуствовал какой-то философии языка или какого-то принципиально нового взгляда на вещи. В этом плане Rust и Elm были интереснее.
В целом, не ожидал такого разочарования от языка с кучей положительных отзывов. Да, тут есть интересные идеи, но не уверен, что за ними будущее. Понятно, что язык только развивается и у него есть потенциал, но я ожидал чего-то большего.
Ну и как обычно, опять сгорел на ровном месте от пет-проекта и попытки изучить что-то новое.

Самое странное английское слово
В интернете полно юморных видосов про несоответствие написания и произношения английских слов (например, 1, 2, 3). Мне пришла в голову дурацкая идея — найти слово, которое больше всего на себя не похоже (choir? through?).
Это оказалось весьма “весело” по нескольким причинам:
- Нет нормального словаря “слово-произношение IPA”. На выбор есть дамп викисловаря и его парсер, который не смог за сутки при полной загрузке CPU и памяти обработать жалкий XML на 8ГБ. Есть предобработанный результат в JSON, но он оказался довольно захламленным странными словами, аббревиатурами, записями вида
E=mc², фамилиями и т.п. В итоге использовал альтернативу, но там тоже хватает мусора (например, zyuganov или fyi), который в итоге пришлось фильтровать вручную. Нашел еще CMU, но он непонятный и не IPA. - У одного слова есть несколько произношений, даже с учетом того, что словарь только для американского английского. “Awkward” еще некритично (/ˈɑkwɝd/—/ˈɔkwɝd/), а вот к “question” уже вопросы: /ˈkwɛstʃən/—/ˈkwɛʃən/”. В итоге я брал “наименее непохожее”. Ну и разумеется, есть масса нюансов типа длительности, смещений, ударений и т.п., которые я не учитывал.
- Что считать словом? *место для вашей исторической справки про “Эрудит” и как там за слово считается почти все*. Помимо мусора, надо отфильтровать имена собственные (потому что их невозможно правильно записать, прости, Хосе), существительные во множественном числе (халявная s→z!). Но что насчет “lb” /ˈpaʊnd/? Или “etc” /ˌɛtˈsɛtɝə/? Или даже “gg” /d͡ʒiːd͡ʒiː/? А можно ли оставлять “chlorofluorocarbon” и прочую химию? А составные слова? А слова через дефис, “non-human”? А жаргон типа “physio”? Названия блюд? Список можно продолжать очень долго.
- Как сравнивать? Конечный результат можно получить через расстояние Левенштейна и учесть длину слова. Получать произношение из слова — явное безумие, о чем намекают статьи с заголовком The 46 English Pronunciation Rules. Получить написание слова из IPA вроде как проще… Проблема только в том, что звуков больше, чем букв. И звуки /e/, /æ/, /ə/, /a/ все будут записаны как “a”. Штош, я все равно их не различаю :) Вот только /ə/ может быть записан любой из гласной букв. И не только он — у всех звуков есть вариации. В итоге для каждого звука я взял самую частую запись, позволив небольшие упрощения для пар с
ʊи чуть большую “логичность” для согласных (потому что очень странно заменять /j/ на самый частый вариант — “u”, как в popular /ˈpɑpjəɫɝ/). - Разумеется, отображение звуков на буквы даже при таких упрощениях не сюръективное (например, нет звука, который отображается в букву “x”). Отображение некоторых звуков в две буквы немного мешает. Поэтому преобразуются и произношение, и слово в какой-то буквенный суррогат.
- Нелегко понять, какое произношение “g” “более правильное” — /dʒ/ или /ɡ/. Аналогичная ситуация с “q” и “c”. В итоге решил по случайно выбранной статье.
- Даже с расстоянием Левенштейна можно выделять “любимчиков”. Если звук заменен — это явно различие больше, чем просто добавление дополнительного звука или пропуск. Поэтому настроил, что замена дает расстояние 1.5, а не 1 (2 кажется слишком много).
В общем, как и с любыми человеческими данными, все сложно, так что относитесь к дальнейшему с толикой сомнения (и презрения). Любая вариация в этих пунктах даст совершенно другой результат.
Рекордсмен — это w /ˈdəbəɫju/, 7 звуков на 1 букву! Но, увы, тоже не считается. Слова, у которых разница с произношением получилась больше длины и больше других слов такой же длины:
- длина 2: of /ˈəv/
- длина 3: eye /ˈaɪ/
- длина 4: cece /ˈsis/, nazi /ˈnɑtsi/, phew /ˈfju/
- длина 5: cycle /ˈsaɪkəɫ/, exalt /ɪɡˈzɔɫt/
- длина 6: arouse /ɝˈaʊz/, cesium /ˈsiziəm/, fiance /ˌfiˌɑnˈseɪ/, physio /ˈfɪzioʊ/
- длина 7: exhaust /ɪɡˈzɔst/, neonazi /ˌnioʊˈnɑtsi/
- длина 8: outhouse /ˈaʊtˌhaʊs/
- длина 9: xylophone /ˈzaɪɫəˌfoʊn/
- длина 10: exhaustion /ɪɡˈzɔstʃən/
Увы, особо впечатляющих слов не нашлось. Cycle /ˈsaɪkəɫ/ почтил память бикукле (хотя в альфа-версии проигрывал genie /ˈdʒini/).
Чтобы запомнить эти слова, можно воспользоваться мнемоникой (которую не смог сочинить ChatGPT):
Cesium xylophone aroused exhausted nazi physio’s eye:
- Phew, exhaustion… Exalt neonazi fiance of cece outhouse!
Отдельно отмечу bourgeoisie /ˌbʊɹʒˌwɑˈzi/ (нетрудно догадаться, из какого языка оно пришло) и слова подлиннее, хотя бы за то, что это длинные настоящие слова: tracheophyte /ˈtɹeɪkiəfaɪt/, inexhaustible /ˌɪnɪɡˈzɔstəbəɫ/, concessionaire /kənˌsɛʃəˈnɛɹ/, phosphorescence /ˌfɑsfɝˈɛsəns/, anesthesiologist /ˌænəsˌθiziˈɑɫədʒəst/, australopithecine /ɔˌstɹeɪɫoʊˈpɪθəˌsaɪn/, conceptualization /kənˈsɛptʃwəɫɪˌzeɪʃən/, parliamentarianism /ˌpɑɹɫəmənˈtɛɹiənɪzm/, counterintelligence /ˌkaʊntɝɪnˈtɛɫɪdʒəns/, counterrevolutionary /ˌkaʊntɝɹɛvəˈɫuʃəˌnɛɹi/, deinstitutionalization /ˌdiˌɪnstɪˌtuʃənəɫəˈzeɪʃən/, antidisestablishmentarianism /ˌæntaɪˌdɪsəˌstæbɫɪʃmənˈtɛɹiəˌnɪzəm/.
А вообще не пытайтесь произносить английские слова — все равно они не соответствуют написанию. И тем более не пытайтесь обрабатывать что-то, связанное с произношением — это прямой путь в дурку.
Что внутри у мягкой ссылки
На примере ext4. Краткая справка: с каждым логическим файлом ассоциирован inode, который хранит его метаданные: права доступа, атрибуты, указатели на блоки с данными и т.п.
Признак того, что файл является символической ссылкой, хранится поле mode в inode: у обычных файлов это 010xxxx (в 8-ричной системе; xxxx — это unix-права вместе со sticky битом), а у символических ссылок — 012xxxx. А путь ссылки хранится в данных. Т.е. ссылка — это просто текстовый файл, у которого выставлен специальный флаг.
Но есть нюанс. Подобные ссылки будут не очень быстрыми, т.к. надо сначала прочитать метаданные, а потом пройти по указателям на блоки и прочитать собственно путь. Поэтому придумали оптимизацию, чтобы хранить путь прямо в метаданных, если он достаточно короткий (меньше 60 символов). Подобное можно применить и к обычным маленьким файлам, если файловая система была создана с флагом inline_data.
Перейдем к практике.

Для безопасного эксперимента можно воспользоваться утилитой debugfs. Создадим файл с ФС:
dd if=/dev/zero of=ext4.img bs=1M count=100
mkfs.ext4 ext4.img -O inline_data
mkdir mnt
sudo mount ext4.img mnt
Заполним данными
sudo echo -n "some text" | sudo tee mnt/original.txt
sudo ln -s original.txt mnt/short_link
sudo ln -s very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_long mnt/long_link
sudo echo -n "original.txt" | sudo tee mnt/manual_link
Получили такое в ls -lF mnt:
lrwxrwxrwx 1 long_link -> very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_long
drwx------ 2 lost+found/
-rw-r--r-- 1 manual_link
-rw-r--r-- 1 original.txt
lrwxrwxrwx 1 short_link -> original.txt
Отмонтируем ФС и откроем debugfs:
sudo umount mnt
debugfs -w ext4.img
Начнем с простого — с длинной ссылки. Ей достаточно поменять mode:
debug_fs: mi long_link
Mode [0120777] 0100777
...
У короткой ссылки надо поменять mode, выставить флаг того, что файл содержит данные в метаданных и добавить расширенный атрибут, что это именно данные:
debugfs: mi short_link
Mode [0120777] 0100777
...
File flags [0x0] 0x10000000
...
debugfs: ea_set short_link system.data 0
Наконец, превратим текстовый файл в ссылку:
debugfs: mi manual_link
Mode [0100644] 0120777
...
File flags [0x10000000] 0x0
...
Сохраняем с помощью Ctrl + D и монтируем sudo mount ext4.img mnt. Вывод ls -lF mnt:
-rwxrwxrwx long_link*
drwx------ lost+found/
lrwxrwxrwx manual_link -> original.txt
-rw-r--r-- original.txt
-rwxrwxrwx short_link*
Содержимое ссылок:
$ cat mnt/long_link; echo
very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_very_long
$ cat mnt/short_link; echo
original.txt
$ readlink mnt/manual_link
original.txt
$ cat mnt/manual_link; echo
some text
Теперь вы знаете простой способ, как сделать символическую ссылку :)
